 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Is Wrong with Synthetic Data for Scene Text Recognition? A Strong Synthetic Engine with Diverse Simulations and Self-Evolution
Feb 06, 2026Large-scale and categorical-balanced text data is essential for training effective Scene Text Recognition (STR) models, which is hard to achieve when collecting real data. Synthetic data offers a cost-effective and perfectly labeled alternative. However, its performance often lags behind, revealing a significant domain gap between real and current synthetic data. In this work, we systematically analyze mainstream rendering-based synthetic datasets and identify their key limitations: insufficient diversity in corpus, font, and layout, which restricts their realism in complex scenarios. To address these issues, we introduce UnionST, a strong data engine synthesizes text covering a union of challenging samples and better aligns with the complexity observed in the wild. We then construct UnionST-S, a large-scale synthetic dataset with improved simulations in challenging scenarios. Furthermore, we develop a self-evolution learning (SEL) framework for effective real data annotation. Experiments show that models trained on UnionST-S achieve significant improvements over existing synthetic datasets. They even surpass real-data performance in certain scenarios. Moreover, when using SEL, the trained models achieve competitive performance by only seeing 9% of real data labels.
Dolphin-v2: Universal Document Parsing via Scalable Anchor Prompting
Feb 05, 2026Document parsing has garnered widespread attention as vision-language models (VLMs) advance OCR capabilities. However, the field remains fragmented across dozens of specialized models with varying strengths, forcing users to navigate complex model selection and limiting system scalability. Moreover, existing two-stage approaches depend on axis-aligned bounding boxes for layout detection, failing to handle distorted or photographed documents effectively. To this end, we present Dolphin-v2, a two-stage document image parsing model that substantially improves upon the original Dolphin. In the first stage, Dolphin-v2 jointly performs document type classification (digital-born versus photographed) alongside layout analysis. For digital-born documents, it conducts finer-grained element detection with reading order prediction. In the second stage, we employ a hybrid parsing strategy: photographed documents are parsed holistically as complete pages to handle geometric distortions, while digital-born documents undergo element-wise parallel parsing guided by the detected layout anchors, enabling efficient content extraction. Compared with the original Dolphin, Dolphin-v2 introduces several crucial enhancements: (1) robust parsing of photographed documents via holistic page-level understanding, (2) finer-grained element detection (21 categories) with semantic attribute extraction such as author information and document metadata, and (3) code block recognition with indentation preservation, which existing systems typically lack. Comprehensive evaluations are conducted on DocPTBench, OmniDocBench, and our self-constructed RealDoc-160 benchmark. The results demonstrate substantial improvements: +14.78 points overall on the challenging OmniDocBench and 91% error reduction on photographed documents, while maintaining efficient inference through parallel processing.
UniRec-0.1B: Unified Text and Formula Recognition with 0.1B Parameters
Dec 24, 2025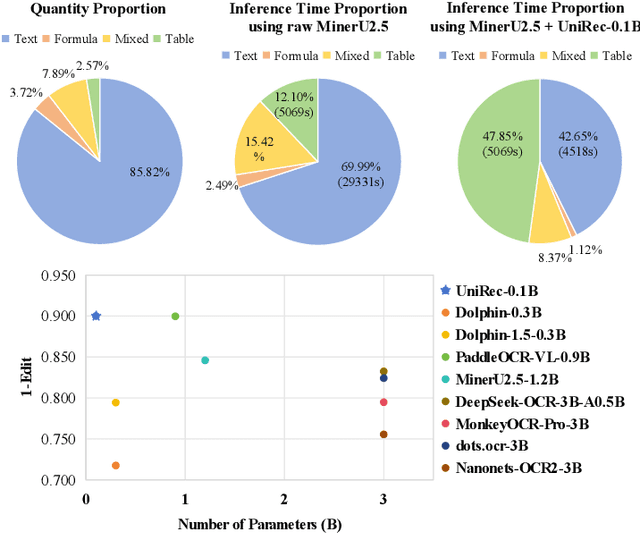

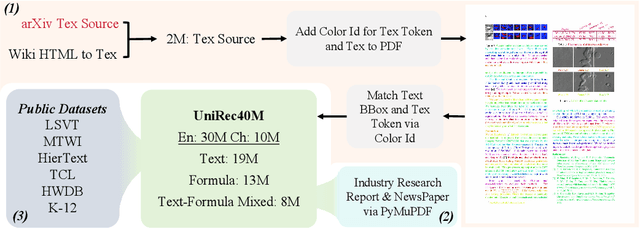
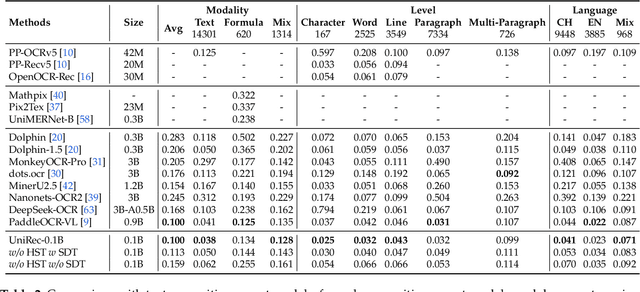
Text and formulas constitute the core informational components of many documents. Accurately and efficiently recognizing both is crucial for developing robust and generalizable document parsing systems. Recently, vision-language models (VLMs) have achieved impressive unified recognition of text and formulas. However, they are large-sized and computationally demanding, restricting their usage in many applications. In this paper, we propose UniRec-0.1B, a unified recognition model with only 0.1B parameters. It is capable of performing text and formula recognition at multiple levels, including characters, words, lines, paragraphs, and documents. To implement this task, we first establish UniRec40M, a large-scale dataset comprises 40 million text, formula and their mix samples, enabling the training of a powerful yet lightweight model. Secondly, we identify two challenges when building such a lightweight but unified expert model. They are: structural variability across hierarchies and semantic entanglement between textual and formulaic content. To tackle these, we introduce a hierarchical supervision training that explicitly guides structural comprehension, and a semantic-decoupled tokenizer that separates text and formula representations. Finally, we develop a comprehensive evaluation benchmark covering Chinese and English documents from multiple domains and with multiple levels. Experimental results on this and public benchmarks demonstrate that UniRec-0.1B outperforms both general-purpose VLMs and leading document parsing expert models, while achieving a 2-9$\times$ speedup, validating its effectiveness and efficiency. Codebase and Dataset: https://github.com/Topdu/OpenOCR.
Complex Mathematical Expression Recognition: Benchmark, Large-Scale Dataset and Strong Baseline
Dec 14, 2025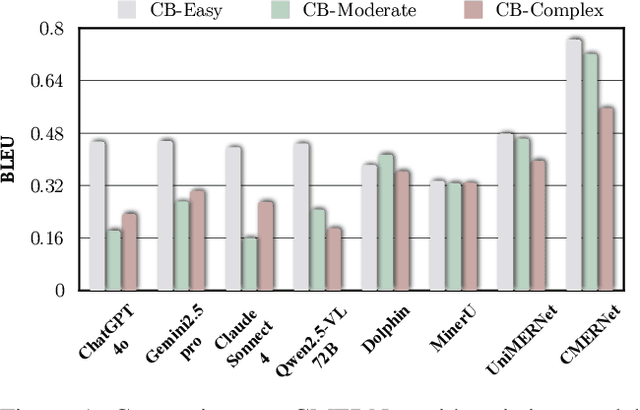
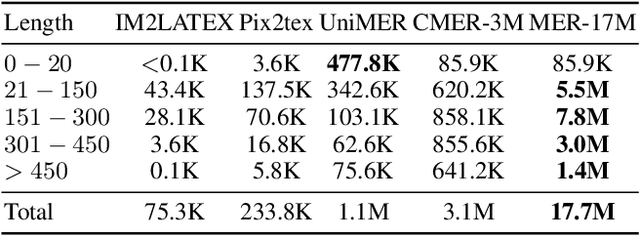

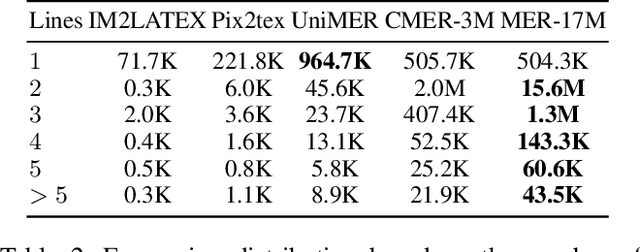
Mathematical Expression Recognition (MER) has made significant progress in recognizing simple expressions, but the robust recognition of complex mathematical expressions with many tokens and multiple lines remains a formidable challenge. In this paper, we first introduce CMER-Bench, a carefully constructed benchmark that categorizes expressions into three difficulty levels: easy, moderate, and complex. Leveraging CMER-Bench, we conduct a comprehensive evaluation of existing MER models and general-purpose multimodal large language models (MLLMs). The results reveal that while current methods perform well on easy and moderate expressions, their performance degrades significantly when handling complex mathematical expressions, mainly because existing public training datasets are primarily composed of simple samples. In response, we propose MER-17M and CMER-3M that are large-scale datasets emphasizing the recognition of complex mathematical expressions. The datasets provide rich and diverse samples to support the development of accurate and robust complex MER models. Furthermore, to address the challenges posed by the complicated spatial layout of complex expressions, we introduce a novel expression tokenizer, and a new representation called Structured Mathematical Language, which explicitly models the hierarchical and spatial structure of expressions beyond LaTeX format. Based on these, we propose a specialized model named CMERNet, built upon an encoder-decoder architecture and trained on CMER-3M. Experimental results show that CMERNet, with only 125 million parameters, significantly outperforms existing MER models and MLLMs on CMER-Bench.
LRANet++: Low-Rank Approximation Network for Accurate and Efficient Text Spotting
Nov 08, 2025End-to-end text spotting aims to jointly optimize text detection and recognition within a unified framework. Despite significant progress, designing an accurate and efficient end-to-end text spotter for arbitrary-shaped text remains largely unsolved. We identify the primary bottleneck as the lack of a reliable and efficient text detection method. To address this, we propose a novel parameterized text shape method based on low-rank approximation for precise detection and a triple assignment detection head to enable fast inference. Specifically, unlike other shape representation methods that employ data-irrelevant parameterization, our data-driven approach derives a low-rank subspace directly from labeled text boundaries. To ensure this process is robust against the inherent annotation noise in this data, we utilize a specialized recovery method based on an $\ell_1$-norm formulation, which accurately reconstructs the text shape with only a few key orthogonal vectors. By exploiting the inherent shape correlation among different text contours, our method achieves consistency and compactness in shape representation. Next, the triple assignment scheme introduces a novel architecture where a deep sparse branch (for stabilized training) is used to guide the learning of an ultra-lightweight sparse branch (for accelerated inference), while a dense branch provides rich parallel supervision. Building upon these advancements, we integrate the enhanced detection module with a lightweight recognition branch to form an end-to-end text spotting framework, termed LRANet++, capable of accurately and efficiently spotting arbitrary-shaped text. Extensive experiments on several challenging benchmarks demonstrate the superiority of LRANet++ compared to state-of-the-art methods. Code will be available at: https://github.com/ychensu/LRANet-PP.git
Explicit Relational Reasoning Network for Scene Text Detection
Dec 19, 2024
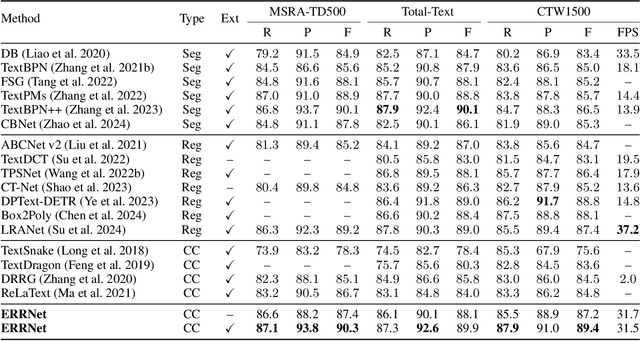

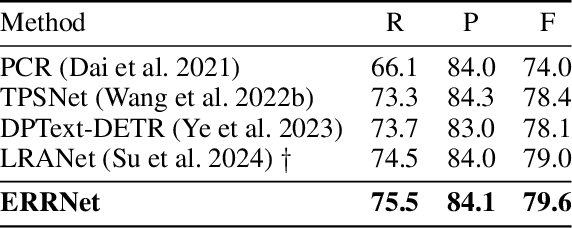
Connected component (CC) is a proper text shape representation that aligns with human reading intuition. However, CC-based text detection methods have recently faced a developmental bottleneck that their time-consuming post-processing is difficult to eliminate. To address this issue, we introduce an explicit relational reasoning network (ERRNet) to elegantly model the component relationships without post-processing. Concretely, we first represent each text instance as multiple ordered text components, and then treat these components as objects in sequential movement. In this way, scene text detection can be innovatively viewed as a tracking problem. From this perspective, we design an end-to-end tracking decoder to achieve a CC-based method dispensing with post-processing entirely. Additionally, we observe that there is an inconsistency between classification confidence and localization quality, so we propose a Polygon Monte-Carlo method to quickly and accurately evaluate the localization quality. Based on this, we introduce a position-supervised classification loss to guide the task-aligned learning of ERRNet. Experiments on challenging benchmarks demonstrate the effectiveness of our ERRNet. It consistently achieves state-of-the-art accuracy while holding highly competitive inference speed.
TextSSR: Diffusion-based Data Synthesis for Scene Text Recognition
Dec 02, 2024



Scene text recognition (STR) suffers from the challenges of either less realistic synthetic training data or the difficulty of collecting sufficient high-quality real-world data, limiting the effectiveness of trained STR models. Meanwhile, despite producing holistically appealing text images, diffusion-based text image generation methods struggle to generate accurate and realistic instance-level text on a large scale. To tackle this, we introduce TextSSR: a novel framework for Synthesizing Scene Text Recognition data via a diffusion-based universal text region synthesis model. It ensures accuracy by focusing on generating text within a specified image region and leveraging rich glyph and position information to create the less complex text region compared to the entire image. Furthermore, we utilize neighboring text within the region as a prompt to capture real-world font styles and layout patterns, guiding the generated text to resemble actual scenes. Finally, due to its prompt-free nature and capability for character-level synthesis, TextSSR enjoys a wonderful scalability and we construct an anagram-based TextSSR-F dataset with 0.4 million text instances with complexity and realism. Experiments show that models trained on added TextSSR-F data exhibit better accuracy compared to models trained on 4 million existing synthetic data. Moreover, its accuracy margin to models trained fully on a real-world dataset is less than 3.7%, confirming TextSSR's effectiveness and its great potential in scene text image synthesis. Our code is available at https://github.com/YesianRohn/TextSSR.
SVTRv2: CTC Beats Encoder-Decoder Models in Scene Text Recognition
Nov 24, 2024Connectionist temporal classification (CTC)-based scene text recognition (STR) methods, e.g., SVTR, are widely employed in OCR applications, mainly due to their simple architecture, which only contains a visual model and a CTC-aligned linear classifier, and therefore fast inference. However, they generally have worse accuracy than encoder-decoder-based methods (EDTRs), particularly in challenging scenarios. In this paper, we propose SVTRv2, a CTC model that beats leading EDTRs in both accuracy and inference speed. SVTRv2 introduces novel upgrades to handle text irregularity and utilize linguistic context, which endows it with the capability to deal with challenging and diverse text instances. First, a multi-size resizing (MSR) strategy is proposed to adaptively resize the text and maintain its readability. Meanwhile, we introduce a feature rearrangement module (FRM) to ensure that visual features accommodate the alignment requirement of CTC well, thus alleviating the alignment puzzle. Second, we propose a semantic guidance module (SGM). It integrates linguistic context into the visual model, allowing it to leverage language information for improved accuracy. Moreover, SGM can be omitted at the inference stage and would not increase the inference cost. We evaluate SVTRv2 in both standard and recent challenging benchmarks, where SVTRv2 is fairly compared with 24 mainstream STR models across multiple scenarios, including different types of text irregularity, languages, and long text. The results indicate that SVTRv2 surpasses all the EDTRs across the scenarios in terms of accuracy and speed. Code is available at https://github.com/Topdu/OpenOCR.
Decoder Pre-Training with only Text for Scene Text Recognition
Aug 11, 2024



Scene text recognition (STR) pre-training methods have achieved remarkable progress, primarily relying on synthetic datasets. However, the domain gap between synthetic and real images poses a challenge in acquiring feature representations that align well with images on real scenes, thereby limiting the performance of these methods. We note that vision-language models like CLIP, pre-trained on extensive real image-text pairs, effectively align images and text in a unified embedding space, suggesting the potential to derive the representations of real images from text alone. Building upon this premise, we introduce a novel method named Decoder Pre-training with only text for STR (DPTR). DPTR treats text embeddings produced by the CLIP text encoder as pseudo visual embeddings and uses them to pre-train the decoder. An Offline Randomized Perturbation (ORP) strategy is introduced. It enriches the diversity of text embeddings by incorporating natural image embeddings extracted from the CLIP image encoder, effectively directing the decoder to acquire the potential representations of real images. In addition, we introduce a Feature Merge Unit (FMU) that guides the extracted visual embeddings focusing on the character foreground within the text image, thereby enabling the pre-trained decoder to work more efficiently and accurately. Extensive experiments across various STR decoders and language recognition tasks underscore the broad applicability and remarkable performance of DPTR, providing a novel insight for STR pre-training. Code is available at https://github.com/Topdu/OpenOCR
Out of Length Text Recognition with Sub-String Matching
Jul 17, 2024



Scene Text Recognition (STR) methods have demonstrated robust performance in word-level text recognition. However, in applications the text image is sometimes long due to detected with multiple horizontal words. It triggers the requirement to build long text recognition models from readily available short word-level text datasets, which has been less studied previously. In this paper, we term this the Out of Length (OOL) text recognition. We establish a new Long Text Benchmark (LTB) to facilitate the assessment of different methods in long text recognition. Meanwhile, we propose a novel method called OOL Text Recognition with sub-String Matching (SMTR). SMTR comprises two cross-attention-based modules: one encodes a sub-string containing multiple characters into next and previous queries, and the other employs the queries to attend to the image features, matching the sub-string and simultaneously recognizing its next and previous character. SMTR can recognize text of arbitrary length by iterating the process above. To avoid being trapped in recognizing highly similar sub-strings, we introduce a regularization training to compel SMTR to effectively discover subtle differences between similar sub-strings for precise matching. In addition, we propose an inference augmentation to alleviate confusion caused by identical sub-strings and improve the overall recognition efficiency. Extensive experimental results reveal that SMTR, even when trained exclusively on short text, outperforms existing methods in public short text benchmarks and exhibits a clear advantage on LTB. Code: \url{https://github.com/Topdu/OpenOCR}.