 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSAVBench: Towards Comprehensive and Reliable Evaluation of Multi-Shot Audio-Video Generation
May 19, 2026Video generation is rapidly evolving from single-shot synthesis to complex multi-shot audio-video (MSAV) narratives to meet real-world demands. However, evaluating such frontier models remains a fundamental challenge. Existing benchmarks are limited in scope and data diversity, and rely on rigid evaluation pipelines, preventing systematic and reliable assessment of modern MSAV models. To bridge these gaps, we introduce MSAVBench, the first comprehensive benchmark and adaptive hybrid evaluation framework for multi-shot audio-video generation. Our benchmark spans four key dimensions, video, audio, shot, and reference, covering diverse task settings, varying shot counts of up to 15, and challenging non-realistic scenarios. Our evaluation framework improves robustness through an adaptive self-correction mechanism for shot segmentation, instance-wise rubrics for subjective metrics, and tool-grounded evidence extraction for complex judgments. Furthermore, MSAVBench achieves high alignment with human judgments, reaching a Spearman rank correlation of 91.5%. Our systematic evaluation of 19 state-of-the-art closed- and open-source models shows that current systems still struggle with director-level control and fine-grained audio-visual synchronization, while modular or agentic generation pipelines offer a promising path toward narrowing the gap between open- and closed-source models. We will release the benchmark data and evaluation code to facilitate future research.
ReViSE: Towards Reason-Informed Video Editing in Unified Models with Self-Reflective Learning
Dec 11, 2025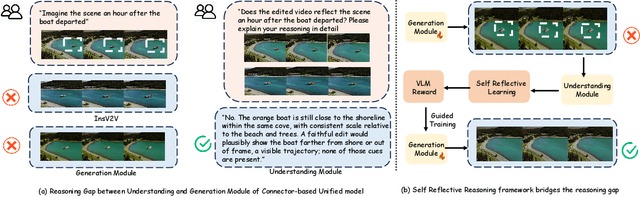
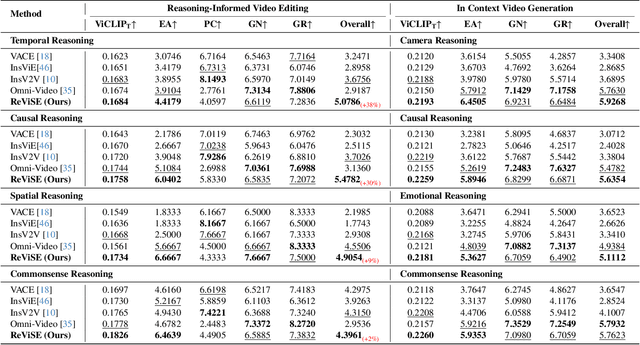

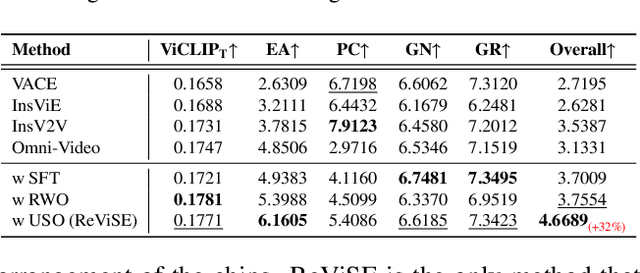
Video unified models exhibit strong capabilities in understanding and generation, yet they struggle with reason-informed visual editing even when equipped with powerful internal vision-language models (VLMs). We attribute this gap to two factors: 1) existing datasets are inadequate for training and evaluating reasoning-aware video editing, and 2) an inherent disconnect between the models' reasoning and editing capabilities, which prevents the rich understanding from effectively instructing the editing process. Bridging this gap requires an integrated framework that connects reasoning with visual transformation. To address this gap, we introduce the Reason-Informed Video Editing (RVE) task, which requires reasoning about physical plausibility and causal dynamics during editing. To support systematic evaluation, we construct RVE-Bench, a comprehensive benchmark with two complementary subsets: Reasoning-Informed Video Editing and In-Context Video Generation. These subsets cover diverse reasoning dimensions and real-world editing scenarios. Building upon this foundation, we propose the ReViSE, a Self-Reflective Reasoning (SRF) framework that unifies generation and evaluation within a single architecture. The model's internal VLM provides intrinsic feedback by assessing whether the edited video logically satisfies the given instruction. The differential feedback that refines the generator's reasoning behavior during training. Extensive experiments on RVE-Bench demonstrate that ReViSE significantly enhances editing accuracy and visual fidelity, achieving a 32% improvement of the Overall score in the reasoning-informed video editing subset over state-of-the-art methods.
Self-Contradiction as Self-Improvement: Mitigating the Generation-Understanding Gap in MLLMs
Jul 22, 2025
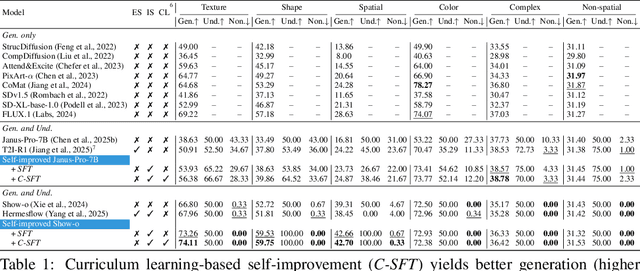
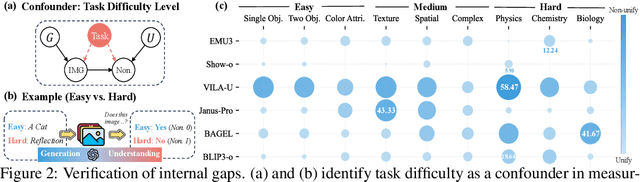

Despite efforts to unify multimodal generation and understanding tasks in a single model, we show these MLLMs exhibit self-contradiction where generation produces images deemed misaligned with input prompts based on the model's own understanding. We define a Nonunified score that quantifies such self-contradiction. Our empirical results reveal that the self-contradiction mainly arises from weak generation that fails to align with prompts, rather than misunderstanding. This capability asymmetry indicates the potential of leveraging self-contradiction for self-improvement, where the stronger model understanding guides the weaker generation to mitigate the generation-understanding gap. Applying standard post-training methods (e.g., SFT, DPO) with such internal supervision successfully improves both generation and unification. We discover a co-improvement effect on both generation and understanding when only fine-tuning the generation branch, a phenomenon known in pre-training but underexplored in post-training. Our analysis shows improvements stem from better detection of false positives that are previously incorrectly identified as prompt-aligned. Theoretically, we show the aligned training dynamics between generation and understanding allow reduced prompt-misaligned generations to also improve mismatch detection in the understanding branch. Additionally, the framework reveals a potential risk of co-degradation under poor supervision-an overlooked phenomenon that is empirically validated in our experiments. Notably, we find intrinsic metrics like Nonunified score cannot distinguish co-degradation from co-improvement, which highlights the necessity of data quality check. Finally, we propose a curriculum-based strategy based on our findings that gradually introduces harder samples as the model improves, leading to better unification and improved MLLM generation and understanding.
Corruption-Aware Training of Latent Video Diffusion Models for Robust Text-to-Video Generation
May 24, 2025Latent Video Diffusion Models (LVDMs) achieve high-quality generation but are sensitive to imperfect conditioning, which causes semantic drift and temporal incoherence on noisy, web-scale video-text datasets. We introduce CAT-LVDM, the first corruption-aware training framework for LVDMs that improves robustness through structured, data-aligned noise injection. Our method includes Batch-Centered Noise Injection (BCNI), which perturbs embeddings along intra-batch semantic directions to preserve temporal consistency. BCNI is especially effective on caption-rich datasets like WebVid-2M, MSR-VTT, and MSVD. We also propose Spectrum-Aware Contextual Noise (SACN), which injects noise along dominant spectral directions to improve low-frequency smoothness, showing strong results on UCF-101. On average, BCNI reduces FVD by 31.9% across WebVid-2M, MSR-VTT, and MSVD, while SACN yields a 12.3% improvement on UCF-101. Ablation studies confirm the benefit of low-rank, data-aligned noise. Our theoretical analysis further explains how such perturbations tighten entropy, Wasserstein, score-drift, mixing-time, and generalization bounds. CAT-LVDM establishes a principled, scalable training approach for robust video diffusion under multimodal noise. Code and models: https://github.com/chikap421/catlvdm
Capturing Conditional Dependence via Auto-regressive Diffusion Models
Apr 30, 2025Diffusion models have demonstrated appealing performance in both image and video generation. However, many works discover that they struggle to capture important, high-level relationships that are present in the real world. For example, they fail to learn physical laws from data, and even fail to understand that the objects in the world exist in a stable fashion. This is due to the fact that important conditional dependence structures are not adequately captured in the vanilla diffusion models. In this work, we initiate an in-depth study on strengthening the diffusion model to capture the conditional dependence structures in the data. In particular, we examine the efficacy of the auto-regressive (AR) diffusion models for such purpose and develop the first theoretical results on the sampling error of AR diffusion models under (possibly) the mildest data assumption. Our theoretical findings indicate that, compared with typical diffusion models, the AR variant produces samples with a reduced gap in approximating the data conditional distribution. On the other hand, the overall inference time of the AR-diffusion models is only moderately larger than that for the vanilla diffusion models, making them still practical for large scale applications. We also provide empirical results showing that when there is clear conditional dependence structure in the data, the AR diffusion models captures such structure, whereas vanilla DDPM fails to do so. On the other hand, when there is no obvious conditional dependence across patches of the data, AR diffusion does not outperform DDPM.
Can Diffusion Models Learn Hidden Inter-Feature Rules Behind Images?
Feb 07, 2025Despite the remarkable success of diffusion models (DMs) in data generation, they exhibit specific failure cases with unsatisfactory outputs. We focus on one such limitation: the ability of DMs to learn hidden rules between image features. Specifically, for image data with dependent features ($\mathbf{x}$) and ($\mathbf{y}$) (e.g., the height of the sun ($\mathbf{x}$) and the length of the shadow ($\mathbf{y}$)), we investigate whether DMs can accurately capture the inter-feature rule ($p(\mathbf{y}|\mathbf{x})$). Empirical evaluations on mainstream DMs (e.g., Stable Diffusion 3.5) reveal consistent failures, such as inconsistent lighting-shadow relationships and mismatched object-mirror reflections. Inspired by these findings, we design four synthetic tasks with strongly correlated features to assess DMs' rule-learning abilities. Extensive experiments show that while DMs can identify coarse-grained rules, they struggle with fine-grained ones. Our theoretical analysis demonstrates that DMs trained via denoising score matching (DSM) exhibit constant errors in learning hidden rules, as the DSM objective is not compatible with rule conformity. To mitigate this, we introduce a common technique - incorporating additional classifier guidance during sampling, which achieves (limited) improvements. Our analysis reveals that the subtle signals of fine-grained rules are challenging for the classifier to capture, providing insights for future exploration.
Masked Autoencoders Are Effective Tokenizers for Diffusion Models
Feb 05, 2025Recent advances in latent diffusion models have demonstrated their effectiveness for high-resolution image synthesis. However, the properties of the latent space from tokenizer for better learning and generation of diffusion models remain under-explored. Theoretically and empirically, we find that improved generation quality is closely tied to the latent distributions with better structure, such as the ones with fewer Gaussian Mixture modes and more discriminative features. Motivated by these insights, we propose MAETok, an autoencoder (AE) leveraging mask modeling to learn semantically rich latent space while maintaining reconstruction fidelity. Extensive experiments validate our analysis, demonstrating that the variational form of autoencoders is not necessary, and a discriminative latent space from AE alone enables state-of-the-art performance on ImageNet generation using only 128 tokens. MAETok achieves significant practical improvements, enabling a gFID of 1.69 with 76x faster training and 31x higher inference throughput for 512x512 generation. Our findings show that the structure of the latent space, rather than variational constraints, is crucial for effective diffusion models. Code and trained models are released.
Parallelized Autoregressive Visual Generation
Dec 19, 2024



Autoregressive models have emerged as a powerful approach for visual generation but suffer from slow inference speed due to their sequential token-by-token prediction process. In this paper, we propose a simple yet effective approach for parallelized autoregressive visual generation that improves generation efficiency while preserving the advantages of autoregressive modeling. Our key insight is that parallel generation depends on visual token dependencies-tokens with weak dependencies can be generated in parallel, while strongly dependent adjacent tokens are difficult to generate together, as their independent sampling may lead to inconsistencies. Based on this observation, we develop a parallel generation strategy that generates distant tokens with weak dependencies in parallel while maintaining sequential generation for strongly dependent local tokens. Our approach can be seamlessly integrated into standard autoregressive models without modifying the architecture or tokenizer. Experiments on ImageNet and UCF-101 demonstrate that our method achieves a 3.6x speedup with comparable quality and up to 9.5x speedup with minimal quality degradation across both image and video generation tasks. We hope this work will inspire future research in efficient visual generation and unified autoregressive modeling. Project page: https://epiphqny.github.io/PAR-project.
Beyond Surface Structure: A Causal Assessment of LLMs' Comprehension Ability
Nov 29, 2024Large language models (LLMs) have shown remarkable capability in natural language tasks, yet debate persists on whether they truly comprehend deep structure (i.e., core semantics) or merely rely on surface structure (e.g., presentation format). Prior studies observe that LLMs' performance declines when intervening on surface structure, arguing their success relies on surface structure recognition. However, surface structure sensitivity does not prevent deep structure comprehension. Rigorously evaluating LLMs' capability requires analyzing both, yet deep structure is often overlooked. To this end, we assess LLMs' comprehension ability using causal mediation analysis, aiming to fully discover the capability of using both deep and surface structures. Specifically, we formulate the comprehension of deep structure as direct causal effect (DCE) and that of surface structure as indirect causal effect (ICE), respectively. To address the non-estimability of original DCE and ICE -- stemming from the infeasibility of isolating mutual influences of deep and surface structures, we develop the corresponding quantifiable surrogates, including approximated DCE (ADCE) and approximated ICE (AICE). We further apply the ADCE to evaluate a series of mainstream LLMs, showing that most of them exhibit deep structure comprehension ability, which grows along with the prediction accuracy. Comparing ADCE and AICE demonstrates closed-source LLMs rely more on deep structure, while open-source LLMs are more surface-sensitive, which decreases with model scale. Theoretically, ADCE is a bidirectional evaluation, which measures both the sufficiency and necessity of deep structure changes in causing output variations, thus offering a more comprehensive assessment than accuracy, a common evaluation in LLMs. Our work provides new insights into LLMs' deep structure comprehension and offers novel methods for LLMs evaluation.
Slight Corruption in Pre-training Data Makes Better Diffusion Models
May 30, 2024



Diffusion models (DMs) have shown remarkable capabilities in generating realistic high-quality images, audios, and videos. They benefit significantly from extensive pre-training on large-scale datasets, including web-crawled data with paired data and conditions, such as image-text and image-class pairs. Despite rigorous filtering, these pre-training datasets often inevitably contain corrupted pairs where conditions do not accurately describe the data. This paper presents the first comprehensive study on the impact of such corruption in pre-training data of DMs. We synthetically corrupt ImageNet-1K and CC3M to pre-train and evaluate over 50 conditional DMs. Our empirical findings reveal that various types of slight corruption in pre-training can significantly enhance the quality, diversity, and fidelity of the generated images across different DMs, both during pre-training and downstream adaptation stages. Theoretically, we consider a Gaussian mixture model and prove that slight corruption in the condition leads to higher entropy and a reduced 2-Wasserstein distance to the ground truth of the data distribution generated by the corruptly trained DMs. Inspired by our analysis, we propose a simple method to improve the training of DMs on practical datasets by adding condition embedding perturbations (CEP). CEP significantly improves the performance of various DMs in both pre-training and downstream tasks. We hope that our study provides new insights into understanding the data and pre-training processes of DMs.