 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoEvGesture: Gesture Recognition Based on Egocentric Event Camera
Mar 16, 2025
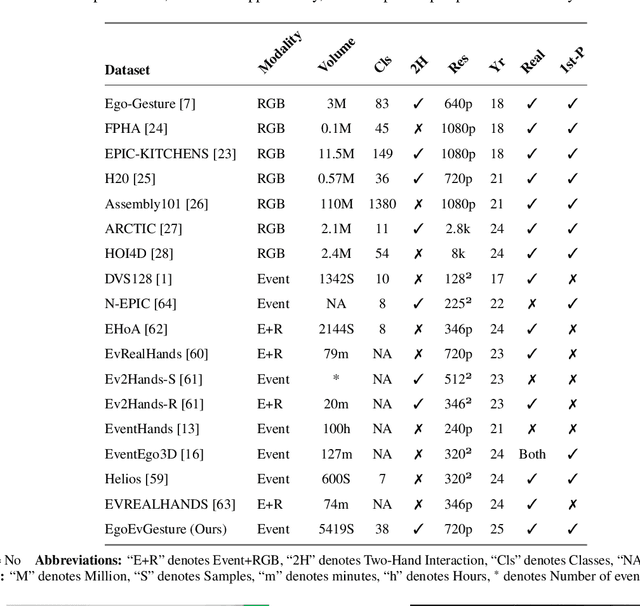
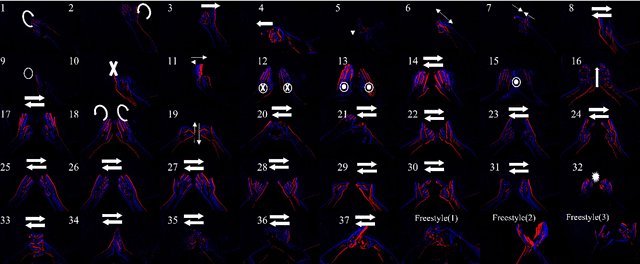
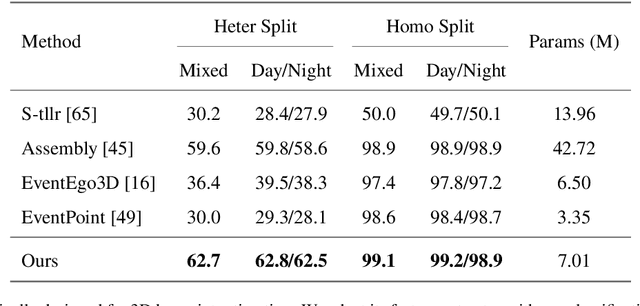
Egocentric gesture recognition is a pivotal technology for enhancing natural human-computer interaction, yet traditional RGB-based solutions suffer from motion blur and illumination variations in dynamic scenarios. While event cameras show distinct advantages in handling high dynamic range with ultra-low power consumption, existing RGB-based architectures face inherent limitations in processing asynchronous event streams due to their synchronous frame-based nature. Moreover, from an egocentric perspective, event cameras record data that include events generated by both head movements and hand gestures, thereby increasing the complexity of gesture recognition. To address this, we propose a novel network architecture specifically designed for event data processing, incorporating (1) a lightweight CNN with asymmetric depthwise convolutions to reduce parameters while preserving spatiotemporal features, (2) a plug-and-play state-space model as context block that decouples head movement noise from gesture dynamics, and (3) a parameter-free Bins-Temporal Shift Module (BSTM) that shifts features along bins and temporal dimensions to fuse sparse events efficiently. We further build the EgoEvGesture dataset, the first large-scale dataset for egocentric gesture recognition using event cameras. Experimental results demonstrate that our method achieves 62.7% accuracy in heterogeneous testing with only 7M parameters, 3.1% higher than state-of-the-art approaches. Notable misclassifications in freestyle motions stem from high inter-personal variability and unseen test patterns differing from training data. Moreover, our approach achieved a remarkable accuracy of 96.97% on DVS128 Gesture, demonstrating strong cross-dataset generalization capability. The dataset and models are made publicly available at https://github.com/3190105222/EgoEv_Gesture.
Event-aided Semantic Scene Completion
Feb 04, 2025



Autonomous driving systems rely on robust 3D scene understanding. Recent advances in Semantic Scene Completion (SSC) for autonomous driving underscore the limitations of RGB-based approaches, which struggle under motion blur, poor lighting, and adverse weather. Event cameras, offering high dynamic range and low latency, address these challenges by providing asynchronous data that complements RGB inputs. We present DSEC-SSC, the first real-world benchmark specifically designed for event-aided SSC, which includes a novel 4D labeling pipeline for generating dense, visibility-aware labels that adapt dynamically to object motion. Our proposed RGB-Event fusion framework, EvSSC, introduces an Event-aided Lifting Module (ELM) that effectively bridges 2D RGB-Event features to 3D space, enhancing view transformation and the robustness of 3D volume construction across SSC models. Extensive experiments on DSEC-SSC and simulated SemanticKITTI-E demonstrate that EvSSC is adaptable to both transformer-based and LSS-based SSC architectures. Notably, evaluations on SemanticKITTI-C demonstrate that EvSSC achieves consistently improved prediction accuracy across five degradation modes and both In-domain and Out-of-domain settings, achieving up to a 52.5% relative improvement in mIoU when the image sensor partially fails. Additionally, we quantitatively and qualitatively validate the superiority of EvSSC under motion blur and extreme weather conditions, where autonomous driving is challenged. The established datasets and our codebase will be made publicly at https://github.com/Pandapan01/EvSSC.
E-3DGS: Gaussian Splatting with Exposure and Motion Events
Oct 22, 2024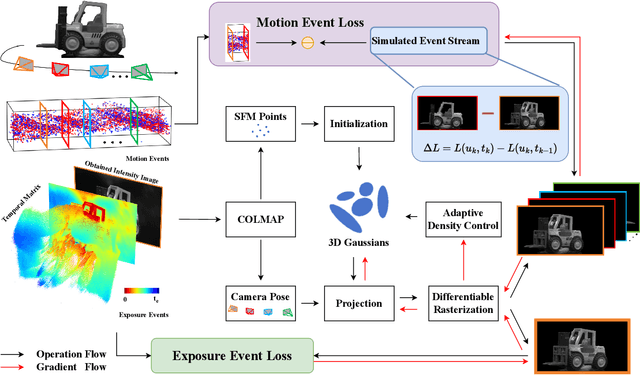

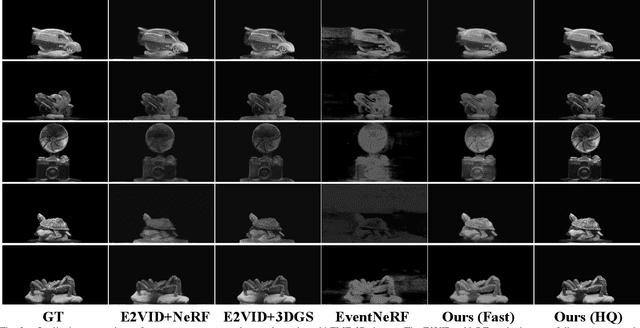
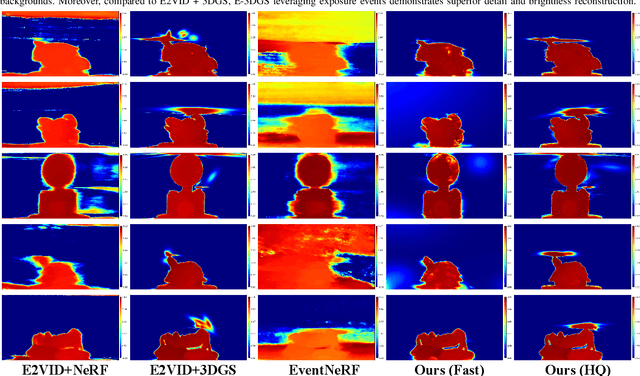
Estimating Neural Radiance Fields (NeRFs) from images captured under optimal conditions has been extensively explored in the vision community. However, robotic applications often face challenges such as motion blur, insufficient illumination, and high computational overhead, which adversely affect downstream tasks like navigation, inspection, and scene visualization. To address these challenges, we propose E-3DGS, a novel event-based approach that partitions events into motion (from camera or object movement) and exposure (from camera exposure), using the former to handle fast-motion scenes and using the latter to reconstruct grayscale images for high-quality training and optimization of event-based 3D Gaussian Splatting (3DGS). We introduce a novel integration of 3DGS with exposure events for high-quality reconstruction of explicit scene representations. Our versatile framework can operate on motion events alone for 3D reconstruction, enhance quality using exposure events, or adopt a hybrid mode that balances quality and effectiveness by optimizing with initial exposure events followed by high-speed motion events. We also introduce EME-3D, a real-world 3D dataset with exposure events, motion events, camera calibration parameters, and sparse point clouds. Our method is faster and delivers better reconstruction quality than event-based NeRF while being more cost-effective than NeRF methods that combine event and RGB data by using a single event sensor. By combining motion and exposure events, E-3DGS sets a new benchmark for event-based 3D reconstruction with robust performance in challenging conditions and lower hardware demands. The source code and dataset will be available at https://github.com/MasterHow/E-3DGS.
OccFiner: Offboard Occupancy Refinement with Hybrid Propagation
Mar 15, 2024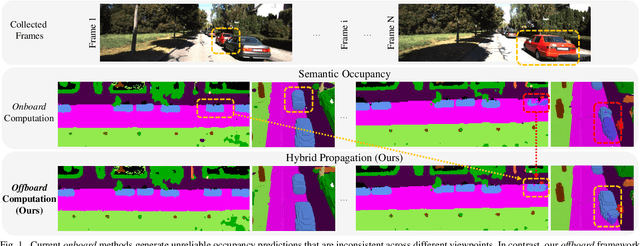

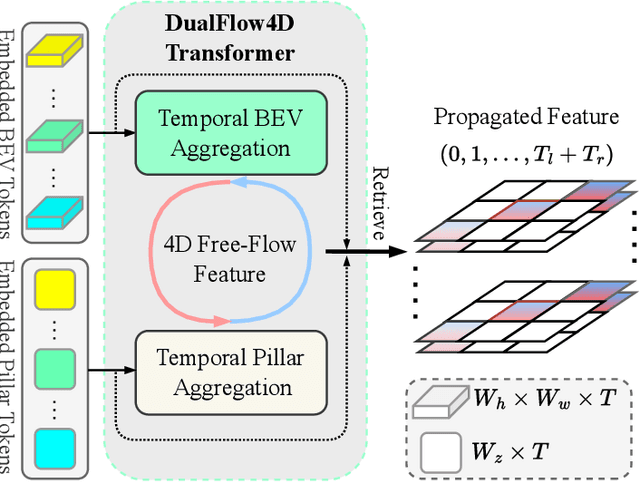
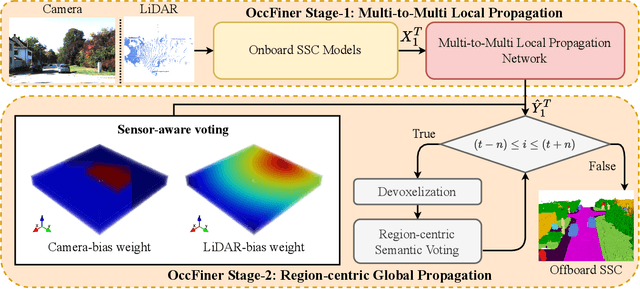
Vision-based occupancy prediction, also known as 3D Semantic Scene Completion (SSC), presents a significant challenge in computer vision. Previous methods, confined to onboard processing, struggle with simultaneous geometric and semantic estimation, continuity across varying viewpoints, and single-view occlusion. Our paper introduces OccFiner, a novel offboard framework designed to enhance the accuracy of vision-based occupancy predictions. OccFiner operates in two hybrid phases: 1) a multi-to-multi local propagation network that implicitly aligns and processes multiple local frames for correcting onboard model errors and consistently enhancing occupancy accuracy across all distances. 2) the region-centric global propagation, focuses on refining labels using explicit multi-view geometry and integrating sensor bias, especially to increase the accuracy of distant occupied voxels. Extensive experiments demonstrate that OccFiner improves both geometric and semantic accuracy across various types of coarse occupancy, setting a new state-of-the-art performance on the SemanticKITTI dataset. Notably, OccFiner elevates vision-based SSC models to a level even surpassing that of LiDAR-based onboard SSC models.
Towards Precise 3D Human Pose Estimation with Multi-Perspective Spatial-Temporal Relational Transformers
Jan 30, 2024



3D human pose estimation captures the human joint points in three-dimensional space while keeping the depth information and physical structure. That is essential for applications that require precise pose information, such as human-computer interaction, scene understanding, and rehabilitation training. Due to the challenges in data collection, mainstream datasets of 3D human pose estimation are primarily composed of multi-view video data collected in laboratory environments, which contains rich spatial-temporal correlation information besides the image frame content. Given the remarkable self-attention mechanism of transformers, capable of capturing the spatial-temporal correlation from multi-view video datasets, we propose a multi-stage framework for 3D sequence-to-sequence (seq2seq) human pose detection. Firstly, the spatial module represents the human pose feature by intra-image content, while the frame-image relation module extracts temporal relationships and 3D spatial positional relationship features between the multi-perspective images. Secondly, the self-attention mechanism is adopted to eliminate the interference from non-human body parts and reduce computing resources. Our method is evaluated on Human3.6M, a popular 3D human pose detection dataset. Experimental results demonstrate that our approach achieves state-of-the-art performance on this dataset.
Rethinking Human Pose Estimation for Autonomous Driving with 3D Event Representations
Nov 09, 2023Human pose estimation is a critical component in autonomous driving and parking, enhancing safety by predicting human actions. Traditional frame-based cameras and videos are commonly applied, yet, they become less reliable in scenarios under high dynamic range or heavy motion blur. In contrast, event cameras offer a robust solution for navigating these challenging contexts. Predominant methodologies incorporate event cameras into learning frameworks by accumulating events into event frames. However, such methods tend to marginalize the intrinsic asynchronous and high temporal resolution characteristics of events. This disregard leads to a loss in essential temporal dimension data, crucial for safety-critical tasks associated with dynamic human activities. To address this issue and to unlock the 3D potential of event information, we introduce two 3D event representations: the Rasterized Event Point Cloud (RasEPC) and the Decoupled Event Voxel (DEV). The RasEPC collates events within concise temporal slices at identical positions, preserving 3D attributes with statistical cues and markedly mitigating memory and computational demands. Meanwhile, the DEV representation discretizes events into voxels and projects them across three orthogonal planes, utilizing decoupled event attention to retrieve 3D cues from the 2D planes. Furthermore, we develop and release EV-3DPW, a synthetic event-based dataset crafted to facilitate training and quantitative analysis in outdoor scenes. On the public real-world DHP19 dataset, our event point cloud technique excels in real-time mobile predictions, while the decoupled event voxel method achieves the highest accuracy. Experiments reveal our proposed 3D representation methods' superior generalization capacities against traditional RGB images and event frame techniques. Our code and dataset are available at https://github.com/MasterHow/EventPointPose.
Context Perception Parallel Decoder for Scene Text Recognition
Jul 23, 2023



Scene text recognition (STR) methods have struggled to attain high accuracy and fast inference speed. Autoregressive (AR)-based STR model uses the previously recognized characters to decode the next character iteratively. It shows superiority in terms of accuracy. However, the inference speed is slow also due to this iteration. Alternatively, parallel decoding (PD)-based STR model infers all the characters in a single decoding pass. It has advantages in terms of inference speed but worse accuracy, as it is difficult to build a robust recognition context in such a pass. In this paper, we first present an empirical study of AR decoding in STR. In addition to constructing a new AR model with the top accuracy, we find out that the success of AR decoder lies also in providing guidance on visual context perception rather than language modeling as claimed in existing studies. As a consequence, we propose Context Perception Parallel Decoder (CPPD) to decode the character sequence in a single PD pass. CPPD devises a character counting module and a character ordering module. Given a text instance, the former infers the occurrence count of each character, while the latter deduces the character reading order and placeholders. Together with the character prediction task, they construct a context that robustly tells what the character sequence is and where the characters appear, well mimicking the context conveyed by AR decoding. Experiments on both English and Chinese benchmarks demonstrate that CPPD models achieve highly competitive accuracy. Moreover, they run approximately 7x faster than their AR counterparts, and are also among the fastest recognizers. The code will be released soon.
Towards Anytime Optical Flow Estimation with Event Cameras
Jul 11, 2023



Event cameras are capable of responding to log-brightness changes in microseconds. Its characteristic of producing responses only to the changing region is particularly suitable for optical flow estimation. In contrast to the super low-latency response speed of event cameras, existing datasets collected via event cameras, however, only provide limited frame rate optical flow ground truth, (e.g., at 10Hz), greatly restricting the potential of event-driven optical flow. To address this challenge, we put forward a high-frame-rate, low-latency event representation Unified Voxel Grid, sequentially fed into the network bin by bin. We then propose EVA-Flow, an EVent-based Anytime Flow estimation network to produce high-frame-rate event optical flow with only low-frame-rate optical flow ground truth for supervision. The key component of our EVA-Flow is the stacked Spatiotemporal Motion Refinement (SMR) module, which predicts temporally-dense optical flow and enhances the accuracy via spatial-temporal motion refinement. The time-dense feature warping utilized in the SMR module provides implicit supervision for the intermediate optical flow. Additionally, we introduce the Rectified Flow Warp Loss (RFWL) for the unsupervised evaluation of intermediate optical flow in the absence of ground truth. This is, to the best of our knowledge, the first work focusing on anytime optical flow estimation via event cameras. A comprehensive variety of experiments on MVSEC, DESC, and our EVA-FlowSet demonstrates that EVA-Flow achieves competitive performance, super-low-latency (5ms), fastest inference (9.2ms), time-dense motion estimation (200Hz), and strong generalization. Our code will be available at https://github.com/Yaozhuwa/EVA-Flow.
FlowLens: Seeing Beyond the FoV via Flow-guided Clip-Recurrent Transformer
Nov 21, 2022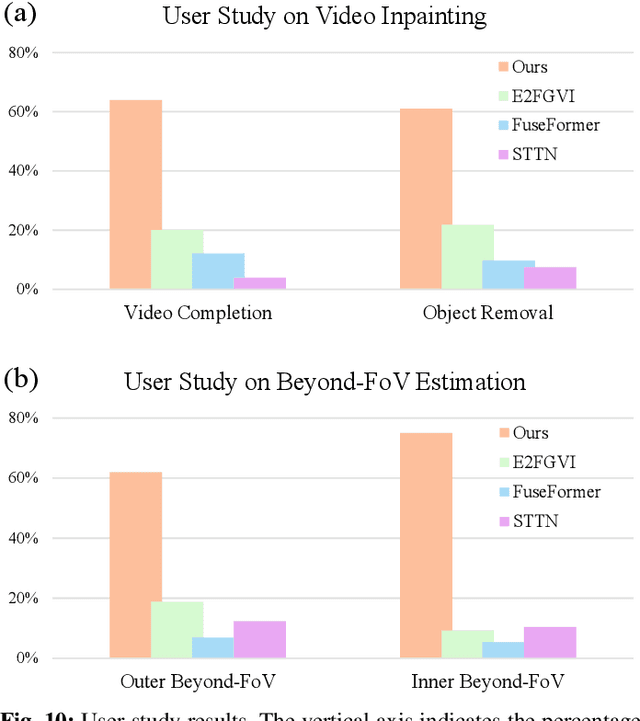


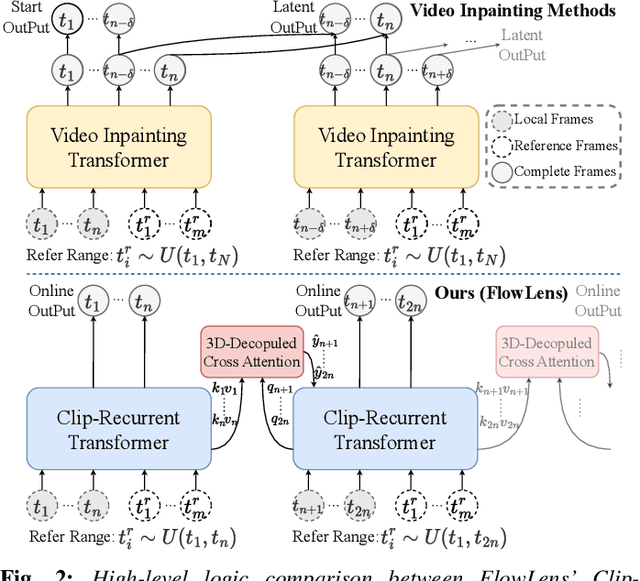
Limited by hardware cost and system size, camera's Field-of-View (FoV) is not always satisfactory. However, from a spatio-temporal perspective, information beyond the camera's physical FoV is off-the-shelf and can actually be obtained "for free" from the past. In this paper, we propose a novel task termed Beyond-FoV Estimation, aiming to exploit past visual cues and bidirectional break through the physical FoV of a camera. We put forward a FlowLens architecture to expand the FoV by achieving feature propagation explicitly by optical flow and implicitly by a novel clip-recurrent transformer, which has two appealing features: 1) FlowLens comprises a newly proposed Clip-Recurrent Hub with 3D-Decoupled Cross Attention (DDCA) to progressively process global information accumulated in the temporal dimension. 2) A multi-branch Mix Fusion Feed Forward Network (MixF3N) is integrated to enhance the spatially-precise flow of local features. To foster training and evaluation, we establish KITTI360-EX, a dataset for outer- and inner FoV expansion. Extensive experiments on both video inpainting and beyond-FoV estimation tasks show that FlowLens achieves state-of-the-art performance. Code will be made publicly available at https://github.com/MasterHow/FlowLens.
PP-OCRv3: More Attempts for the Improvement of Ultra Lightweight OCR System
Jun 07, 2022

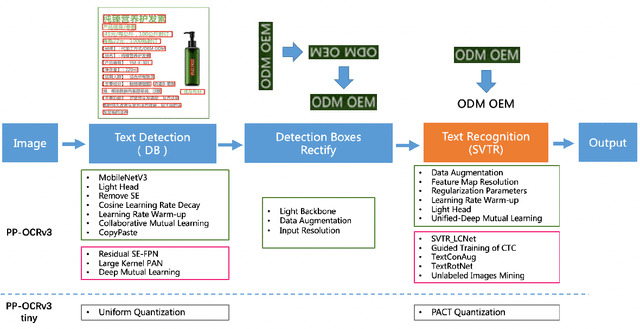
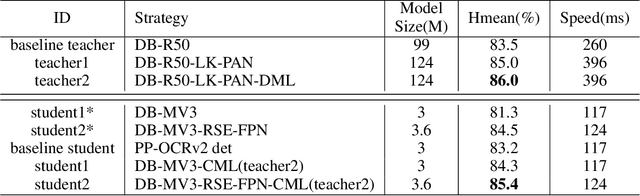
Optical character recognition (OCR) technology has been widely used in various scenes, as shown in Figure 1. Designing a practical OCR system is still a meaningful but challenging task. In previous work, considering the efficiency and accuracy, we proposed a practical ultra lightweight OCR system (PP-OCR), and an optimized version PP-OCRv2. In order to further improve the performance of PP-OCRv2, a more robust OCR system PP-OCRv3 is proposed in this paper. PP-OCRv3 upgrades the text detection model and text recognition model in 9 aspects based on PP-OCRv2. For text detector, we introduce a PAN module with large receptive field named LK-PAN, a FPN module with residual attention mechanism named RSE-FPN, and DML distillation strategy. For text recognizer, the base model is replaced from CRNN to SVTR, and we introduce lightweight text recognition network SVTR LCNet, guided training of CTC by attention, data augmentation strategy TextConAug, better pre-trained model by self-supervised TextRotNet, UDML, and UIM to accelerate the model and improve the effect. Experiments on real data show that the hmean of PP-OCRv3 is 5% higher than PP-OCRv2 under comparable inference speed. All the above mentioned models are open-sourced and the code is available in the GitHub repository PaddleOCR which is powered by PaddlePaddle.