 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniGen-1.5: Enhancing Image Generation and Editing through Reward Unification in Reinforcement Learning
Nov 18, 2025We present UniGen-1.5, a unified multimodal large language model (MLLM) for advanced image understanding, generation and editing. Building upon UniGen, we comprehensively enhance the model architecture and training pipeline to strengthen the image understanding and generation capabilities while unlocking strong image editing ability. Especially, we propose a unified Reinforcement Learning (RL) strategy that improves both image generation and image editing jointly via shared reward models. To further enhance image editing performance, we propose a light Edit Instruction Alignment stage that significantly improves the editing instruction comprehension that is essential for the success of the RL training. Experimental results show that UniGen-1.5 demonstrates competitive understanding and generation performance. Specifically, UniGen-1.5 achieves 0.89 and 4.31 overall scores on GenEval and ImgEdit that surpass the state-of-the-art models such as BAGEL and reaching performance comparable to proprietary models such as GPT-Image-1.
HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer
May 28, 2025Recent advancements in image generative foundation models have prioritized quality improvements but often at the cost of increased computational complexity and inference latency. To address this critical trade-off, we introduce HiDream-I1, a new open-source image generative foundation model with 17B parameters that achieves state-of-the-art image generation quality within seconds. HiDream-I1 is constructed with a new sparse Diffusion Transformer (DiT) structure. Specifically, it starts with a dual-stream decoupled design of sparse DiT with dynamic Mixture-of-Experts (MoE) architecture, in which two separate encoders are first involved to independently process image and text tokens. Then, a single-stream sparse DiT structure with dynamic MoE architecture is adopted to trigger multi-model interaction for image generation in a cost-efficient manner. To support flexiable accessibility with varied model capabilities, we provide HiDream-I1 in three variants: HiDream-I1-Full, HiDream-I1-Dev, and HiDream-I1-Fast. Furthermore, we go beyond the typical text-to-image generation and remould HiDream-I1 with additional image conditions to perform precise, instruction-based editing on given images, yielding a new instruction-based image editing model namely HiDream-E1. Ultimately, by integrating text-to-image generation and instruction-based image editing, HiDream-I1 evolves to form a comprehensive image agent (HiDream-A1) capable of fully interactive image creation and refinement. To accelerate multi-modal AIGC research, we have open-sourced all the codes and model weights of HiDream-I1-Full, HiDream-I1-Dev, HiDream-I1-Fast, HiDream-E1 through our project websites: https://github.com/HiDream-ai/HiDream-I1 and https://github.com/HiDream-ai/HiDream-E1. All features can be directly experienced via https://vivago.ai/studio.
UniGen: Enhanced Training & Test-Time Strategies for Unified Multimodal Understanding and Generation
May 20, 2025We introduce UniGen, a unified multimodal large language model (MLLM) capable of image understanding and generation. We study the full training pipeline of UniGen from a data-centric perspective, including multi-stage pre-training, supervised fine-tuning, and direct preference optimization. More importantly, we propose a new Chain-of-Thought Verification (CoT-V) strategy for test-time scaling, which significantly boosts UniGen's image generation quality using a simple Best-of-N test-time strategy. Specifically, CoT-V enables UniGen to act as both image generator and verifier at test time, assessing the semantic alignment between a text prompt and its generated image in a step-by-step CoT manner. Trained entirely on open-source datasets across all stages, UniGen achieves state-of-the-art performance on a range of image understanding and generation benchmarks, with a final score of 0.78 on GenEval and 85.19 on DPG-Bench. Through extensive ablation studies, our work provides actionable insights and addresses key challenges in the full life cycle of building unified MLLMs, contributing meaningful directions to the future research.
Multi-Modality Driven LoRA for Adverse Condition Depth Estimation
Dec 28, 2024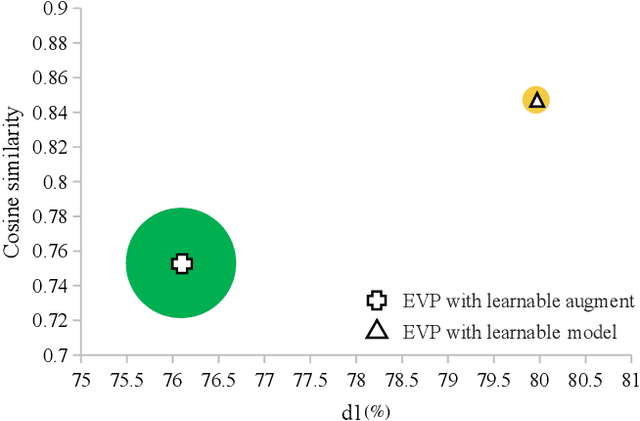
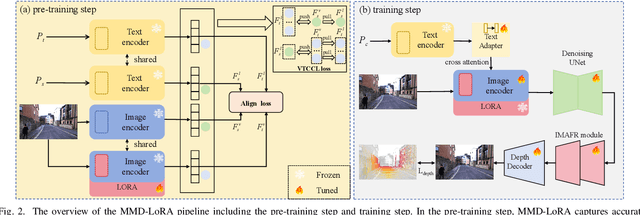
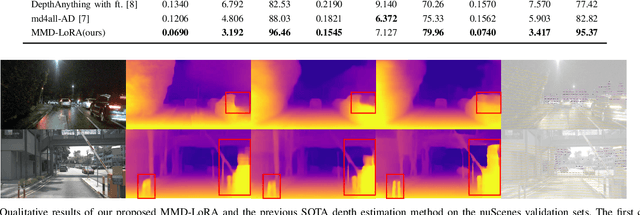

The autonomous driving community is increasingly focused on addressing corner case problems, particularly those related to ensuring driving safety under adverse conditions (e.g., nighttime, fog, rain). To this end, the task of Adverse Condition Depth Estimation (ACDE) has gained significant attention. Previous approaches in ACDE have primarily relied on generative models, which necessitate additional target images to convert the sunny condition into adverse weather, or learnable parameters for feature augmentation to adapt domain gaps, resulting in increased model complexity and tuning efforts. Furthermore, unlike CLIP-based methods where textual and visual features have been pre-aligned, depth estimation models lack sufficient alignment between multimodal features, hindering coherent understanding under adverse conditions. To address these limitations, we propose Multi-Modality Driven LoRA (MMD-LoRA), which leverages low-rank adaptation matrices for efficient fine-tuning from source-domain to target-domain. It consists of two core components: Prompt Driven Domain Alignment (PDDA) and Visual-Text Consistent Contrastive Learning(VTCCL). During PDDA, the image encoder with MMD-LoRA generates target-domain visual representations, supervised by alignment loss that the source-target difference between language and image should be equal. Meanwhile, VTCCL bridges the gap between textual features from CLIP and visual features from diffusion model, pushing apart different weather representations (vision and text) and bringing together similar ones. Through extensive experiments, the proposed method achieves state-of-the-art performance on the nuScenes and Oxford RobotCar datasets, underscoring robustness and efficiency in adapting to varied adverse environments.
REDUCIO! Generating 1024$\times$1024 Video within 16 Seconds using Extremely Compressed Motion Latents
Nov 20, 2024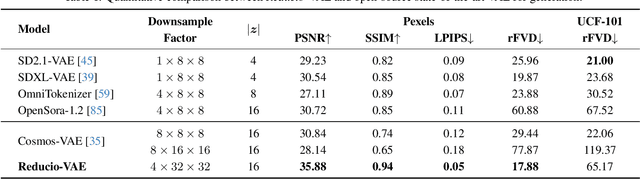
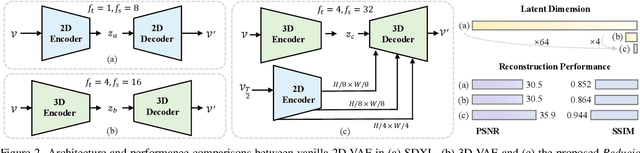

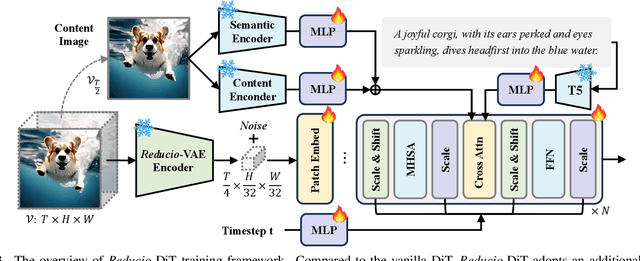
Commercial video generation models have exhibited realistic, high-fidelity results but are still restricted to limited access. One crucial obstacle for large-scale applications is the expensive training and inference cost. In this paper, we argue that videos contain much more redundant information than images, thus can be encoded by very few motion latents based on a content image. Towards this goal, we design an image-conditioned VAE to encode a video to an extremely compressed motion latent space. This magic Reducio charm enables 64x reduction of latents compared to a common 2D VAE, without sacrificing the quality. Training diffusion models on such a compact representation easily allows for generating 1K resolution videos. We then adopt a two-stage video generation paradigm, which performs text-to-image and text-image-to-video sequentially. Extensive experiments show that our Reducio-DiT achieves strong performance in evaluation, though trained with limited GPU resources. More importantly, our method significantly boost the efficiency of video LDMs both in training and inference. We train Reducio-DiT in around 3.2K training hours in total and generate a 16-frame 1024*1024 video clip within 15.5 seconds on a single A100 GPU. Code released at https://github.com/microsoft/Reducio-VAE .
DeepStack: Deeply Stacking Visual Tokens is Surprisingly Simple and Effective for LMMs
Jun 06, 2024Most large multimodal models (LMMs) are implemented by feeding visual tokens as a sequence into the first layer of a large language model (LLM). The resulting architecture is simple but significantly increases computation and memory costs, as it has to handle a large number of additional tokens in its input layer. This paper presents a new architecture DeepStack for LMMs. Considering $N$ layers in the language and vision transformer of LMMs, we stack the visual tokens into $N$ groups and feed each group to its aligned transformer layer \textit{from bottom to top}. Surprisingly, this simple method greatly enhances the power of LMMs to model interactions among visual tokens across layers but with minimal additional cost. We apply DeepStack to both language and vision transformer in LMMs, and validate the effectiveness of DeepStack LMMs with extensive empirical results. Using the same context length, our DeepStack 7B and 13B parameters surpass their counterparts by \textbf{2.7} and \textbf{2.9} on average across \textbf{9} benchmarks, respectively. Using only one-fifth of the context length, DeepStack rivals closely to the counterparts that use the full context length. These gains are particularly pronounced on high-resolution tasks, e.g., \textbf{4.2}, \textbf{11.0}, and \textbf{4.0} improvements on TextVQA, DocVQA, and InfoVQA compared to LLaVA-1.5-7B, respectively. We further apply DeepStack to vision transformer layers, which brings us a similar amount of improvements, \textbf{3.8} on average compared with LLaVA-1.5-7B.
S3-SLAM: Sparse Tri-plane Encoding for Neural Implicit SLAM
Apr 28, 2024With the emergence of Neural Radiance Fields (NeRF), neural implicit representations have gained widespread applications across various domains, including simultaneous localization and mapping. However, current neural implicit SLAM faces a challenging trade-off problem between performance and the number of parameters. To address this problem, we propose sparse tri-plane encoding, which efficiently achieves scene reconstruction at resolutions up to 512 using only 2~4% of the commonly used tri-plane parameters (reduced from 100MB to 2~4MB). On this basis, we design S3-SLAM to achieve rapid and high-quality tracking and mapping through sparsifying plane parameters and integrating orthogonal features of tri-plane. Furthermore, we develop hierarchical bundle adjustment to achieve globally consistent geometric structures and reconstruct high-resolution appearance. Experimental results demonstrate that our approach achieves competitive tracking and scene reconstruction with minimal parameters on three datasets. Source code will soon be available.
A Practical Large-Scale Roadside Multi-View Multi-Sensor Spatial Synchronization Framework for Intelligent Transportation Systems
Nov 04, 2023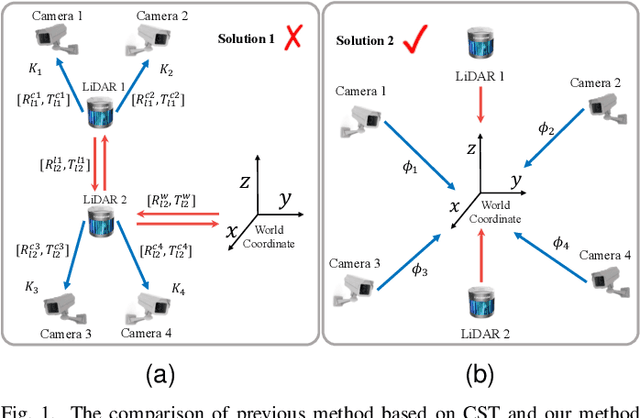
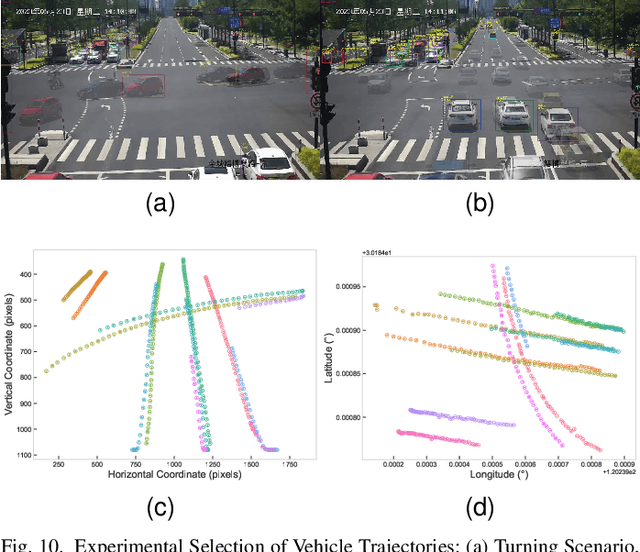
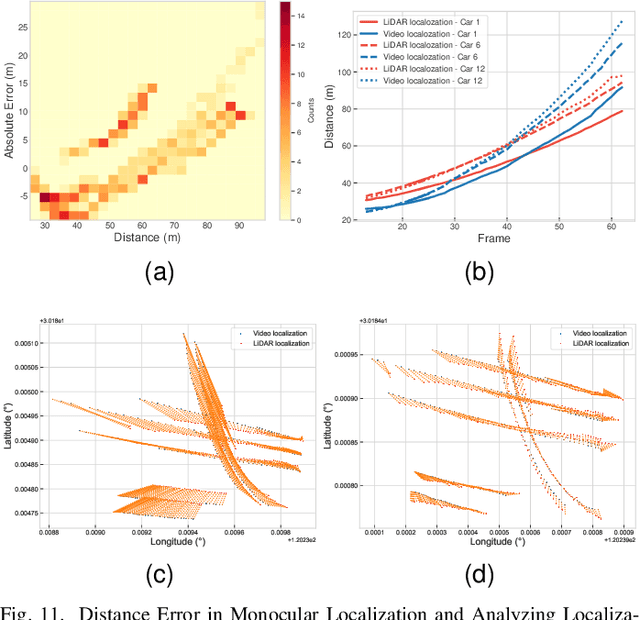
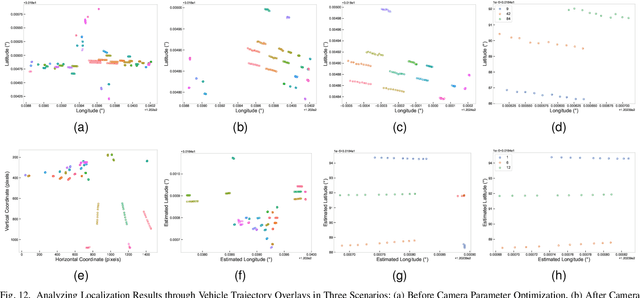
Spatial synchronization in roadside scenarios is essential for integrating data from multiple sensors at different locations. Current methods using cascading spatial transformation (CST) often lead to cumulative errors in large-scale deployments. Manual camera calibration is insufficient and requires extensive manual work, and existing methods are limited to controlled or single-view scenarios. To address these challenges, our research introduces a parallel spatial transformation (PST)-based framework for large-scale, multi-view, multi-sensor scenarios. PST parallelizes sensor coordinate system transformation, reducing cumulative errors. We incorporate deep learning for precise roadside monocular global localization, reducing manual work. Additionally, we use geolocation cues and an optimization algorithm for improved synchronization accuracy. Our framework has been tested in real-world scenarios, outperforming CST-based methods. It significantly enhances large-scale roadside multi-perspective, multi-sensor spatial synchronization, reducing deployment costs.
UniQuadric: A SLAM Backend for Unknown Rigid Object 3D Tracking and Light-Weight Modeling
Oct 02, 2023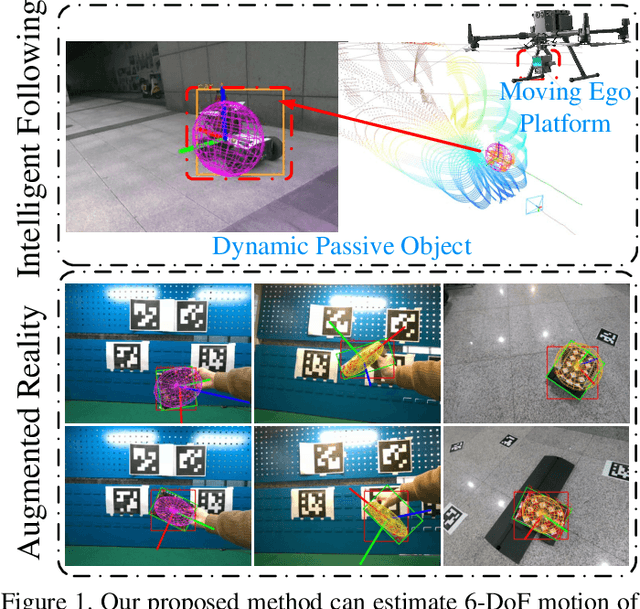



Tracking and modeling unknown rigid objects in the environment play a crucial role in autonomous unmanned systems and virtual-real interactive applications. However, many existing Simultaneous Localization, Mapping and Moving Object Tracking (SLAMMOT) methods focus solely on estimating specific object poses and lack estimation of object scales and are unable to effectively track unknown objects. In this paper, we propose a novel SLAM backend that unifies ego-motion tracking, rigid object motion tracking, and modeling within a joint optimization framework. In the perception part, we designed a pixel-level asynchronous object tracker (AOT) based on the Segment Anything Model (SAM) and DeAOT, enabling the tracker to effectively track target unknown objects guided by various predefined tasks and prompts. In the modeling part, we present a novel object-centric quadric parameterization to unify both static and dynamic object initialization and optimization. Subsequently, in the part of object state estimation, we propose a tightly coupled optimization model for object pose and scale estimation, incorporating hybrids constraints into a novel dual sliding window optimization framework for joint estimation. To our knowledge, we are the first to tightly couple object pose tracking with light-weight modeling of dynamic and static objects using quadric. We conduct qualitative and quantitative experiments on simulation datasets and real-world datasets, demonstrating the state-of-the-art robustness and accuracy in motion estimation and modeling. Our system showcases the potential application of object perception in complex dynamic scenes.
ResFormer: Scaling ViTs with Multi-Resolution Training
Dec 01, 2022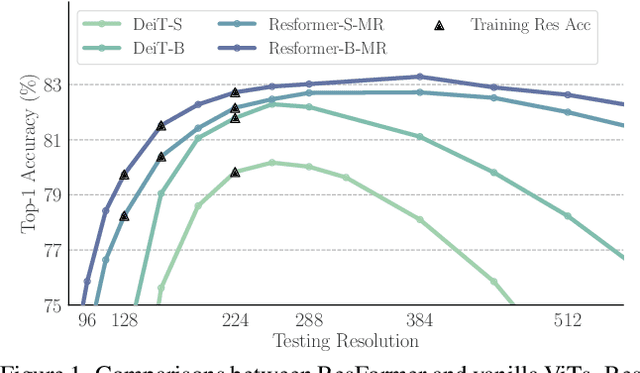
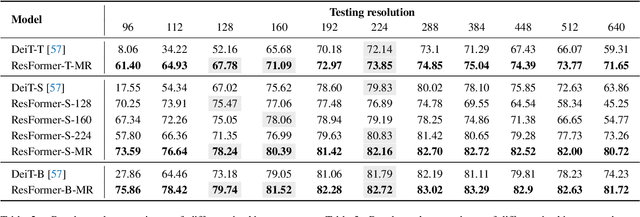
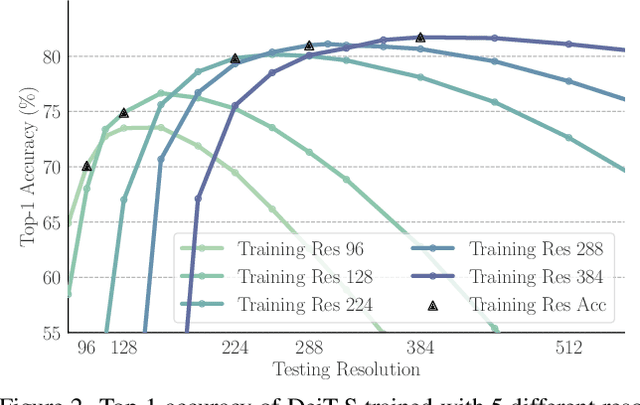
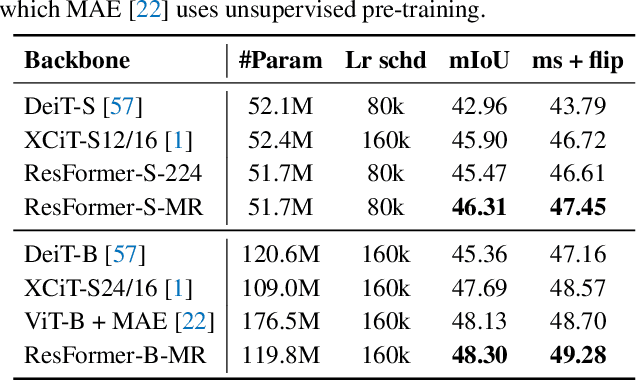
Vision Transformers (ViTs) have achieved overwhelming success, yet they suffer from vulnerable resolution scalability, i.e., the performance drops drastically when presented with input resolutions that are unseen during training. We introduce, ResFormer, a framework that is built upon the seminal idea of multi-resolution training for improved performance on a wide spectrum of, mostly unseen, testing resolutions. In particular, ResFormer operates on replicated images of different resolutions and enforces a scale consistency loss to engage interactive information across different scales. More importantly, to alternate among varying resolutions, we propose a global-local positional embedding strategy that changes smoothly conditioned on input sizes. This allows ResFormer to cope with novel resolutions effectively. We conduct extensive experiments for image classification on ImageNet. The results provide strong quantitative evidence that ResFormer has promising scaling abilities towards a wide range resolutions. For instance, ResFormer-B-MR achieves a Top-1 accuracy of 75.86% and 81.72% when evaluated on relatively low and high resolutions respectively (i.e., 96 and 640), which are 48% and 7.49% better than DeiT-B. We also demonstrate, among other things, ResFormer is flexible and can be easily extended to semantic segmentation and video action recognition.