 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing the Thought of a Grandmaster-level Chess-Playing Transformer
Apr 11, 2026While modern transformer neural networks achieve grandmaster-level performance in chess and other reasoning tasks, their internal computation process remains largely opaque. Focusing on Leela Chess Zero (LC0), we introduce a sparse decomposition framework to interpret its internal computation by decomposing its MLP and attention modules with sparse replacement layers, which capture the primary computation process of LC0. We conduct a detailed case study showing that these pathways expose rich, interpretable tactical considerations that are empirically verifiable. We further introduce three quantitative metrics and show that LC0 exhibits parallel reasoning behavior consistent with the inductive bias of its policy head architecture. To the best of our knowledge, this is the first work to decompose the internal computation of a transformer on both MLP and attention modules for interpretability. Combining sparse replacement layers and causal interventions in LC0 provides a comprehensive understanding of advanced tactical reasoning, offering critical insights into the underlying mechanisms of superhuman systems. Our code is available at https://github.com/JacklE0niden/Leela-SAEs.
PHASOR: Anatomy- and Phase-Consistent Volumetric Diffusion for CT Virtual Contrast Enhancement
Apr 01, 2026Contrast-enhanced computed tomography (CECT) is pivotal for highlighting tissue perfusion and vascularity, yet its clinical ubiquity is impeded by the invasive nature of contrast agents and radiation risks. While virtual contrast enhancement (VCE) offers an alternative to synthesizing CECT from non-contrast CT (NCCT), existing methods struggle with anatomical heterogeneity and spatial misalignment, leading to inconsistent enhancement patterns and incorrect details. This paper introduces PHASOR, a volumetric diffusion framework for high-fidelity CT VCE. By treating CT volumes as coherent sequences, we leverage a video diffusion model to enhance structural coherence and volumetric accuracy. To ensure anatomy-phase consistent synthesis, we introduce two complementary modules. First, anatomy-routed mixture-of-experts (AR-MoE) anchors distinct enhancement patterns to anatomical semantics, with organ-specific memory to capture salient details. Second, intensity-phase aware representation alignment (IP-REPA) highlights intricate contrast signals while mitigating the impact of imperfect spatial alignment. Extensive experiments across three datasets demonstrate that PHASOR significantly outperforms state-of-the-art methods in both synthesis quality and enhancement accuracy.
Diff-Aid: Inference-time Adaptive Interaction Denoising for Rectified Text-to-Image Generation
Feb 14, 2026Recent text-to-image (T2I) diffusion models have achieved remarkable advancement, yet faithfully following complex textual descriptions remains challenging due to insufficient interactions between textual and visual features. Prior approaches enhance such interactions via architectural design or handcrafted textual condition weighting, but lack flexibility and overlook the dynamic interactions across different blocks and denoising stages. To provide a more flexible and efficient solution to this problem, we propose Diff-Aid, a lightweight inference-time method that adaptively adjusts per-token text and image interactions across transformer blocks and denoising timesteps. Beyond improving generation quality, Diff-Aid yields interpretable modulation patterns that reveal how different blocks, timesteps, and textual tokens contribute to semantic alignment during denoising. As a plug-and-play module, Diff-Aid can be seamlessly integrated into downstream applications for further improvement, including style LoRAs, controllable generation, and zero-shot editing. Experiments on strong baselines (SD 3.5 and FLUX) demonstrate consistent improvements in prompt adherence, visual quality, and human preference across various metrics. Our code and models will be released.
Unraveling MMDiT Blocks: Training-free Analysis and Enhancement of Text-conditioned Diffusion
Jan 05, 2026Recent breakthroughs of transformer-based diffusion models, particularly with Multimodal Diffusion Transformers (MMDiT) driven models like FLUX and Qwen Image, have facilitated thrilling experiences in text-to-image generation and editing. To understand the internal mechanism of MMDiT-based models, existing methods tried to analyze the effect of specific components like positional encoding and attention layers. Yet, a comprehensive understanding of how different blocks and their interactions with textual conditions contribute to the synthesis process remains elusive. In this paper, we first develop a systematic pipeline to comprehensively investigate each block's functionality by removing, disabling and enhancing textual hidden-states at corresponding blocks. Our analysis reveals that 1) semantic information appears in earlier blocks and finer details are rendered in later blocks, 2) removing specific blocks is usually less disruptive than disabling text conditions, and 3) enhancing textual conditions in selective blocks improves semantic attributes. Building on these observations, we further propose novel training-free strategies for improved text alignment, precise editing, and acceleration. Extensive experiments demonstrated that our method outperforms various baselines and remains flexible across text-to-image generation, image editing, and inference acceleration. Our method improves T2I-Combench++ from 56.92% to 63.00% and GenEval from 66.42% to 71.63% on SD3.5, without sacrificing synthesis quality. These results advance understanding of MMDiT models and provide valuable insights to unlock new possibilities for further improvements.
MUSE: Multi-Scale Dense Self-Distillation for Nucleus Detection and Classification
Nov 07, 2025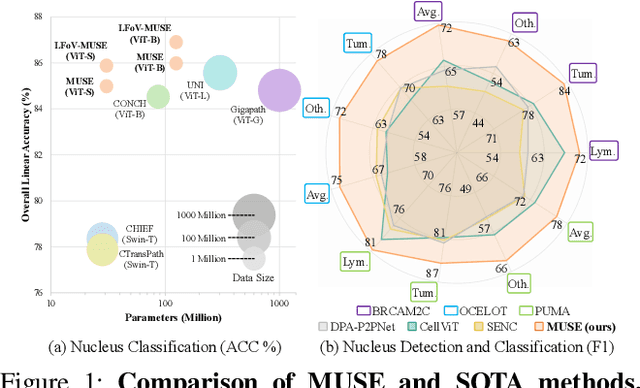
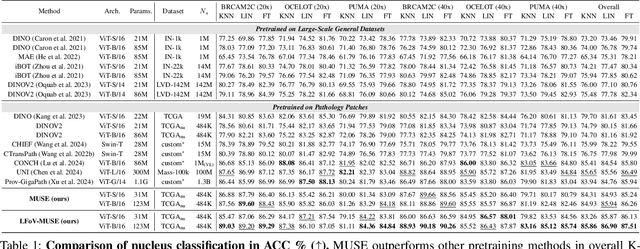
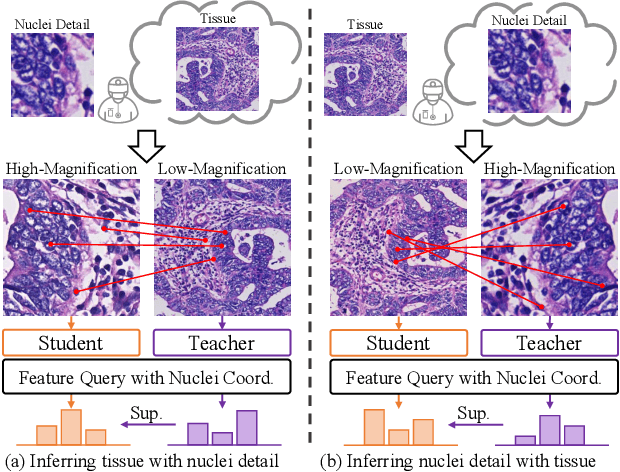
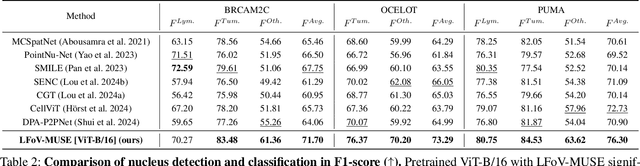
Nucleus detection and classification (NDC) in histopathology analysis is a fundamental task that underpins a wide range of high-level pathology applications. However, existing methods heavily rely on labor-intensive nucleus-level annotations and struggle to fully exploit large-scale unlabeled data for learning discriminative nucleus representations. In this work, we propose MUSE (MUlti-scale denSE self-distillation), a novel self-supervised learning method tailored for NDC. At its core is NuLo (Nucleus-based Local self-distillation), a coordinate-guided mechanism that enables flexible local self-distillation based on predicted nucleus positions. By removing the need for strict spatial alignment between augmented views, NuLo allows critical cross-scale alignment, thus unlocking the capacity of models for fine-grained nucleus-level representation. To support MUSE, we design a simple yet effective encoder-decoder architecture and a large field-of-view semi-supervised fine-tuning strategy that together maximize the value of unlabeled pathology images. Extensive experiments on three widely used benchmarks demonstrate that MUSE effectively addresses the core challenges of histopathological NDC. The resulting models not only surpass state-of-the-art supervised baselines but also outperform generic pathology foundation models.
UniAPO: Unified Multimodal Automated Prompt Optimization
Aug 25, 2025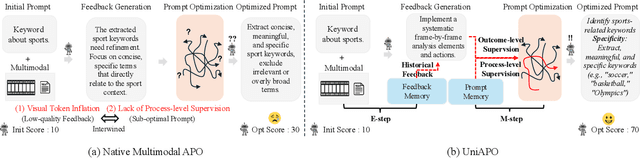
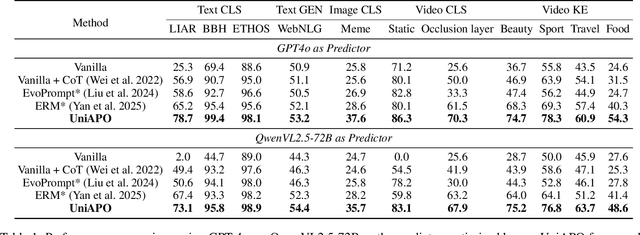
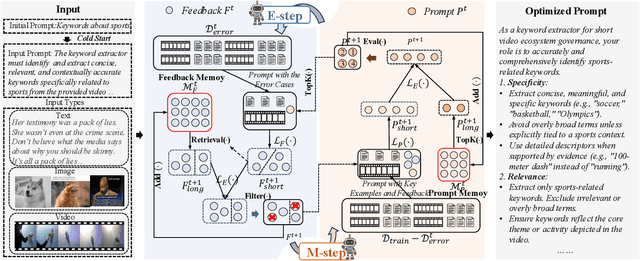
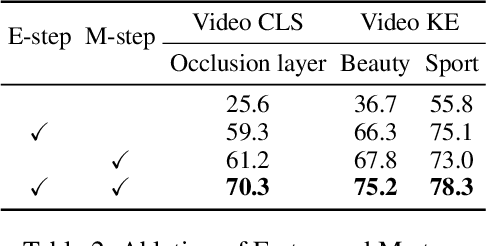
Prompting is fundamental to unlocking the full potential of large language models. To automate and enhance this process, automatic prompt optimization (APO) has been developed, demonstrating effectiveness primarily in text-only input scenarios. However, extending existing APO methods to multimodal tasks, such as video-language generation introduces two core challenges: (i) visual token inflation, where long visual token sequences restrict context capacity and result in insufficient feedback signals; (ii) a lack of process-level supervision, as existing methods focus on outcome-level supervision and overlook intermediate supervision, limiting prompt optimization. We present UniAPO: Unified Multimodal Automated Prompt Optimization, the first framework tailored for multimodal APO. UniAPO adopts an EM-inspired optimization process that decouples feedback modeling and prompt refinement, making the optimization more stable and goal-driven. To further address the aforementioned challenges, we introduce a short-long term memory mechanism: historical feedback mitigates context limitations, while historical prompts provide directional guidance for effective prompt optimization. UniAPO achieves consistent gains across text, image, and video benchmarks, establishing a unified framework for efficient and transferable prompt optimization.
FoundDiff: Foundational Diffusion Model for Generalizable Low-Dose CT Denoising
Aug 24, 2025Low-dose computed tomography (CT) denoising is crucial for reduced radiation exposure while ensuring diagnostically acceptable image quality. Despite significant advancements driven by deep learning (DL) in recent years, existing DL-based methods, typically trained on a specific dose level and anatomical region, struggle to handle diverse noise characteristics and anatomical heterogeneity during varied scanning conditions, limiting their generalizability and robustness in clinical scenarios. In this paper, we propose FoundDiff, a foundational diffusion model for unified and generalizable LDCT denoising across various dose levels and anatomical regions. FoundDiff employs a two-stage strategy: (i) dose-anatomy perception and (ii) adaptive denoising. First, we develop a dose- and anatomy-aware contrastive language image pre-training model (DA-CLIP) to achieve robust dose and anatomy perception by leveraging specialized contrastive learning strategies to learn continuous representations that quantify ordinal dose variations and identify salient anatomical regions. Second, we design a dose- and anatomy-aware diffusion model (DA-Diff) to perform adaptive and generalizable denoising by synergistically integrating the learned dose and anatomy embeddings from DACLIP into diffusion process via a novel dose and anatomy conditional block (DACB) based on Mamba. Extensive experiments on two public LDCT datasets encompassing eight dose levels and three anatomical regions demonstrate superior denoising performance of FoundDiff over existing state-of-the-art methods and the remarkable generalization to unseen dose levels. The codes and models are available at https://github.com/hao1635/FoundDiff.
PROTOCOL: Partial Optimal Transport-enhanced Contrastive Learning for Imbalanced Multi-view Clustering
Jun 14, 2025While contrastive multi-view clustering has achieved remarkable success, it implicitly assumes balanced class distribution. However, real-world multi-view data primarily exhibits class imbalance distribution. Consequently, existing methods suffer performance degradation due to their inability to perceive and model such imbalance. To address this challenge, we present the first systematic study of imbalanced multi-view clustering, focusing on two fundamental problems: i. perceiving class imbalance distribution, and ii. mitigating representation degradation of minority samples. We propose PROTOCOL, a novel PaRtial Optimal TranspOrt-enhanced COntrastive Learning framework for imbalanced multi-view clustering. First, for class imbalance perception, we map multi-view features into a consensus space and reformulate the imbalanced clustering as a partial optimal transport (POT) problem, augmented with progressive mass constraints and weighted KL divergence for class distributions. Second, we develop a POT-enhanced class-rebalanced contrastive learning at both feature and class levels, incorporating logit adjustment and class-sensitive learning to enhance minority sample representations. Extensive experiments demonstrate that PROTOCOL significantly improves clustering performance on imbalanced multi-view data, filling a critical research gap in this field.
Towards Understanding the Nature of Attention with Low-Rank Sparse Decomposition
Apr 29, 2025We propose Low-Rank Sparse Attention (Lorsa), a sparse replacement model of Transformer attention layers to disentangle original Multi Head Self Attention (MHSA) into individually comprehensible components. Lorsa is designed to address the challenge of attention superposition to understand attention-mediated interaction between features in different token positions. We show that Lorsa heads find cleaner and finer-grained versions of previously discovered MHSA behaviors like induction heads, successor heads and attention sink behavior (i.e., heavily attending to the first token). Lorsa and Sparse Autoencoder (SAE) are both sparse dictionary learning methods applied to different Transformer components, and lead to consistent findings in many ways. For instance, we discover a comprehensive family of arithmetic-specific Lorsa heads, each corresponding to an atomic operation in Llama-3.1-8B. Automated interpretability analysis indicates that Lorsa achieves parity with SAE in interpretability while Lorsa exhibits superior circuit discovery properties, especially for features computed collectively by multiple MHSA heads. We also conduct extensive experiments on architectural design ablation, Lorsa scaling law and error analysis.
A2DO: Adaptive Anti-Degradation Odometry with Deep Multi-Sensor Fusion for Autonomous Navigation
Feb 28, 2025Accurate localization is essential for the safe and effective navigation of autonomous vehicles, and Simultaneous Localization and Mapping (SLAM) is a cornerstone technology in this context. However, The performance of the SLAM system can deteriorate under challenging conditions such as low light, adverse weather, or obstructions due to sensor degradation. We present A2DO, a novel end-to-end multi-sensor fusion odometry system that enhances robustness in these scenarios through deep neural networks. A2DO integrates LiDAR and visual data, employing a multi-layer, multi-scale feature encoding module augmented by an attention mechanism to mitigate sensor degradation dynamically. The system is pre-trained extensively on simulated datasets covering a broad range of degradation scenarios and fine-tuned on a curated set of real-world data, ensuring robust adaptation to complex scenarios. Our experiments demonstrate that A2DO maintains superior localization accuracy and robustness across various degradation conditions, showcasing its potential for practical implementation in autonomous vehicle systems.