 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified ROI-based Image Compression Paradigm with Generalized Gaussian Model
Feb 01, 2026Region-of-Interest (ROI)-based image compression allocates bits unevenly according to the semantic importance of different regions. Such differentiated coding typically induces a sharp-peaked and heavy-tailed distribution. This distribution characteristic mathematically necessitates a probability model with adaptable shape parameters for accurate description. However, existing methods commonly use a Gaussian model to fit this distribution, resulting in a loss of coding performance. To systematically analyze the impact of this distribution on ROI coding, we develop a unified rate-distortion optimization theoretical paradigm. Building on this paradigm, we propose a novel Generalized Gaussian Model (GGM) to achieve flexible modeling of the latent variables distribution. To support stable optimization of GGM, we introduce effective differentiable functions and further propose a dynamic lower bound to alleviate train-test mismatch. Moreover, finite differences are introduced to solve the gradient computation after GGM fits the distribution. Experiments on COCO2017 demonstrate that our method achieves state-of-the-art in both ROI reconstruction and downstream tasks (e.g., Segmentation, Object Detection). Furthermore, compared to classical probability models, our GGM provides a more precise fit to feature distributions and achieves superior coding performance. The project page is at https://github.com/hukai-tju/ROIGGM.
LipNeXt: Scaling up Lipschitz-based Certified Robustness to Billion-parameter Models
Jan 26, 2026Lipschitz-based certification offers efficient, deterministic robustness guarantees but has struggled to scale in model size, training efficiency, and ImageNet performance. We introduce \emph{LipNeXt}, the first \emph{constraint-free} and \emph{convolution-free} 1-Lipschitz architecture for certified robustness. LipNeXt is built using two techniques: (1) a manifold optimization procedure that updates parameters directly on the orthogonal manifold and (2) a \emph{Spatial Shift Module} to model spatial pattern without convolutions. The full network uses orthogonal projections, spatial shifts, a simple 1-Lipschitz $β$-Abs nonlinearity, and $L_2$ spatial pooling to maintain tight Lipschitz control while enabling expressive feature mixing. Across CIFAR-10/100 and Tiny-ImageNet, LipNeXt achieves state-of-the-art clean and certified robust accuracy (CRA), and on ImageNet it scales to 1-2B large models, improving CRA over prior Lipschitz models (e.g., up to $+8\%$ at $\varepsilon{=}1$) while retaining efficient, stable low-precision training. These results demonstrate that Lipschitz-based certification can benefit from modern scaling trends without sacrificing determinism or efficiency.
Physical Prompt Injection Attacks on Large Vision-Language Models
Jan 24, 2026Large Vision-Language Models (LVLMs) are increasingly deployed in real-world intelligent systems for perception and reasoning in open physical environments. While LVLMs are known to be vulnerable to prompt injection attacks, existing methods either require access to input channels or depend on knowledge of user queries, assumptions that rarely hold in practical deployments. We propose the first Physical Prompt Injection Attack (PPIA), a black-box, query-agnostic attack that embeds malicious typographic instructions into physical objects perceivable by the LVLM. PPIA requires no access to the model, its inputs, or internal pipeline, and operates solely through visual observation. It combines offline selection of highly recognizable and semantically effective visual prompts with strategic environment-aware placement guided by spatiotemporal attention, ensuring that the injected prompts are both perceivable and influential on model behavior. We evaluate PPIA across 10 state-of-the-art LVLMs in both simulated and real-world settings on tasks including visual question answering, planning, and navigation, PPIA achieves attack success rates up to 98%, with strong robustness under varying physical conditions such as distance, viewpoint, and illumination. Our code is publicly available at https://github.com/2023cghacker/Physical-Prompt-Injection-Attack.
SAM-Aug: Leveraging SAM Priors for Few-Shot Parcel Segmentation in Satellite Time Series
Jan 14, 2026Few-shot semantic segmentation of time-series remote sensing images remains a critical challenge, particularly in regions where labeled data is scarce or costly to obtain. While state-of-the-art models perform well under full supervision, their performance degrades significantly under limited labeling, limiting their real-world applicability. In this work, we propose SAM-Aug, a new annotation-efficient framework that leverages the geometry-aware segmentation capability of the Segment Anything Model (SAM) to improve few-shot land cover mapping. Our approach constructs cloud-free composite images from temporal sequences and applies SAM in a fully unsupervised manner to generate geometry-aware mask priors. These priors are then integrated into training through a proposed loss function called RegionSmoothLoss, which enforces prediction consistency within each SAM-derived region across temporal frames, effectively regularizing the model to respect semantically coherent structures. Extensive experiments on the PASTIS-R benchmark under a 5 percent labeled setting demonstrate the effectiveness and robustness of SAM-Aug. Averaged over three random seeds (42, 2025, 4090), our method achieves a mean test mIoU of 36.21 percent, outperforming the state-of-the-art baseline by +2.33 percentage points, a relative improvement of 6.89 percent. Notably, on the most favorable split (seed=42), SAM-Aug reaches a test mIoU of 40.28 percent, representing an 11.2 percent relative gain with no additional labeled data. The consistent improvement across all seeds confirms the generalization power of leveraging foundation model priors under annotation scarcity. Our results highlight that vision models like SAM can serve as useful regularizers in few-shot remote sensing learning, offering a scalable and plug-and-play solution for land cover monitoring without requiring manual annotations or model fine-tuning.
ROI-based Deep Image Compression with Implicit Bit Allocation
Nov 12, 2025Region of Interest (ROI)-based image compression has rapidly developed due to its ability to maintain high fidelity in important regions while reducing data redundancy. However, existing compression methods primarily apply masks to suppress background information before quantization. This explicit bit allocation strategy, which uses hard gating, significantly impacts the statistical distribution of the entropy model, thereby limiting the coding performance of the compression model. In response, this work proposes an efficient ROI-based deep image compression model with implicit bit allocation. To better utilize ROI masks for implicit bit allocation, this paper proposes a novel Mask-Guided Feature Enhancement (MGFE) module, comprising a Region-Adaptive Attention (RAA) block and a Frequency-Spatial Collaborative Attention (FSCA) block. This module allows for flexible bit allocation across different regions while enhancing global and local features through frequencyspatial domain collaboration. Additionally, we use dual decoders to separately reconstruct foreground and background images, enabling the coding network to optimally balance foreground enhancement and background quality preservation in a datadriven manner. To the best of our knowledge, this is the first work to utilize implicit bit allocation for high-quality regionadaptive coding. Experiments on the COCO2017 dataset show that our implicit-based image compression method significantly outperforms explicit bit allocation approaches in rate-distortion performance, achieving optimal results while maintaining satisfactory visual quality in the reconstructed background regions.
Inference-Cost-Aware Dynamic Tree Construction for Efficient Inference in Large Language Models
Oct 30, 2025Large Language Models (LLMs) face significant inference latency challenges stemming from their autoregressive design and large size. To address this, speculative decoding emerges as a solution, enabling the simultaneous generation and validation of multiple tokens. While recent approaches like EAGLE-2 and EAGLE-3 improve speculative decoding using dynamic tree structures, they often neglect the impact of crucial system variables such as GPU devices and batch sizes. Therefore, we introduce a new dynamic tree decoding approach called CAST that takes into account inference costs, including factors such as GPU configurations and batch sizes, to dynamically refine the tree structure. Through comprehensive experimentation across six diverse tasks and utilizing six distinct LLMs, our methodology demonstrates remarkable results, achieving speeds up to 5.2 times faster than conventional decoding methods. Moreover, it generally outperforms existing state-of-the-art techniques from 5% to 20%.
Terahertz Channel Measurement and Modeling for Short-Range Indoor Environments
Oct 05, 2025

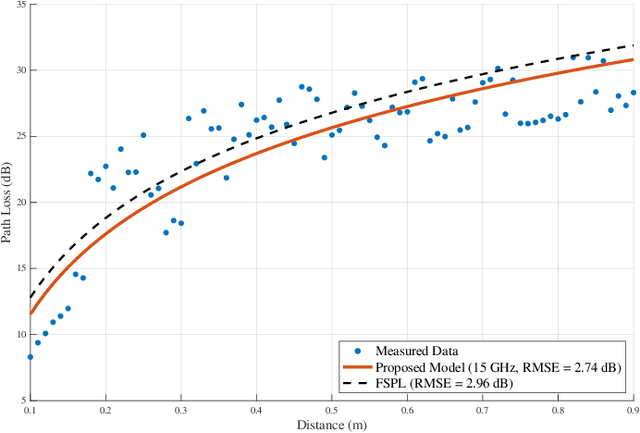

Accurate channel modeling is essential for realizing the potential of terahertz (THz) communications in 6G indoor networks, where existing models struggle with severe frequency selectivity and multipath effects. We propose a physically grounded Rician fading channel model that jointly incorporates deterministic line-of-sight (LOS) and stochastic non-line-of-sight (NLOS) components, enhanced by frequency-dependent attenuation characterized by optimized exponents alpha and beta. Unlike conventional approaches, our model integrates a two-ray reflection framework to capture standing wave phenomena and employs wideband spectral averaging to mitigate frequency selectivity over bandwidths up to 15 GHz. Empirical measurements at a 208 GHz carrier, spanning 0.1-0.9 m, demonstrate that our model achieves root mean square errors (RMSE) as low as 2.54 dB, outperforming free-space path loss (FSPL) by up to 14.2% and reducing RMSE by 73.3% as bandwidth increases. These findings underscore the importance of bandwidth in suppressing oscillatory artifacts and improving modeling accuracy. Our approach provides a robust foundation for THz system design, supporting reliable indoor wireless personal area networks (WPANs), device-to-device (D2D) communications, and precise localization in future 6G applications.
AUV: Teaching Audio Universal Vector Quantization with Single Nested Codebook
Sep 26, 2025We propose AUV, a unified neural audio codec with a single codebook, which enables a favourable reconstruction of speech and further extends to general audio, including vocal, music, and sound. AUV is capable of tackling any 16 kHz mixed-domain audio segment at bit rates around 700 bps. To accomplish this, we guide the matryoshka codebook with nested domain-specific partitions, assigned with corresponding teacher models to perform distillation, all in a single-stage training. A conformer-style encoder-decoder architecture with STFT features as audio representation is employed, yielding better audio quality. Comprehensive evaluations demonstrate that AUV exhibits comparable audio reconstruction ability to state-of-the-art domain-specific single-layer quantizer codecs, showcasing the potential of audio universal vector quantization with a single codebook. The pre-trained model and demo samples are available at https://swivid.github.io/AUV/.
Transferable Adversarial Attacks on Black-Box Vision-Language Models
May 02, 2025



Vision Large Language Models (VLLMs) are increasingly deployed to offer advanced capabilities on inputs comprising both text and images. While prior research has shown that adversarial attacks can transfer from open-source to proprietary black-box models in text-only and vision-only contexts, the extent and effectiveness of such vulnerabilities remain underexplored for VLLMs. We present a comprehensive analysis demonstrating that targeted adversarial examples are highly transferable to widely-used proprietary VLLMs such as GPT-4o, Claude, and Gemini. We show that attackers can craft perturbations to induce specific attacker-chosen interpretations of visual information, such as misinterpreting hazardous content as safe, overlooking sensitive or restricted material, or generating detailed incorrect responses aligned with the attacker's intent. Furthermore, we discover that universal perturbations -- modifications applicable to a wide set of images -- can consistently induce these misinterpretations across multiple proprietary VLLMs. Our experimental results on object recognition, visual question answering, and image captioning show that this vulnerability is common across current state-of-the-art models, and underscore an urgent need for robust mitigations to ensure the safe and secure deployment of VLLMs.
MIG: Automatic Data Selection for Instruction Tuning by Maximizing Information Gain in Semantic Space
Apr 18, 2025Data quality and diversity are key to the construction of effective instruction-tuning datasets. % With the increasing availability of open-source instruction-tuning datasets, it is advantageous to automatically select high-quality and diverse subsets from a vast amount of data. % Existing methods typically prioritize instance quality and use heuristic rules to maintain diversity. % However, this absence of a comprehensive view of the entire collection often leads to suboptimal results. % Moreover, heuristic rules generally focus on distance or clustering within the embedding space, which fails to accurately capture the intent of complex instructions in the semantic space. % To bridge this gap, we propose a unified method for quantifying the information content of datasets. This method models the semantic space by constructing a label graph and quantifies diversity based on the distribution of information within the graph. % Based on such a measurement, we further introduce an efficient sampling method that selects data samples iteratively to \textbf{M}aximize the \textbf{I}nformation \textbf{G}ain (MIG) in semantic space. % Experiments on various datasets and base models demonstrate that MIG consistently outperforms state-of-the-art methods. % Notably, the model fine-tuned with 5\% Tulu3 data sampled by MIG achieves comparable performance to the official SFT model trained on the full dataset, with improvements of +5.73\% on AlpacaEval and +6.89\% on Wildbench.