 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Rotation-only Imaging Geometry: Rotation Estimation
Nov 16, 2025Structure from Motion (SfM) is a critical task in computer vision, aiming to recover the 3D scene structure and camera motion from a sequence of 2D images. The recent pose-only imaging geometry decouples 3D coordinates from camera poses and demonstrates significantly better SfM performance through pose adjustment. Continuing the pose-only perspective, this paper explores the critical relationship between the scene structures, rotation and translation. Notably, the translation can be expressed in terms of rotation, allowing us to condense the imaging geometry representation onto the rotation manifold. A rotation-only optimization framework based on reprojection error is proposed for both two-view and multi-view scenarios. The experiment results demonstrate superior accuracy and robustness performance over the current state-of-the-art rotation estimation methods, even comparable to multiple bundle adjustment iteration results. Hopefully, this work contributes to even more accurate, efficient and reliable 3D visual computing.
Generic Calibration: Pose Ambiguity/Linear Solution and Parametric-hybrid Pipeline
Aug 10, 2025Offline camera calibration techniques typically employ parametric or generic camera models. Selecting parametric models relies heavily on user experience, and an inappropriate camera model can significantly affect calibration accuracy. Meanwhile, generic calibration methods involve complex procedures and cannot provide traditional intrinsic parameters. This paper reveals a pose ambiguity in the pose solutions of generic calibration methods that irreversibly impacts subsequent pose estimation. A linear solver and a nonlinear optimization are proposed to address this ambiguity issue. Then a global optimization hybrid calibration method is introduced to integrate generic and parametric models together, which improves extrinsic parameter accuracy of generic calibration and mitigates overfitting and numerical instability in parametric calibration. Simulation and real-world experimental results demonstrate that the generic-parametric hybrid calibration method consistently excels across various lens types and noise contamination, hopefully serving as a reliable and accurate solution for camera calibration in complex scenarios.
PROTOCOL: Partial Optimal Transport-enhanced Contrastive Learning for Imbalanced Multi-view Clustering
Jun 14, 2025While contrastive multi-view clustering has achieved remarkable success, it implicitly assumes balanced class distribution. However, real-world multi-view data primarily exhibits class imbalance distribution. Consequently, existing methods suffer performance degradation due to their inability to perceive and model such imbalance. To address this challenge, we present the first systematic study of imbalanced multi-view clustering, focusing on two fundamental problems: i. perceiving class imbalance distribution, and ii. mitigating representation degradation of minority samples. We propose PROTOCOL, a novel PaRtial Optimal TranspOrt-enhanced COntrastive Learning framework for imbalanced multi-view clustering. First, for class imbalance perception, we map multi-view features into a consensus space and reformulate the imbalanced clustering as a partial optimal transport (POT) problem, augmented with progressive mass constraints and weighted KL divergence for class distributions. Second, we develop a POT-enhanced class-rebalanced contrastive learning at both feature and class levels, incorporating logit adjustment and class-sensitive learning to enhance minority sample representations. Extensive experiments demonstrate that PROTOCOL significantly improves clustering performance on imbalanced multi-view data, filling a critical research gap in this field.
HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer
May 28, 2025Recent advancements in image generative foundation models have prioritized quality improvements but often at the cost of increased computational complexity and inference latency. To address this critical trade-off, we introduce HiDream-I1, a new open-source image generative foundation model with 17B parameters that achieves state-of-the-art image generation quality within seconds. HiDream-I1 is constructed with a new sparse Diffusion Transformer (DiT) structure. Specifically, it starts with a dual-stream decoupled design of sparse DiT with dynamic Mixture-of-Experts (MoE) architecture, in which two separate encoders are first involved to independently process image and text tokens. Then, a single-stream sparse DiT structure with dynamic MoE architecture is adopted to trigger multi-model interaction for image generation in a cost-efficient manner. To support flexiable accessibility with varied model capabilities, we provide HiDream-I1 in three variants: HiDream-I1-Full, HiDream-I1-Dev, and HiDream-I1-Fast. Furthermore, we go beyond the typical text-to-image generation and remould HiDream-I1 with additional image conditions to perform precise, instruction-based editing on given images, yielding a new instruction-based image editing model namely HiDream-E1. Ultimately, by integrating text-to-image generation and instruction-based image editing, HiDream-I1 evolves to form a comprehensive image agent (HiDream-A1) capable of fully interactive image creation and refinement. To accelerate multi-modal AIGC research, we have open-sourced all the codes and model weights of HiDream-I1-Full, HiDream-I1-Dev, HiDream-I1-Fast, HiDream-E1 through our project websites: https://github.com/HiDream-ai/HiDream-I1 and https://github.com/HiDream-ai/HiDream-E1. All features can be directly experienced via https://vivago.ai/studio.
Creatively Upscaling Images with Global-Regional Priors
May 22, 2025Contemporary diffusion models show remarkable capability in text-to-image generation, while still being limited to restricted resolutions (e.g., 1,024 X 1,024). Recent advances enable tuning-free higher-resolution image generation by recycling pre-trained diffusion models and extending them via regional denoising or dilated sampling/convolutions. However, these models struggle to simultaneously preserve global semantic structure and produce creative regional details in higher-resolution images. To address this, we present C-Upscale, a new recipe of tuning-free image upscaling that pivots on global-regional priors derived from given global prompt and estimated regional prompts via Multimodal LLM. Technically, the low-frequency component of low-resolution image is recognized as global structure prior to encourage global semantic consistency in high-resolution generation. Next, we perform regional attention control to screen cross-attention between global prompt and each region during regional denoising, leading to regional attention prior that alleviates object repetition issue. The estimated regional prompts containing rich descriptive details further act as regional semantic prior to fuel the creativity of regional detail generation. Both quantitative and qualitative evaluations demonstrate that our C-Upscale manages to generate ultra-high-resolution images (e.g., 4,096 X 4,096 and 8,192 X 8,192) with higher visual fidelity and more creative regional details.
An Immediate Update Strategy of Multi-State Constraint Kalman Filter
Nov 04, 2024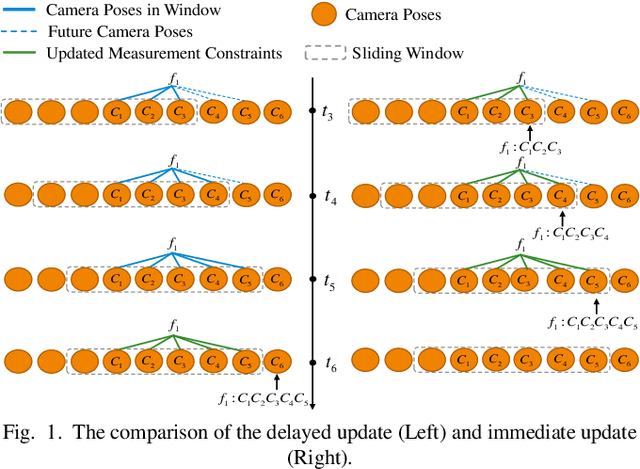
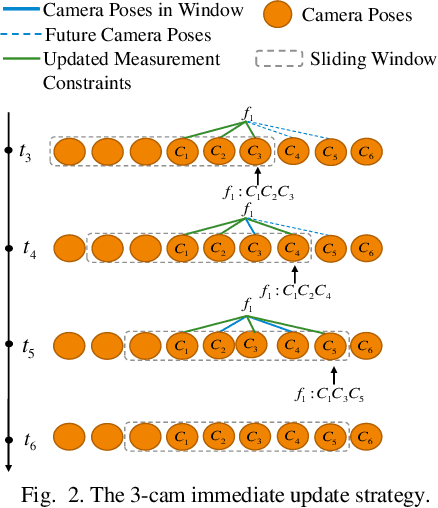
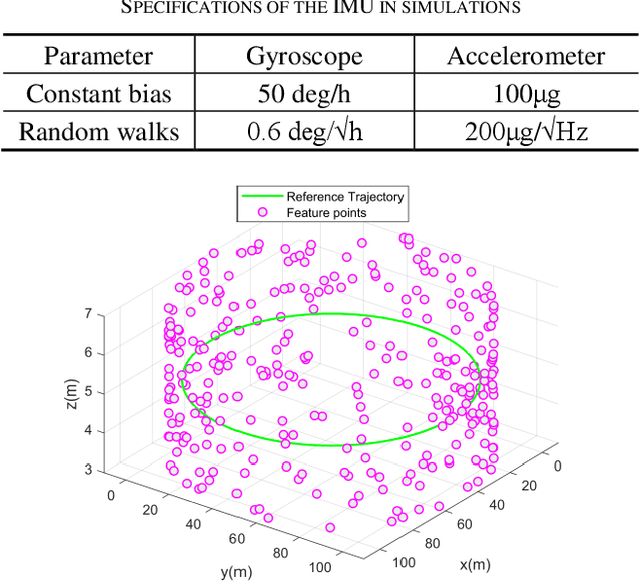
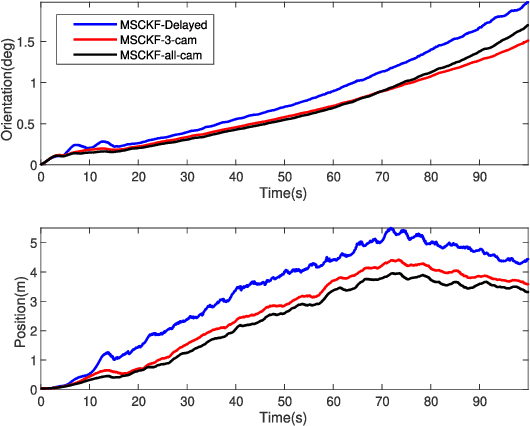
The lightweight Multi-state Constraint Kalman Filter (MSCKF) has been well-known for its high efficiency, in which the delayed update has been usually adopted since its proposal. This work investigates the immediate update strategy of MSCKF based on timely reconstructed 3D feature points and measurement constraints. The differences between the delayed update and the immediate update are theoretically analyzed in detail. It is found that the immediate update helps construct more observation constraints and employ more filtering updates than the delayed update, which improves the linearization point of the measurement model and therefore enhances the estimation accuracy. Numerical simulations and experiments show that the immediate update strategy significantly enhances MSCKF even with a small amount of feature observations.
Rumor Detection with a novel graph neural network approach
Apr 02, 2024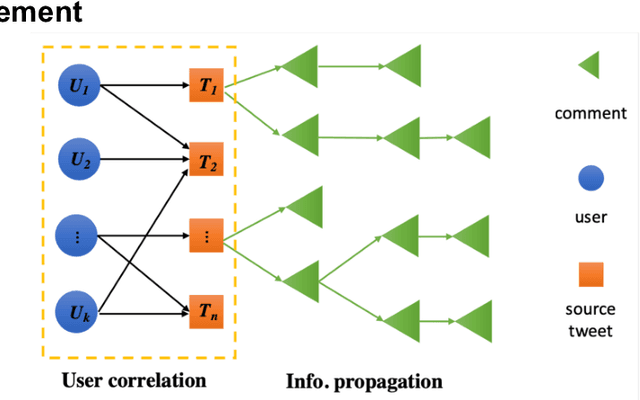
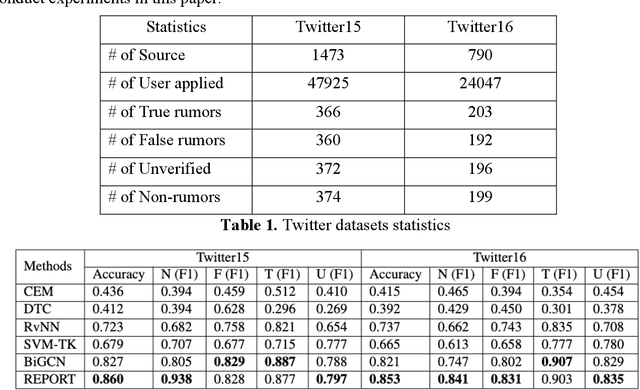

The wide spread of rumors on social media has caused a negative impact on people's daily life, leading to potential panic, fear, and mental health problems for the public. How to debunk rumors as early as possible remains a challenging problem. Existing studies mainly leverage information propagation structure to detect rumors, while very few works focus on correlation among users that they may coordinate to spread rumors in order to gain large popularity. In this paper, we propose a new detection model, that jointly learns both the representations of user correlation and information propagation to detect rumors on social media. Specifically, we leverage graph neural networks to learn the representations of user correlation from a bipartite graph that describes the correlations between users and source tweets, and the representations of information propagation with a tree structure. Then we combine the learned representations from these two modules to classify the rumors. Since malicious users intend to subvert our model after deployment, we further develop a greedy attack scheme to analyze the cost of three adversarial attacks: graph attack, comment attack, and joint attack. Evaluation results on two public datasets illustrate that the proposed MODEL outperforms the state-of-the-art rumor detection models. We also demonstrate our method performs well for early rumor detection. Moreover, the proposed detection method is more robust to adversarial attacks compared to the best existing method. Importantly, we show that it requires a high cost for attackers to subvert user correlation pattern, demonstrating the importance of considering user correlation for rumor detection.
Image Captioning in news report scenario
Apr 02, 2024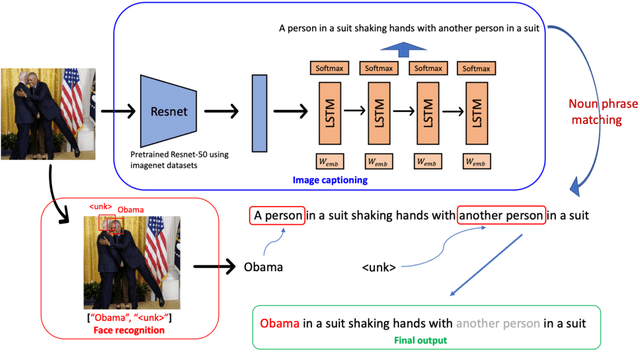
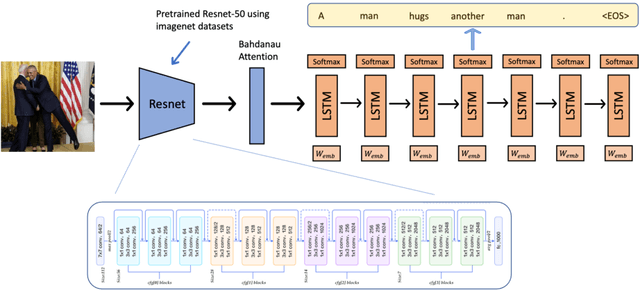


Image captioning strives to generate pertinent captions for specified images, situating itself at the crossroads of Computer Vision (CV) and Natural Language Processing (NLP). This endeavor is of paramount importance with far-reaching applications in recommendation systems, news outlets, social media, and beyond. Particularly within the realm of news reporting, captions are expected to encompass detailed information, such as the identities of celebrities captured in the images. However, much of the existing body of work primarily centers around understanding scenes and actions. In this paper, we explore the realm of image captioning specifically tailored for celebrity photographs, illustrating its broad potential for enhancing news industry practices. This exploration aims to augment automated news content generation, thereby facilitating a more nuanced dissemination of information. Our endeavor shows a broader horizon, enriching the narrative in news reporting through a more intuitive image captioning framework.
Visual-inertial state estimation based on Chebyshev polynomial optimization
Apr 01, 2024
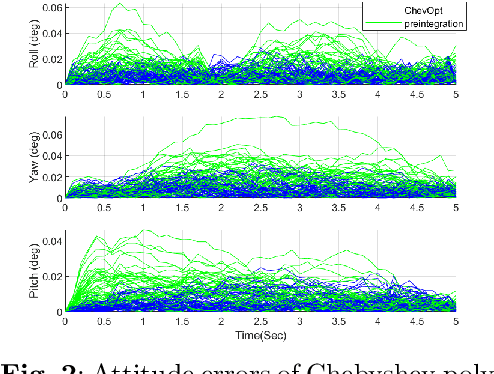

This paper proposes an innovative state estimation method for visual-inertial fusion based on Chebyshev polynomial optimization. Specifically, the pose is modeled as a Chebyshev polynomial of a certain order, and its time derivatives are used to calculate linear acceleration and angular velocity, which, along with inertial measurements, constitute dynamic constraints. This is coupled with a visual measurement model to construct a visual-inertial bundle adjustment formulation. Simulation and public dataset experiments show that the proposed method has better accuracy than the discrete-form preintegration method.
Boosting Diffusion Models with Moving Average Sampling in Frequency Domain
Mar 26, 2024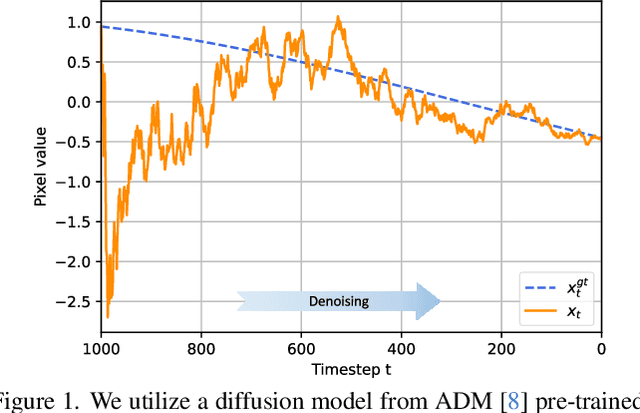
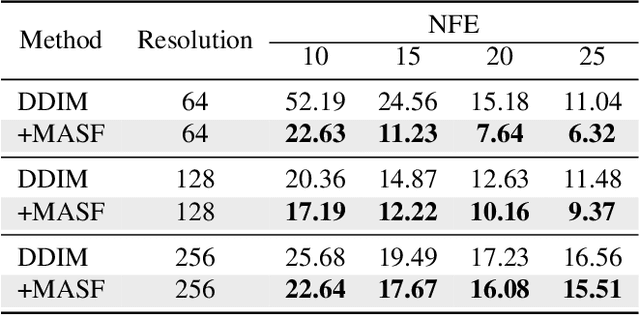

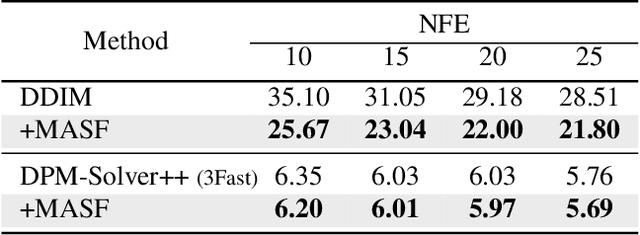
Diffusion models have recently brought a powerful revolution in image generation. Despite showing impressive generative capabilities, most of these models rely on the current sample to denoise the next one, possibly resulting in denoising instability. In this paper, we reinterpret the iterative denoising process as model optimization and leverage a moving average mechanism to ensemble all the prior samples. Instead of simply applying moving average to the denoised samples at different timesteps, we first map the denoised samples to data space and then perform moving average to avoid distribution shift across timesteps. In view that diffusion models evolve the recovery from low-frequency components to high-frequency details, we further decompose the samples into different frequency components and execute moving average separately on each component. We name the complete approach "Moving Average Sampling in Frequency domain (MASF)". MASF could be seamlessly integrated into mainstream pre-trained diffusion models and sampling schedules. Extensive experiments on both unconditional and conditional diffusion models demonstrate that our MASF leads to superior performances compared to the baselines, with almost negligible additional complexity cost.