 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Knowledge from Heterogeneous Architectures for Semantic Segmentation
Apr 10, 2025Current knowledge distillation (KD) methods for semantic segmentation focus on guiding the student to imitate the teacher's knowledge within homogeneous architectures. However, these methods overlook the diverse knowledge contained in architectures with different inductive biases, which is crucial for enabling the student to acquire a more precise and comprehensive understanding of the data during distillation. To this end, we propose for the first time a generic knowledge distillation method for semantic segmentation from a heterogeneous perspective, named HeteroAKD. Due to the substantial disparities between heterogeneous architectures, such as CNN and Transformer, directly transferring cross-architecture knowledge presents significant challenges. To eliminate the influence of architecture-specific information, the intermediate features of both the teacher and student are skillfully projected into an aligned logits space. Furthermore, to utilize diverse knowledge from heterogeneous architectures and deliver customized knowledge required by the student, a teacher-student knowledge mixing mechanism (KMM) and a teacher-student knowledge evaluation mechanism (KEM) are introduced. These mechanisms are performed by assessing the reliability and its discrepancy between heterogeneous teacher-student knowledge. Extensive experiments conducted on three main-stream benchmarks using various teacher-student pairs demonstrate that our HeteroAKD outperforms state-of-the-art KD methods in facilitating distillation between heterogeneous architectures.
Explicit Relational Reasoning Network for Scene Text Detection
Dec 19, 2024
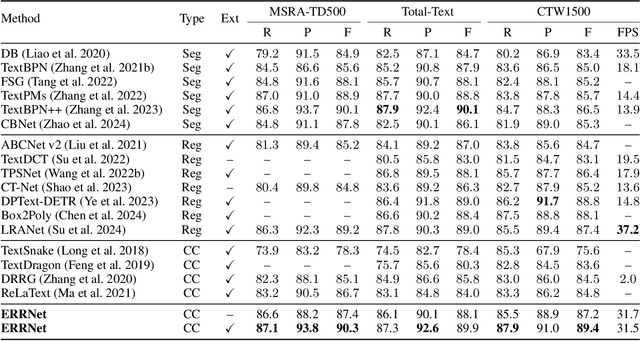

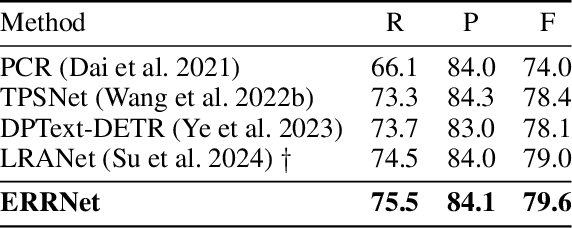
Connected component (CC) is a proper text shape representation that aligns with human reading intuition. However, CC-based text detection methods have recently faced a developmental bottleneck that their time-consuming post-processing is difficult to eliminate. To address this issue, we introduce an explicit relational reasoning network (ERRNet) to elegantly model the component relationships without post-processing. Concretely, we first represent each text instance as multiple ordered text components, and then treat these components as objects in sequential movement. In this way, scene text detection can be innovatively viewed as a tracking problem. From this perspective, we design an end-to-end tracking decoder to achieve a CC-based method dispensing with post-processing entirely. Additionally, we observe that there is an inconsistency between classification confidence and localization quality, so we propose a Polygon Monte-Carlo method to quickly and accurately evaluate the localization quality. Based on this, we introduce a position-supervised classification loss to guide the task-aligned learning of ERRNet. Experiments on challenging benchmarks demonstrate the effectiveness of our ERRNet. It consistently achieves state-of-the-art accuracy while holding highly competitive inference speed.
Multimodal Graph Neural Network for Recommendation with Dynamic De-redundancy and Modality-Guided Feature De-noisy
Nov 03, 2024



Graph neural networks (GNNs) have become crucial in multimodal recommendation tasks because of their powerful ability to capture complex relationships between neighboring nodes. However, increasing the number of propagation layers in GNNs can lead to feature redundancy, which may negatively impact the overall recommendation performance. In addition, the existing recommendation task method directly maps the preprocessed multimodal features to the low-dimensional space, which will bring the noise unrelated to user preference, thus affecting the representation ability of the model. To tackle the aforementioned challenges, we propose Multimodal Graph Neural Network for Recommendation (MGNM) with Dynamic De-redundancy and Modality-Guided Feature De-noisy, which is divided into local and global interaction. Initially, in the local interaction process,we integrate a dynamic de-redundancy (DDR) loss function which is achieved by utilizing the product of the feature coefficient matrix and the feature matrix as a penalization factor. It reduces the feature redundancy effects of multimodal and behavioral features caused by the stacking of multiple GNN layers. Subsequently, in the global interaction process, we developed modality-guided global feature purifiers for each modality to alleviate the impact of modality noise. It is a two-fold guiding mechanism eliminating modality features that are irrelevant to user preferences and captures complex relationships within the modality. Experimental results demonstrate that MGNM achieves superior performance on multimodal information denoising and removal of redundant information compared to the state-of-the-art methods.
Out of Length Text Recognition with Sub-String Matching
Jul 17, 2024



Scene Text Recognition (STR) methods have demonstrated robust performance in word-level text recognition. However, in applications the text image is sometimes long due to detected with multiple horizontal words. It triggers the requirement to build long text recognition models from readily available short word-level text datasets, which has been less studied previously. In this paper, we term this the Out of Length (OOL) text recognition. We establish a new Long Text Benchmark (LTB) to facilitate the assessment of different methods in long text recognition. Meanwhile, we propose a novel method called OOL Text Recognition with sub-String Matching (SMTR). SMTR comprises two cross-attention-based modules: one encodes a sub-string containing multiple characters into next and previous queries, and the other employs the queries to attend to the image features, matching the sub-string and simultaneously recognizing its next and previous character. SMTR can recognize text of arbitrary length by iterating the process above. To avoid being trapped in recognizing highly similar sub-strings, we introduce a regularization training to compel SMTR to effectively discover subtle differences between similar sub-strings for precise matching. In addition, we propose an inference augmentation to alleviate confusion caused by identical sub-strings and improve the overall recognition efficiency. Extensive experimental results reveal that SMTR, even when trained exclusively on short text, outperforms existing methods in public short text benchmarks and exhibits a clear advantage on LTB. Code: \url{https://github.com/Topdu/OpenOCR}.
Learning to Rank Patches for Unbiased Image Redundancy Reduction
Mar 31, 2024



Images suffer from heavy spatial redundancy because pixels in neighboring regions are spatially correlated. Existing approaches strive to overcome this limitation by reducing less meaningful image regions. However, current leading methods rely on supervisory signals. They may compel models to preserve content that aligns with labeled categories and discard content belonging to unlabeled categories. This categorical inductive bias makes these methods less effective in real-world scenarios. To address this issue, we propose a self-supervised framework for image redundancy reduction called Learning to Rank Patches (LTRP). We observe that image reconstruction of masked image modeling models is sensitive to the removal of visible patches when the masking ratio is high (e.g., 90\%). Building upon it, we implement LTRP via two steps: inferring the semantic density score of each patch by quantifying variation between reconstructions with and without this patch, and learning to rank the patches with the pseudo score. The entire process is self-supervised, thus getting out of the dilemma of categorical inductive bias. We design extensive experiments on different datasets and tasks. The results demonstrate that LTRP outperforms both supervised and other self-supervised methods due to the fair assessment of image content.
Self-distillation Augmented Masked Autoencoders for Histopathological Image Classification
Mar 31, 2022
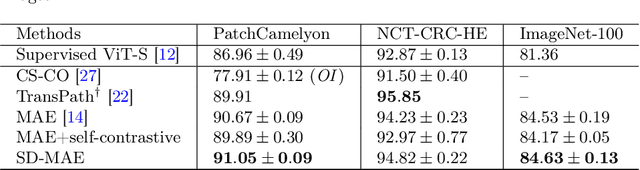


Self-supervised learning (SSL) has drawn increasing attention in pathological image analysis in recent years. However, the prevalent contrastive SSL is suboptimal in feature representation under this scenario due to the homogeneous visual appearance. Alternatively, masked autoencoders (MAE) build SSL from a generative paradigm. They are more friendly to pathological image modeling. In this paper, we firstly introduce MAE to pathological image analysis. A novel SD-MAE model is proposed to enable a self-distillation augmented SSL on top of the raw MAE. Besides the reconstruction loss on masked image patches, SD-MAE further imposes the self-distillation loss on visible patches. It guides the encoder to perceive high-level semantics that benefit downstream tasks. We apply SD-MAE to the image classification task on two pathological and one natural image datasets. Experiments demonstrate that SD-MAE performs highly competitive when compared with leading contrastive SSL methods. The results, which are pre-trained using a moderate size of pathological images, are also comparable to the method pre-trained with two orders of magnitude more images. Our code will be released soon.
MSDNN: Multi-Scale Deep Neural Network for Salient Object Detection
Jan 12, 2018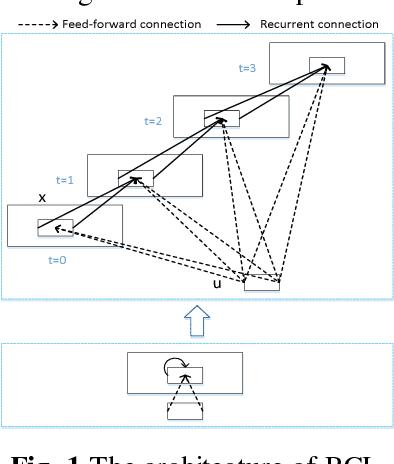
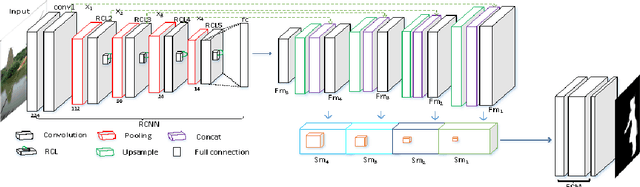
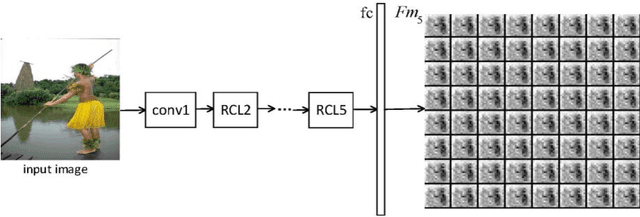

Salient object detection is a fundamental problem and has been received a great deal of attentions in computer vision. Recently deep learning model became a powerful tool for image feature extraction. In this paper, we propose a multi-scale deep neural network (MSDNN) for salient object detection. The proposed model first extracts global high-level features and context information over the whole source image with recurrent convolutional neural network (RCNN). Then several stacked deconvolutional layers are adopted to get the multi-scale feature representation and obtain a series of saliency maps. Finally, we investigate a fusion convolution module (FCM) to build a final pixel level saliency map. The proposed model is extensively evaluated on four salient object detection benchmark datasets. Results show that our deep model significantly outperforms other 12 state-of-the-art approaches.