 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowLens: Seeing Beyond the FoV via Flow-guided Clip-Recurrent Transformer
Paper and Code
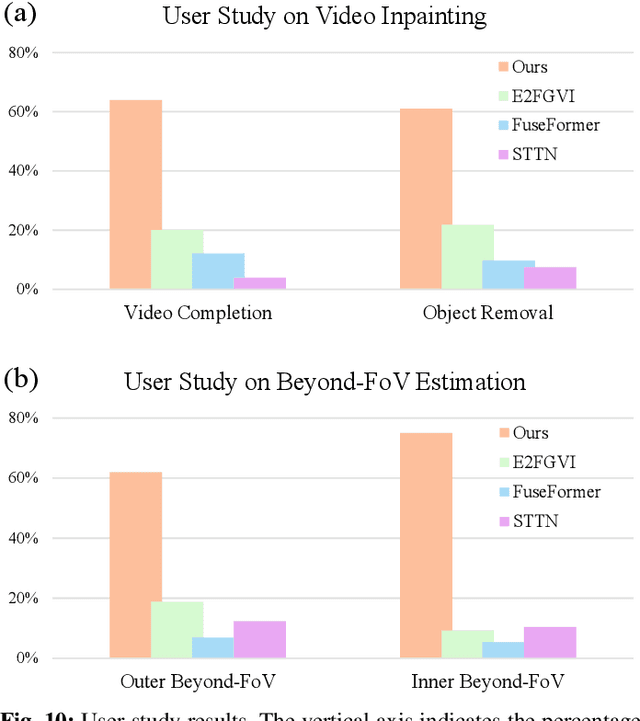


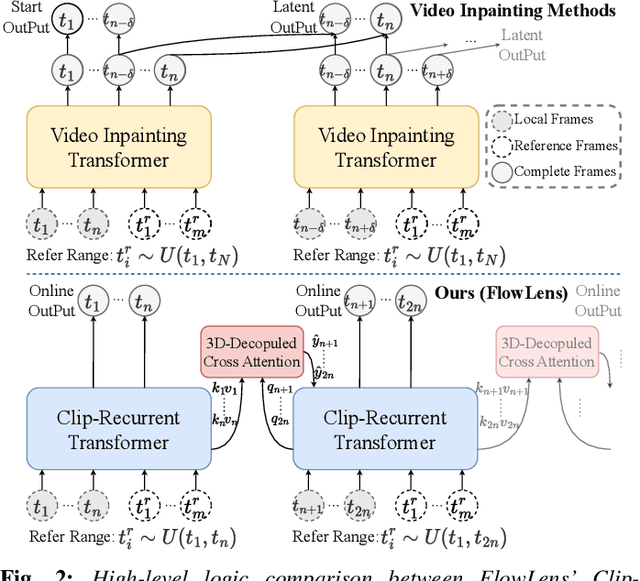
Limited by hardware cost and system size, camera's Field-of-View (FoV) is not always satisfactory. However, from a spatio-temporal perspective, information beyond the camera's physical FoV is off-the-shelf and can actually be obtained "for free" from the past. In this paper, we propose a novel task termed Beyond-FoV Estimation, aiming to exploit past visual cues and bidirectional break through the physical FoV of a camera. We put forward a FlowLens architecture to expand the FoV by achieving feature propagation explicitly by optical flow and implicitly by a novel clip-recurrent transformer, which has two appealing features: 1) FlowLens comprises a newly proposed Clip-Recurrent Hub with 3D-Decoupled Cross Attention (DDCA) to progressively process global information accumulated in the temporal dimension. 2) A multi-branch Mix Fusion Feed Forward Network (MixF3N) is integrated to enhance the spatially-precise flow of local features. To foster training and evaluation, we establish KITTI360-EX, a dataset for outer- and inner FoV expansion. Extensive experiments on both video inpainting and beyond-FoV estimation tasks show that FlowLens achieves state-of-the-art performance. Code will be made publicly available at https://github.com/MasterHow/FlowLens.