 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANO: A Principled Approach to Robust Policy Optimization
May 06, 2026Proximal Policy Optimization (PPO) dominates reinforcement learning and LLM alignment but relies on a "hard clipping" mechanism that discards valuable gradients. Conversely, unconstrained methods like SPO expose the optimization to unbounded updates, causing severe instability and policy collapse during extreme outlier encounters. To resolve this dilemma, we introduce a principled design space for policy optimization, demonstrating that a robust estimator must inherently suppress outliers while maintaining a smooth restoration force. Guided by these geometric principles, we derive Anchored Neighborhood Optimization (ANO), a novel method that seamlessly replaces hard clipping with a redescending gradient mechanism. Extensive evaluations demonstrate ANO's empirical superiority across diverse domains. In continuous (MuJoCo) and discrete (Atari) control, ANO establishes a robust state-of-the-art, uniquely preventing policy collapse even under highly aggressive learning rates ($1 \times 10^{-3}$). Furthermore, in LLM alignment (RLHF), ANO explicitly eliminates the catastrophic KL divergence explosion inherent to unconstrained methods, dominating PPO, SPO, and GRPO in head-to-head win rates.
Anon: Extrapolating Adaptivity Beyond SGD and Adam
May 06, 2026Adaptive optimizers such as Adam have achieved great success in training large-scale models like large language models and diffusion models. However, they often generalize worse than non-adaptive methods, such as SGD on classical architectures like CNNs. We identify a key cause of this performance gap: adaptivity in pre-conditioners, which limits the optimizer's ability to adapt to diverse optimization landscapes. To address this, we propose Anon (Adaptivity Non-restricted Optimizer with Novel convergence technique), a novel optimizer with continuously tunable adaptivity in R, allowing it to interpolate between SGD-like and Adam-like behaviors and even extrapolate beyond both. To ensure convergence across the entire adaptivity spectrum, we introduce incremental delay update (IDU), a novel mechanism that is more flexible than AMSGrad's hard max-tracking strategy and enhances robustness to gradient noise. We theoretically establish convergence guarantees under both convex and non-convex settings. Empirically, Anon consistently outperforms state-of-the-art optimizers on representative image classification, diffusion, and language modeling tasks. These results demonstrate that adaptivity can serve as a valuable tunable design principle, and Anon provides the first unified and reliable framework capable of bridging the gap between classical and modern optimizers and surpassing their advantageous properties.
VTFusion: A Vision-Text Multimodal Fusion Network for Few-Shot Anomaly Detection
Jan 23, 2026Few-Shot Anomaly Detection (FSAD) has emerged as a critical paradigm for identifying irregularities using scarce normal references. While recent methods have integrated textual semantics to complement visual data, they predominantly rely on features pre-trained on natural scenes, thereby neglecting the granular, domain-specific semantics essential for industrial inspection. Furthermore, prevalent fusion strategies often resort to superficial concatenation, failing to address the inherent semantic misalignment between visual and textual modalities, which compromises robustness against cross-modal interference. To bridge these gaps, this study proposes VTFusion, a vision-text multimodal fusion framework tailored for FSAD. The framework rests on two core designs. First, adaptive feature extractors for both image and text modalities are introduced to learn task-specific representations, bridging the domain gap between pre-trained models and industrial data; this is further augmented by generating diverse synthetic anomalies to enhance feature discriminability. Second, a dedicated multimodal prediction fusion module is developed, comprising a fusion block that facilitates rich cross-modal information exchange and a segmentation network that generates refined pixel-level anomaly maps under multimodal guidance. VTFusion significantly advances FSAD performance, achieving image-level AUROCs of 96.8% and 86.2% in the 2-shot scenario on the MVTec AD and VisA datasets, respectively. Furthermore, VTFusion achieves an AUPRO of 93.5% on a real-world dataset of industrial automotive plastic parts introduced in this paper, further demonstrating its practical applicability in demanding industrial scenarios.
Corrective Diffusion Language Models
Dec 17, 2025
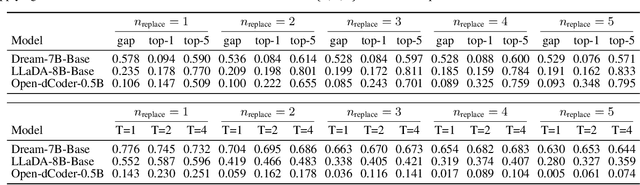
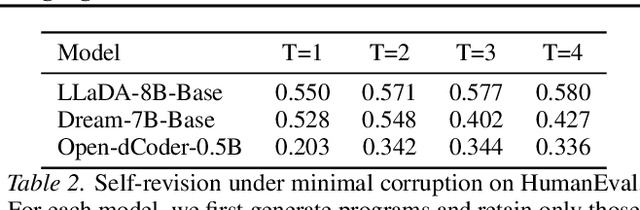
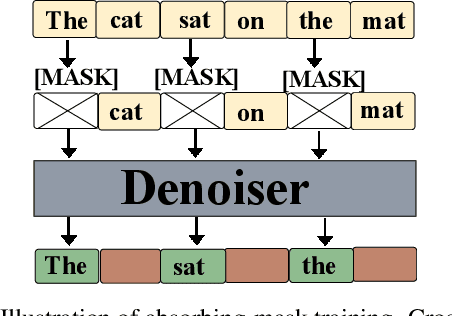
Diffusion language models are structurally well-suited for iterative error correction, as their non-causal denoising dynamics allow arbitrary positions in a sequence to be revised. However, standard masked diffusion language model (MDLM) training fails to reliably induce this behavior, as models often cannot identify unreliable tokens in a complete input, rendering confidence-guided refinement ineffective. We study corrective behavior in diffusion language models, defined as the ability to assign lower confidence to incorrect tokens and iteratively refine them while preserving correct content. We show that this capability is not induced by conventional masked diffusion objectives and propose a correction-oriented post-training principle that explicitly supervises visible incorrect tokens, enabling error-aware confidence and targeted refinement. To evaluate corrective behavior, we introduce the Code Revision Benchmark (CRB), a controllable and executable benchmark for assessing error localization and in-place correction. Experiments on code revision tasks and controlled settings demonstrate that models trained with our approach substantially outperform standard MDLMs in correction scenarios, while also improving pure completion performance. Our code is publicly available at https://github.com/zhangshuibai/CDLM.
FlashMesh: Faster and Better Autoregressive Mesh Synthesis via Structured Speculation
Nov 19, 2025Autoregressive models can generate high-quality 3D meshes by sequentially producing vertices and faces, but their token-by-token decoding results in slow inference, limiting practical use in interactive and large-scale applications. We present FlashMesh, a fast and high-fidelity mesh generation framework that rethinks autoregressive decoding through a predict-correct-verify paradigm. The key insight is that mesh tokens exhibit strong structural and geometric correlations that enable confident multi-token speculation. FlashMesh leverages this by introducing a speculative decoding scheme tailored to the commonly used hourglass transformer architecture, enabling parallel prediction across face, point, and coordinate levels. Extensive experiments show that FlashMesh achieves up to a 2 x speedup over standard autoregressive models while also improving generation fidelity. Our results demonstrate that structural priors in mesh data can be systematically harnessed to accelerate and enhance autoregressive generation.
LSS3D: Learnable Spatial Shifting for Consistent and High-Quality 3D Generation from Single-Image
Nov 15, 2025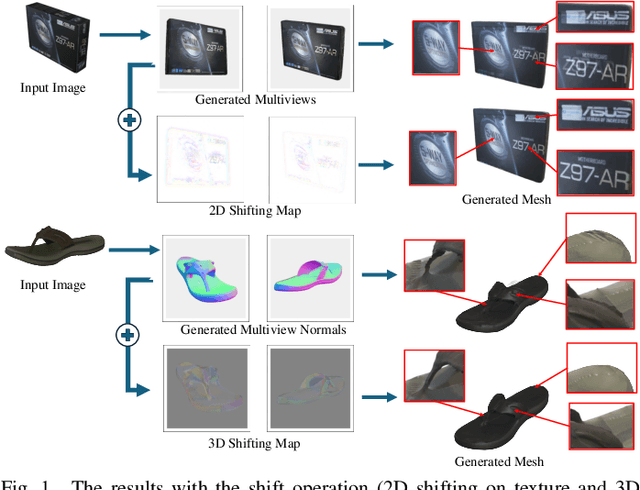
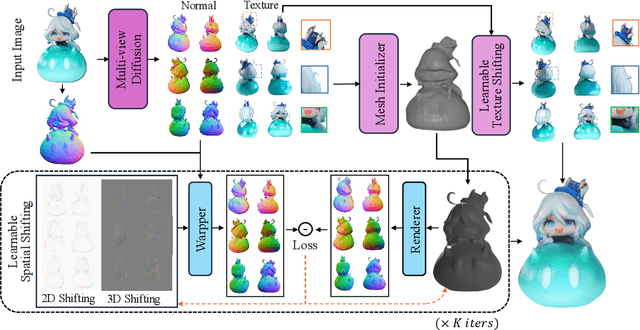

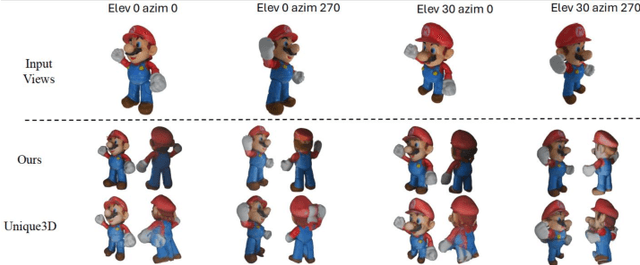
Recently, multi-view diffusion-based 3D generation methods have gained significant attention. However, these methods often suffer from shape and texture misalignment across generated multi-view images, leading to low-quality 3D generation results, such as incomplete geometric details and textural ghosting. Some methods are mainly optimized for the frontal perspective and exhibit poor robustness to oblique perspective inputs. In this paper, to tackle the above challenges, we propose a high-quality image-to-3D approach, named LSS3D, with learnable spatial shifting to explicitly and effectively handle the multiview inconsistencies and non-frontal input view. Specifically, we assign learnable spatial shifting parameters to each view, and adjust each view towards a spatially consistent target, guided by the reconstructed mesh, resulting in high-quality 3D generation with more complete geometric details and clean textures. Besides, we include the input view as an extra constraint for the optimization, further enhancing robustness to non-frontal input angles, especially for elevated viewpoint inputs. We also provide a comprehensive quantitative evaluation pipeline that can contribute to the community in performance comparisons. Extensive experiments demonstrate that our method consistently achieves leading results in both geometric and texture evaluation metrics across more flexible input viewpoints.
PartSAM: A Scalable Promptable Part Segmentation Model Trained on Native 3D Data
Sep 26, 2025Segmenting 3D objects into parts is a long-standing challenge in computer vision. To overcome taxonomy constraints and generalize to unseen 3D objects, recent works turn to open-world part segmentation. These approaches typically transfer supervision from 2D foundation models, such as SAM, by lifting multi-view masks into 3D. However, this indirect paradigm fails to capture intrinsic geometry, leading to surface-only understanding, uncontrolled decomposition, and limited generalization. We present PartSAM, the first promptable part segmentation model trained natively on large-scale 3D data. Following the design philosophy of SAM, PartSAM employs an encoder-decoder architecture in which a triplane-based dual-branch encoder produces spatially structured tokens for scalable part-aware representation learning. To enable large-scale supervision, we further introduce a model-in-the-loop annotation pipeline that curates over five million 3D shape-part pairs from online assets, providing diverse and fine-grained labels. This combination of scalable architecture and diverse 3D data yields emergent open-world capabilities: with a single prompt, PartSAM achieves highly accurate part identification, and in a Segment-Every-Part mode, it automatically decomposes shapes into both surface and internal structures. Extensive experiments show that PartSAM outperforms state-of-the-art methods by large margins across multiple benchmarks, marking a decisive step toward foundation models for 3D part understanding. Our code and model will be released soon.
HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer
May 28, 2025Recent advancements in image generative foundation models have prioritized quality improvements but often at the cost of increased computational complexity and inference latency. To address this critical trade-off, we introduce HiDream-I1, a new open-source image generative foundation model with 17B parameters that achieves state-of-the-art image generation quality within seconds. HiDream-I1 is constructed with a new sparse Diffusion Transformer (DiT) structure. Specifically, it starts with a dual-stream decoupled design of sparse DiT with dynamic Mixture-of-Experts (MoE) architecture, in which two separate encoders are first involved to independently process image and text tokens. Then, a single-stream sparse DiT structure with dynamic MoE architecture is adopted to trigger multi-model interaction for image generation in a cost-efficient manner. To support flexiable accessibility with varied model capabilities, we provide HiDream-I1 in three variants: HiDream-I1-Full, HiDream-I1-Dev, and HiDream-I1-Fast. Furthermore, we go beyond the typical text-to-image generation and remould HiDream-I1 with additional image conditions to perform precise, instruction-based editing on given images, yielding a new instruction-based image editing model namely HiDream-E1. Ultimately, by integrating text-to-image generation and instruction-based image editing, HiDream-I1 evolves to form a comprehensive image agent (HiDream-A1) capable of fully interactive image creation and refinement. To accelerate multi-modal AIGC research, we have open-sourced all the codes and model weights of HiDream-I1-Full, HiDream-I1-Dev, HiDream-I1-Fast, HiDream-E1 through our project websites: https://github.com/HiDream-ai/HiDream-I1 and https://github.com/HiDream-ai/HiDream-E1. All features can be directly experienced via https://vivago.ai/studio.
Visual Anomaly Detection under Complex View-Illumination Interplay: A Large-Scale Benchmark
May 16, 2025The practical deployment of Visual Anomaly Detection (VAD) systems is hindered by their sensitivity to real-world imaging variations, particularly the complex interplay between viewpoint and illumination which drastically alters defect visibility. Current benchmarks largely overlook this critical challenge. We introduce Multi-View Multi-Illumination Anomaly Detection (M2AD), a new large-scale benchmark comprising 119,880 high-resolution images designed explicitly to probe VAD robustness under such interacting conditions. By systematically capturing 999 specimens across 10 categories using 12 synchronized views and 10 illumination settings (120 configurations total), M2AD enables rigorous evaluation. We establish two evaluation protocols: M2AD-Synergy tests the ability to fuse information across diverse configurations, and M2AD-Invariant measures single-image robustness against realistic view-illumination effects. Our extensive benchmarking shows that state-of-the-art VAD methods struggle significantly on M2AD, demonstrating the profound challenge posed by view-illumination interplay. This benchmark serves as an essential tool for developing and validating VAD methods capable of overcoming real-world complexities. Our full dataset and test suite will be released at https://hustcyq.github.io/M2AD to facilitate the field.
FreeEnhance: Tuning-Free Image Enhancement via Content-Consistent Noising-and-Denoising Process
Sep 11, 2024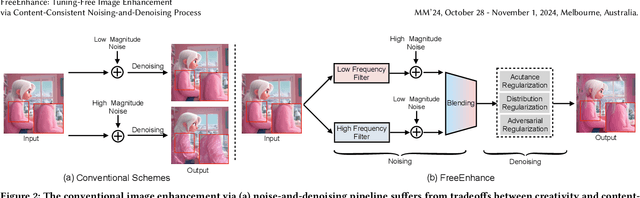
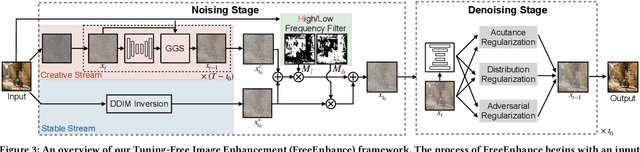
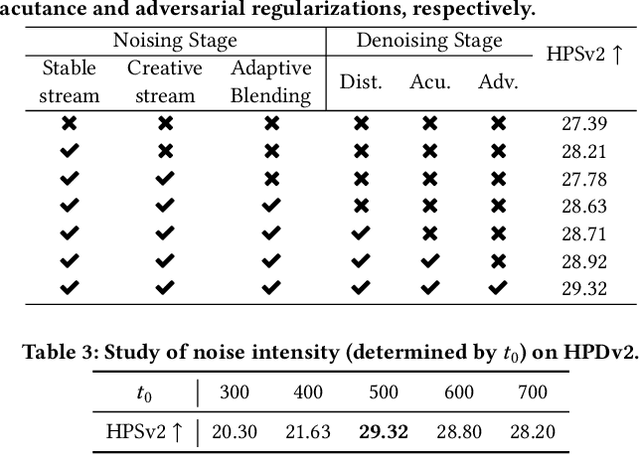

The emergence of text-to-image generation models has led to the recognition that image enhancement, performed as post-processing, would significantly improve the visual quality of the generated images. Exploring diffusion models to enhance the generated images nevertheless is not trivial and necessitates to delicately enrich plentiful details while preserving the visual appearance of key content in the original image. In this paper, we propose a novel framework, namely FreeEnhance, for content-consistent image enhancement using the off-the-shelf image diffusion models. Technically, FreeEnhance is a two-stage process that firstly adds random noise to the input image and then capitalizes on a pre-trained image diffusion model (i.e., Latent Diffusion Models) to denoise and enhance the image details. In the noising stage, FreeEnhance is devised to add lighter noise to the region with higher frequency to preserve the high-frequent patterns (e.g., edge, corner) in the original image. In the denoising stage, we present three target properties as constraints to regularize the predicted noise, enhancing images with high acutance and high visual quality. Extensive experiments conducted on the HPDv2 dataset demonstrate that our FreeEnhance outperforms the state-of-the-art image enhancement models in terms of quantitative metrics and human preference. More remarkably, FreeEnhance also shows higher human preference compared to the commercial image enhancement solution of Magnific AI.