 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSAVBench: Towards Comprehensive and Reliable Evaluation of Multi-Shot Audio-Video Generation
May 19, 2026Video generation is rapidly evolving from single-shot synthesis to complex multi-shot audio-video (MSAV) narratives to meet real-world demands. However, evaluating such frontier models remains a fundamental challenge. Existing benchmarks are limited in scope and data diversity, and rely on rigid evaluation pipelines, preventing systematic and reliable assessment of modern MSAV models. To bridge these gaps, we introduce MSAVBench, the first comprehensive benchmark and adaptive hybrid evaluation framework for multi-shot audio-video generation. Our benchmark spans four key dimensions, video, audio, shot, and reference, covering diverse task settings, varying shot counts of up to 15, and challenging non-realistic scenarios. Our evaluation framework improves robustness through an adaptive self-correction mechanism for shot segmentation, instance-wise rubrics for subjective metrics, and tool-grounded evidence extraction for complex judgments. Furthermore, MSAVBench achieves high alignment with human judgments, reaching a Spearman rank correlation of 91.5%. Our systematic evaluation of 19 state-of-the-art closed- and open-source models shows that current systems still struggle with director-level control and fine-grained audio-visual synchronization, while modular or agentic generation pipelines offer a promising path toward narrowing the gap between open- and closed-source models. We will release the benchmark data and evaluation code to facilitate future research.
DreamVideo-Omni: Omni-Motion Controlled Multi-Subject Video Customization with Latent Identity Reinforcement Learning
Mar 12, 2026While large-scale diffusion models have revolutionized video synthesis, achieving precise control over both multi-subject identity and multi-granularity motion remains a significant challenge. Recent attempts to bridge this gap often suffer from limited motion granularity, control ambiguity, and identity degradation, leading to suboptimal performance on identity preservation and motion control. In this work, we present DreamVideo-Omni, a unified framework enabling harmonious multi-subject customization with omni-motion control via a progressive two-stage training paradigm. In the first stage, we integrate comprehensive control signals for joint training, encompassing subject appearances, global motion, local dynamics, and camera movements. To ensure robust and precise controllability, we introduce a condition-aware 3D rotary positional embedding to coordinate heterogeneous inputs and a hierarchical motion injection strategy to enhance global motion guidance. Furthermore, to resolve multi-subject ambiguity, we introduce group and role embeddings to explicitly anchor motion signals to specific identities, effectively disentangling complex scenes into independent controllable instances. In the second stage, to mitigate identity degradation, we design a latent identity reward feedback learning paradigm by training a latent identity reward model upon a pretrained video diffusion backbone. This provides motion-aware identity rewards in the latent space, prioritizing identity preservation aligned with human preferences. Supported by our curated large-scale dataset and the comprehensive DreamOmni Bench for multi-subject and omni-motion control evaluation, DreamVideo-Omni demonstrates superior performance in generating high-quality videos with precise controllability.
Wan-Move: Motion-controllable Video Generation via Latent Trajectory Guidance
Dec 09, 2025We present Wan-Move, a simple and scalable framework that brings motion control to video generative models. Existing motion-controllable methods typically suffer from coarse control granularity and limited scalability, leaving their outputs insufficient for practical use. We narrow this gap by achieving precise and high-quality motion control. Our core idea is to directly make the original condition features motion-aware for guiding video synthesis. To this end, we first represent object motions with dense point trajectories, allowing fine-grained control over the scene. We then project these trajectories into latent space and propagate the first frame's features along each trajectory, producing an aligned spatiotemporal feature map that tells how each scene element should move. This feature map serves as the updated latent condition, which is naturally integrated into the off-the-shelf image-to-video model, e.g., Wan-I2V-14B, as motion guidance without any architecture change. It removes the need for auxiliary motion encoders and makes fine-tuning base models easily scalable. Through scaled training, Wan-Move generates 5-second, 480p videos whose motion controllability rivals Kling 1.5 Pro's commercial Motion Brush, as indicated by user studies. To support comprehensive evaluation, we further design MoveBench, a rigorously curated benchmark featuring diverse content categories and hybrid-verified annotations. It is distinguished by larger data volume, longer video durations, and high-quality motion annotations. Extensive experiments on MoveBench and the public dataset consistently show Wan-Move's superior motion quality. Code, models, and benchmark data are made publicly available.
Self-Contradiction as Self-Improvement: Mitigating the Generation-Understanding Gap in MLLMs
Jul 22, 2025
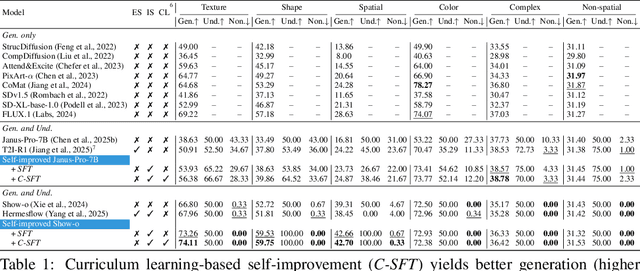
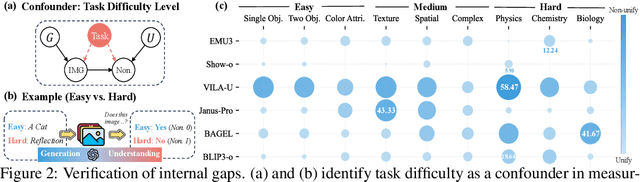

Despite efforts to unify multimodal generation and understanding tasks in a single model, we show these MLLMs exhibit self-contradiction where generation produces images deemed misaligned with input prompts based on the model's own understanding. We define a Nonunified score that quantifies such self-contradiction. Our empirical results reveal that the self-contradiction mainly arises from weak generation that fails to align with prompts, rather than misunderstanding. This capability asymmetry indicates the potential of leveraging self-contradiction for self-improvement, where the stronger model understanding guides the weaker generation to mitigate the generation-understanding gap. Applying standard post-training methods (e.g., SFT, DPO) with such internal supervision successfully improves both generation and unification. We discover a co-improvement effect on both generation and understanding when only fine-tuning the generation branch, a phenomenon known in pre-training but underexplored in post-training. Our analysis shows improvements stem from better detection of false positives that are previously incorrectly identified as prompt-aligned. Theoretically, we show the aligned training dynamics between generation and understanding allow reduced prompt-misaligned generations to also improve mismatch detection in the understanding branch. Additionally, the framework reveals a potential risk of co-degradation under poor supervision-an overlooked phenomenon that is empirically validated in our experiments. Notably, we find intrinsic metrics like Nonunified score cannot distinguish co-degradation from co-improvement, which highlights the necessity of data quality check. Finally, we propose a curriculum-based strategy based on our findings that gradually introduces harder samples as the model improves, leading to better unification and improved MLLM generation and understanding.
DFVEdit: Conditional Delta Flow Vector for Zero-shot Video Editing
Jun 26, 2025The advent of Video Diffusion Transformers (Video DiTs) marks a milestone in video generation. However, directly applying existing video editing methods to Video DiTs often incurs substantial computational overhead, due to resource-intensive attention modification or finetuning. To alleviate this problem, we present DFVEdit, an efficient zero-shot video editing method tailored for Video DiTs. DFVEdit eliminates the need for both attention modification and fine-tuning by directly operating on clean latents via flow transformation. To be more specific, we observe that editing and sampling can be unified under the continuous flow perspective. Building upon this foundation, we propose the Conditional Delta Flow Vector (CDFV) -- a theoretically unbiased estimation of DFV -- and integrate Implicit Cross Attention (ICA) guidance as well as Embedding Reinforcement (ER) to further enhance editing quality. DFVEdit excels in practical efficiency, offering at least 20x inference speed-up and 85\% memory reduction on Video DiTs compared to attention-engineering-based editing methods. Extensive quantitative and qualitative experiments demonstrate that DFVEdit can be seamlessly applied to popular Video DiTs (e.g., CogVideoX and Wan2.1), attaining state-of-the-art performance on structural fidelity, spatial-temporal consistency, and editing quality.
Taming Consistency Distillation for Accelerated Human Image Animation
Apr 15, 2025



Recent advancements in human image animation have been propelled by video diffusion models, yet their reliance on numerous iterative denoising steps results in high inference costs and slow speeds. An intuitive solution involves adopting consistency models, which serve as an effective acceleration paradigm through consistency distillation. However, simply employing this strategy in human image animation often leads to quality decline, including visual blurring, motion degradation, and facial distortion, particularly in dynamic regions. In this paper, we propose the DanceLCM approach complemented by several enhancements to improve visual quality and motion continuity at low-step regime: (1) segmented consistency distillation with an auxiliary light-weight head to incorporate supervision from real video latents, mitigating cumulative errors resulting from single full-trajectory generation; (2) a motion-focused loss to centre on motion regions, and explicit injection of facial fidelity features to improve face authenticity. Extensive qualitative and quantitative experiments demonstrate that DanceLCM achieves results comparable to state-of-the-art video diffusion models with a mere 2-4 inference steps, significantly reducing the inference burden without compromising video quality. The code and models will be made publicly available.
UniAnimate-DiT: Human Image Animation with Large-Scale Video Diffusion Transformer
Apr 15, 2025


This report presents UniAnimate-DiT, an advanced project that leverages the cutting-edge and powerful capabilities of the open-source Wan2.1 model for consistent human image animation. Specifically, to preserve the robust generative capabilities of the original Wan2.1 model, we implement Low-Rank Adaptation (LoRA) technique to fine-tune a minimal set of parameters, significantly reducing training memory overhead. A lightweight pose encoder consisting of multiple stacked 3D convolutional layers is designed to encode motion information of driving poses. Furthermore, we adopt a simple concatenation operation to integrate the reference appearance into the model and incorporate the pose information of the reference image for enhanced pose alignment. Experimental results show that our approach achieves visually appearing and temporally consistent high-fidelity animations. Trained on 480p (832x480) videos, UniAnimate-DiT demonstrates strong generalization capabilities to seamlessly upscale to 720P (1280x720) during inference. The training and inference code is publicly available at https://github.com/ali-vilab/UniAnimate-DiT.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
DreamRelation: Relation-Centric Video Customization
Mar 10, 2025Relational video customization refers to the creation of personalized videos that depict user-specified relations between two subjects, a crucial task for comprehending real-world visual content. While existing methods can personalize subject appearances and motions, they still struggle with complex relational video customization, where precise relational modeling and high generalization across subject categories are essential. The primary challenge arises from the intricate spatial arrangements, layout variations, and nuanced temporal dynamics inherent in relations; consequently, current models tend to overemphasize irrelevant visual details rather than capturing meaningful interactions. To address these challenges, we propose DreamRelation, a novel approach that personalizes relations through a small set of exemplar videos, leveraging two key components: Relational Decoupling Learning and Relational Dynamics Enhancement. First, in Relational Decoupling Learning, we disentangle relations from subject appearances using relation LoRA triplet and hybrid mask training strategy, ensuring better generalization across diverse relationships. Furthermore, we determine the optimal design of relation LoRA triplet by analyzing the distinct roles of the query, key, and value features within MM-DiT's attention mechanism, making DreamRelation the first relational video generation framework with explainable components. Second, in Relational Dynamics Enhancement, we introduce space-time relational contrastive loss, which prioritizes relational dynamics while minimizing the reliance on detailed subject appearances. Extensive experiments demonstrate that DreamRelation outperforms state-of-the-art methods in relational video customization. Code and models will be made publicly available.
FreeScale: Unleashing the Resolution of Diffusion Models via Tuning-Free Scale Fusion
Dec 12, 2024



Visual diffusion models achieve remarkable progress, yet they are typically trained at limited resolutions due to the lack of high-resolution data and constrained computation resources, hampering their ability to generate high-fidelity images or videos at higher resolutions. Recent efforts have explored tuning-free strategies to exhibit the untapped potential higher-resolution visual generation of pre-trained models. However, these methods are still prone to producing low-quality visual content with repetitive patterns. The key obstacle lies in the inevitable increase in high-frequency information when the model generates visual content exceeding its training resolution, leading to undesirable repetitive patterns deriving from the accumulated errors. To tackle this challenge, we propose FreeScale, a tuning-free inference paradigm to enable higher-resolution visual generation via scale fusion. Specifically, FreeScale processes information from different receptive scales and then fuses it by extracting desired frequency components. Extensive experiments validate the superiority of our paradigm in extending the capabilities of higher-resolution visual generation for both image and video models. Notably, compared with the previous best-performing method, FreeScale unlocks the generation of 8k-resolution images for the first time.