 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Differential Linear Attention: Enhancing Linear Diffusion Transformer for High-Quality Image Generation
Jan 20, 2026Diffusion transformers (DiTs) have emerged as a powerful architecture for high-fidelity image generation, yet the quadratic cost of self-attention poses a major scalability bottleneck. To address this, linear attention mechanisms have been adopted to reduce computational cost; unfortunately, the resulting linear diffusion transformers (LiTs) models often come at the expense of generative performance, frequently producing over-smoothed attention weights that limit expressiveness. In this work, we introduce Dynamic Differential Linear Attention (DyDiLA), a novel linear attention formulation that enhances the effectiveness of LiTs by mitigating the oversmoothing issue and improving generation quality. Specifically, the novelty of DyDiLA lies in three key designs: (i) dynamic projection module, which facilitates the decoupling of token representations by learning with dynamically assigned knowledge; (ii) dynamic measure kernel, which provides a better similarity measurement to capture fine-grained semantic distinctions between tokens by dynamically assigning kernel functions for token processing; and (iii) token differential operator, which enables more robust query-to-key retrieval by calculating the differences between the tokens and their corresponding information redundancy produced by dynamic measure kernel. To capitalize on DyDiLA, we introduce a refined LiT, termed DyDi-LiT, that systematically incorporates our advancements. Extensive experiments show that DyDi-LiT consistently outperforms current state-of-the-art (SOTA) models across multiple metrics, underscoring its strong practical potential.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
UniSino: Physics-Driven Foundational Model for Universal CT Sinogram Standardization
Aug 25, 2025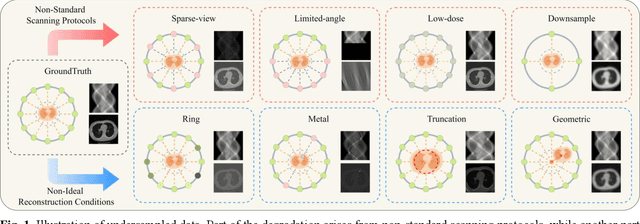
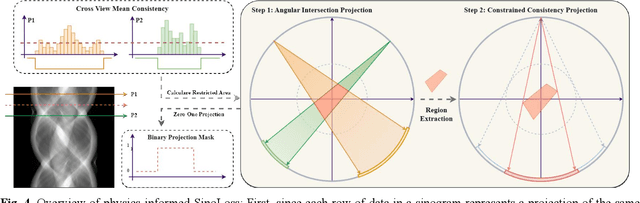
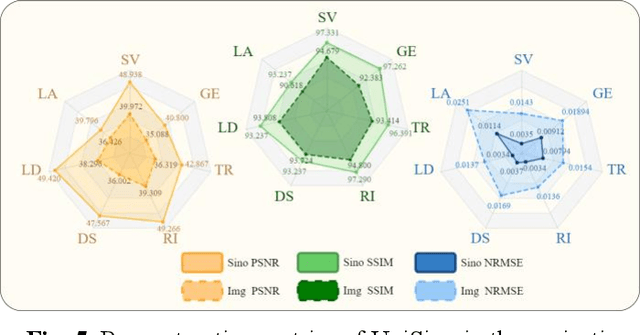
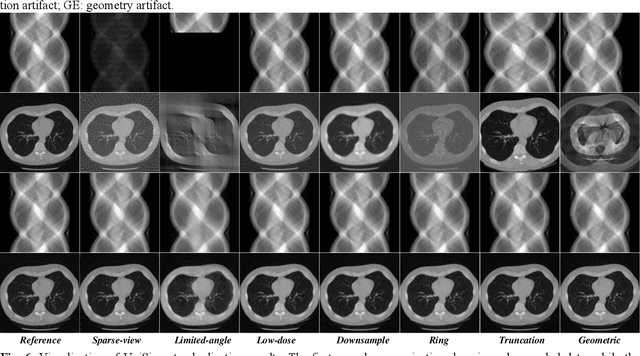
During raw-data acquisition in CT imaging, diverse factors can degrade the collected sinograms, with undersampling and noise leading to severe artifacts and noise in reconstructed images and compromising diagnostic accuracy. Conventional correction methods rely on manually designed algorithms or fixed empirical parameters, but these approaches often lack generalizability across heterogeneous artifact types. To address these limitations, we propose UniSino, a foundation model for universal CT sinogram standardization. Unlike existing foundational models that operate in image domain, UniSino directly standardizes data in the projection domain, which enables stronger generalization across diverse undersampling scenarios. Its training framework incorporates the physical characteristics of sinograms, enhancing generalization and enabling robust performance across multiple subtasks spanning four benchmark datasets. Experimental results demonstrate thatUniSino achieves superior reconstruction quality both single and mixed undersampling case, demonstrating exceptional robustness and generalization in sinogram enhancement for CT imaging. The code is available at: https://github.com/yqx7150/UniSino.
FoundDiff: Foundational Diffusion Model for Generalizable Low-Dose CT Denoising
Aug 24, 2025Low-dose computed tomography (CT) denoising is crucial for reduced radiation exposure while ensuring diagnostically acceptable image quality. Despite significant advancements driven by deep learning (DL) in recent years, existing DL-based methods, typically trained on a specific dose level and anatomical region, struggle to handle diverse noise characteristics and anatomical heterogeneity during varied scanning conditions, limiting their generalizability and robustness in clinical scenarios. In this paper, we propose FoundDiff, a foundational diffusion model for unified and generalizable LDCT denoising across various dose levels and anatomical regions. FoundDiff employs a two-stage strategy: (i) dose-anatomy perception and (ii) adaptive denoising. First, we develop a dose- and anatomy-aware contrastive language image pre-training model (DA-CLIP) to achieve robust dose and anatomy perception by leveraging specialized contrastive learning strategies to learn continuous representations that quantify ordinal dose variations and identify salient anatomical regions. Second, we design a dose- and anatomy-aware diffusion model (DA-Diff) to perform adaptive and generalizable denoising by synergistically integrating the learned dose and anatomy embeddings from DACLIP into diffusion process via a novel dose and anatomy conditional block (DACB) based on Mamba. Extensive experiments on two public LDCT datasets encompassing eight dose levels and three anatomical regions demonstrate superior denoising performance of FoundDiff over existing state-of-the-art methods and the remarkable generalization to unseen dose levels. The codes and models are available at https://github.com/hao1635/FoundDiff.
LangMamba: A Language-driven Mamba Framework for Low-dose CT Denoising with Vision-language Models
Jul 08, 2025Low-dose computed tomography (LDCT) reduces radiation exposure but often degrades image quality, potentially compromising diagnostic accuracy. Existing deep learning-based denoising methods focus primarily on pixel-level mappings, overlooking the potential benefits of high-level semantic guidance. Recent advances in vision-language models (VLMs) suggest that language can serve as a powerful tool for capturing structured semantic information, offering new opportunities to improve LDCT reconstruction. In this paper, we introduce LangMamba, a Language-driven Mamba framework for LDCT denoising that leverages VLM-derived representations to enhance supervision from normal-dose CT (NDCT). LangMamba follows a two-stage learning strategy. First, we pre-train a Language-guided AutoEncoder (LangAE) that leverages frozen VLMs to map NDCT images into a semantic space enriched with anatomical information. Second, we synergize LangAE with two key components to guide LDCT denoising: Semantic-Enhanced Efficient Denoiser (SEED), which enhances NDCT-relevant local semantic while capturing global features with efficient Mamba mechanism, and Language-engaged Dual-space Alignment (LangDA) Loss, which ensures that denoised images align with NDCT in both perceptual and semantic spaces. Extensive experiments on two public datasets demonstrate that LangMamba outperforms conventional state-of-the-art methods, significantly improving detail preservation and visual fidelity. Remarkably, LangAE exhibits strong generalizability to unseen datasets, thereby reducing training costs. Furthermore, LangDA loss improves explainability by integrating language-guided insights into image reconstruction and offers a plug-and-play fashion. Our findings shed new light on the potential of language as a supervisory signal to advance LDCT denoising. The code is publicly available on https://github.com/hao1635/LangMamba.
PROTOCOL: Partial Optimal Transport-enhanced Contrastive Learning for Imbalanced Multi-view Clustering
Jun 14, 2025While contrastive multi-view clustering has achieved remarkable success, it implicitly assumes balanced class distribution. However, real-world multi-view data primarily exhibits class imbalance distribution. Consequently, existing methods suffer performance degradation due to their inability to perceive and model such imbalance. To address this challenge, we present the first systematic study of imbalanced multi-view clustering, focusing on two fundamental problems: i. perceiving class imbalance distribution, and ii. mitigating representation degradation of minority samples. We propose PROTOCOL, a novel PaRtial Optimal TranspOrt-enhanced COntrastive Learning framework for imbalanced multi-view clustering. First, for class imbalance perception, we map multi-view features into a consensus space and reformulate the imbalanced clustering as a partial optimal transport (POT) problem, augmented with progressive mass constraints and weighted KL divergence for class distributions. Second, we develop a POT-enhanced class-rebalanced contrastive learning at both feature and class levels, incorporating logit adjustment and class-sensitive learning to enhance minority sample representations. Extensive experiments demonstrate that PROTOCOL significantly improves clustering performance on imbalanced multi-view data, filling a critical research gap in this field.
MedITok: A Unified Tokenizer for Medical Image Synthesis and Interpretation
May 25, 2025Advanced autoregressive models have reshaped multimodal AI. However, their transformative potential in medical imaging remains largely untapped due to the absence of a unified visual tokenizer -- one capable of capturing fine-grained visual structures for faithful image reconstruction and realistic image synthesis, as well as rich semantics for accurate diagnosis and image interpretation. To this end, we present MedITok, the first unified tokenizer tailored for medical images, encoding both low-level structural details and high-level clinical semantics within a unified latent space. To balance these competing objectives, we introduce a novel two-stage training framework: a visual representation alignment stage that cold-starts the tokenizer reconstruction learning with a visual semantic constraint, followed by a textual semantic representation alignment stage that infuses detailed clinical semantics into the latent space. Trained on the meticulously collected large-scale dataset with over 30 million medical images and 2 million image-caption pairs, MedITok achieves state-of-the-art performance on more than 30 datasets across 9 imaging modalities and 4 different tasks. By providing a unified token space for autoregressive modeling, MedITok supports a wide range of tasks in clinical diagnostics and generative healthcare applications. Model and code will be made publicly available at: https://github.com/Masaaki-75/meditok.
Towards Interpretable Counterfactual Generation via Multimodal Autoregression
Mar 29, 2025Counterfactual medical image generation enables clinicians to explore clinical hypotheses, such as predicting disease progression, facilitating their decision-making. While existing methods can generate visually plausible images from disease progression prompts, they produce silent predictions that lack interpretation to verify how the generation reflects the hypothesized progression -- a critical gap for medical applications that require traceable reasoning. In this paper, we propose Interpretable Counterfactual Generation (ICG), a novel task requiring the joint generation of counterfactual images that reflect the clinical hypothesis and interpretation texts that outline the visual changes induced by the hypothesis. To enable ICG, we present ICG-CXR, the first dataset pairing longitudinal medical images with hypothetical progression prompts and textual interpretations. We further introduce ProgEmu, an autoregressive model that unifies the generation of counterfactual images and textual interpretations. We demonstrate the superiority of ProgEmu in generating progression-aligned counterfactuals and interpretations, showing significant potential in enhancing clinical decision support and medical education. Project page: https://progemu.github.io.
Shushing! Let's Imagine an Authentic Speech from the Silent Video
Mar 19, 2025Vision-guided speech generation aims to produce authentic speech from facial appearance or lip motions without relying on auditory signals, offering significant potential for applications such as dubbing in filmmaking and assisting individuals with aphonia. Despite recent progress, existing methods struggle to achieve unified cross-modal alignment across semantics, timbre, and emotional prosody from visual cues, prompting us to propose Consistent Video-to-Speech (CV2S) as an extended task to enhance cross-modal consistency. To tackle emerging challenges, we introduce ImaginTalk, a novel cross-modal diffusion framework that generates faithful speech using only visual input, operating within a discrete space. Specifically, we propose a discrete lip aligner that predicts discrete speech tokens from lip videos to capture semantic information, while an error detector identifies misaligned tokens, which are subsequently refined through masked language modeling with BERT. To further enhance the expressiveness of the generated speech, we develop a style diffusion transformer equipped with a face-style adapter that adaptively customizes identity and prosody dynamics across both the channel and temporal dimensions while ensuring synchronization with lip-aware semantic features. Extensive experiments demonstrate that ImaginTalk can generate high-fidelity speech with more accurate semantic details and greater expressiveness in timbre and emotion compared to state-of-the-art baselines. Demos are shown at our project page: https://imagintalk.github.io.
DreamRelation: Relation-Centric Video Customization
Mar 10, 2025Relational video customization refers to the creation of personalized videos that depict user-specified relations between two subjects, a crucial task for comprehending real-world visual content. While existing methods can personalize subject appearances and motions, they still struggle with complex relational video customization, where precise relational modeling and high generalization across subject categories are essential. The primary challenge arises from the intricate spatial arrangements, layout variations, and nuanced temporal dynamics inherent in relations; consequently, current models tend to overemphasize irrelevant visual details rather than capturing meaningful interactions. To address these challenges, we propose DreamRelation, a novel approach that personalizes relations through a small set of exemplar videos, leveraging two key components: Relational Decoupling Learning and Relational Dynamics Enhancement. First, in Relational Decoupling Learning, we disentangle relations from subject appearances using relation LoRA triplet and hybrid mask training strategy, ensuring better generalization across diverse relationships. Furthermore, we determine the optimal design of relation LoRA triplet by analyzing the distinct roles of the query, key, and value features within MM-DiT's attention mechanism, making DreamRelation the first relational video generation framework with explainable components. Second, in Relational Dynamics Enhancement, we introduce space-time relational contrastive loss, which prioritizes relational dynamics while minimizing the reliance on detailed subject appearances. Extensive experiments demonstrate that DreamRelation outperforms state-of-the-art methods in relational video customization. Code and models will be made publicly available.