 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-VLA: Event-Augmented Vision-Language-Action Model for Dark and Blurred Scenes
Apr 06, 2026Robotic Vision-Language-Action (VLA) models generalize well for open-ended manipulation, but their perception is fragile under sensing-stage degradations such as extreme low light, motion blur, and black clipping. We present E-VLA, an event-augmented VLA framework that improves manipulation robustness when conventional frame-based vision becomes unreliable. Instead of reconstructing images from events, E-VLA directly leverages motion and structural cues in event streams to preserve semantic perception and perception-action consistency under adverse conditions. We build an open-source teleoperation platform with a DAVIS346 event camera and collect a real-world synchronized RGB-event-action manipulation dataset across diverse tasks and illumination settings. We also propose lightweight, pretrained-compatible event integration strategies and study event windowing and fusion for stable deployment. Experiments show that even a simple parameter-free fusion, i.e., overlaying accumulated event maps onto RGB images, could substantially improve robustness in dark and blur-heavy scenes: on Pick-Place at 20 lux, success increases from 0% (image-only) to 60% with overlay fusion and to 90% with our event adapter; under severe motion blur (1000 ms exposure), Pick-Place improves from 0% to 20-25%, and Sorting from 5% to 32.5%. Overall, E-VLA provides systematic evidence that event-driven perception can be effectively integrated into VLA models, pointing toward robust embodied intelligence beyond conventional frame-based imaging. Code and dataset will be available at https://github.com/JJayzee/E-VLA.
Towards Universal Computational Aberration Correction in Photographic Cameras: A Comprehensive Benchmark Analysis
Mar 12, 2026Prevalent Computational Aberration Correction (CAC) methods are typically tailored to specific optical systems, leading to poor generalization and labor-intensive re-training for new lenses. Developing CAC paradigms capable of generalizing across diverse photographic lenses offers a promising solution to these challenges. However, efforts to achieve such cross-lens universality within consumer photography are still in their early stages due to the lack of a comprehensive benchmark that encompasses a sufficiently wide range of optical aberrations. Furthermore, it remains unclear which specific factors influence existing CAC methods and how these factors affect their performance. In this paper, we present comprehensive experiments and evaluations involving 24 image restoration and CAC algorithms, utilizing our newly proposed UniCAC, a large-scale benchmark for photographic cameras constructed via automatic optical design. The Optical Degradation Evaluator (ODE) is introduced as a novel framework to objectively assess the difficulty of CAC tasks, offering credible quantification of optical aberrations and enabling reliable evaluation. Drawing on our comparative analysis, we identify three key factors -- prior utilization, network architecture, and training strategy -- that most significantly influence CAC performance, and further investigate their respective effects. We believe that our benchmark, dataset, and observations contribute foundational insights to related areas and lay the groundwork for future investigations. Benchmarks, codes, and Zemax files will be available at https://github.com/XiaolongQian/UniCAC.
OPTIAGENT: A Physics-Driven Agentic Framework for Automated Optical Design
Feb 27, 2026Optical design is the process of configuring optical elements to precisely manipulate light for high-fidelity imaging. It is inherently a highly non-convex optimization problem that relies heavily on human heuristic expertise and domain-specific knowledge. While Large Language Models (LLMs) possess extensive optical knowledge, their capabilities in leveraging the knowledge in designing lens system remain significantly constrained. This work represents the first attempt to employ LLMs in the field of optical design. We bridge the expertise gap by enabling users without formal optical training to successfully develop functional lens systems. Concretely, we curate a comprehensive dataset, named OptiDesignQA, which encompasses both classical lens systems sourced from standard optical textbooks and novel configurations generated by automated design algorithms for training and evaluation. Furthermore, we inject domain-specific optical expertise into the LLM through a hybrid objective of full-system synthesis and lens completion. To align the model with optical principles, we employ Group Relative Policy Optimization Done Right (DrGRPO) guided by Optical Lexicographic Reward for physics-driven policy alignment. This reward system incorporates structural format rewards, physical feasibility rewards, light-manipulation accuracy, and LLM-based heuristics. Finally, our model integrates with specialized optical optimization routines for end-to-end fine-tuning and precision refinement. We benchmark our proposed method against both traditional optimization-based automated design algorithms and LLM counterparts, and experimental results show the superiority of our method.
Towards Real-world Lens Active Alignment with Unlabeled Data via Domain Adaptation
Jan 08, 2026Active Alignment (AA) is a key technology for the large-scale automated assembly of high-precision optical systems. Compared with labor-intensive per-model on-device calibration, a digital-twin pipeline built on optical simulation offers a substantial advantage in generating large-scale labeled data. However, complex imaging conditions induce a domain gap between simulation and real-world images, limiting the generalization of simulation-trained models. To address this, we propose augmenting a simulation baseline with minimal unlabeled real-world images captured at random misalignment positions, mitigating the gap from a domain adaptation perspective. We introduce Domain Adaptive Active Alignment (DA3), which utilizes an autoregressive domain transformation generator and an adversarial-based feature alignment strategy to distill real-world domain information via self-supervised learning. This enables the extraction of domain-invariant image degradation features to facilitate robust misalignment prediction. Experiments on two lens types reveal that DA3 improves accuracy by 46% over a purely simulation pipeline. Notably, it approaches the performance achieved with precisely labeled real-world data collected on 3 lens samples, while reducing on-device data collection time by 98.7%. The results demonstrate that domain adaptation effectively endows simulation-trained models with robust real-world performance, validating the digital-twin pipeline as a practical solution to significantly enhance the efficiency of large-scale optical assembly.
OneOcc: Semantic Occupancy Prediction for Legged Robots with a Single Panoramic Camera
Nov 05, 2025Robust 3D semantic occupancy is crucial for legged/humanoid robots, yet most semantic scene completion (SSC) systems target wheeled platforms with forward-facing sensors. We present OneOcc, a vision-only panoramic SSC framework designed for gait-introduced body jitter and 360{\deg} continuity. OneOcc combines: (i) Dual-Projection fusion (DP-ER) to exploit the annular panorama and its equirectangular unfolding, preserving 360{\deg} continuity and grid alignment; (ii) Bi-Grid Voxelization (BGV) to reason in Cartesian and cylindrical-polar spaces, reducing discretization bias and sharpening free/occupied boundaries; (iii) a lightweight decoder with Hierarchical AMoE-3D for dynamic multi-scale fusion and better long-range/occlusion reasoning; and (iv) plug-and-play Gait Displacement Compensation (GDC) learning feature-level motion correction without extra sensors. We also release two panoramic occupancy benchmarks: QuadOcc (real quadruped, first-person 360{\deg}) and Human360Occ (H3O) (CARLA human-ego 360{\deg} with RGB, Depth, semantic occupancy; standardized within-/cross-city splits). OneOcc sets new state-of-the-art (SOTA): on QuadOcc it beats strong vision baselines and popular LiDAR ones; on H3O it gains +3.83 mIoU (within-city) and +8.08 (cross-city). Modules are lightweight, enabling deployable full-surround perception for legged/humanoid robots. Datasets and code will be publicly available at https://github.com/MasterHow/OneOcc.
NTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
Low-Light Image Enhancement using Event-Based Illumination Estimation
Apr 13, 2025Low-light image enhancement (LLIE) aims to improve the visibility of images captured in poorly lit environments. Prevalent event-based solutions primarily utilize events triggered by motion, i.e., ''motion events'' to strengthen only the edge texture, while leaving the high dynamic range and excellent low-light responsiveness of event cameras largely unexplored. This paper instead opens a new avenue from the perspective of estimating the illumination using ''temporal-mapping'' events, i.e., by converting the timestamps of events triggered by a transmittance modulation into brightness values. The resulting fine-grained illumination cues facilitate a more effective decomposition and enhancement of the reflectance component in low-light images through the proposed Illumination-aided Reflectance Enhancement module. Furthermore, the degradation model of temporal-mapping events under low-light condition is investigated for realistic training data synthesizing. To address the lack of datasets under this regime, we construct a beam-splitter setup and collect EvLowLight dataset that includes images, temporal-mapping events, and motion events. Extensive experiments across 5 synthetic datasets and our real-world EvLowLight dataset substantiate that the devised pipeline, dubbed RetinEV, excels in producing well-illuminated, high dynamic range images, outperforming previous state-of-the-art event-based methods by up to 6.62 dB, while maintaining an efficient inference speed of 35.6 frame-per-second on a 640X480 image.
EgoEvGesture: Gesture Recognition Based on Egocentric Event Camera
Mar 16, 2025
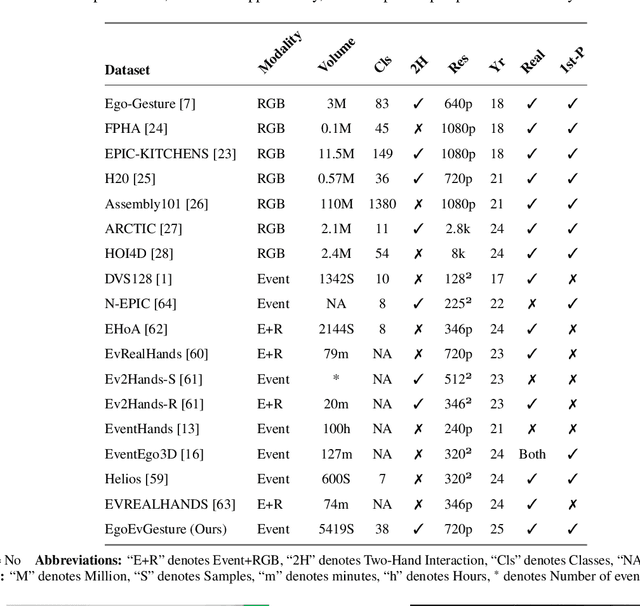
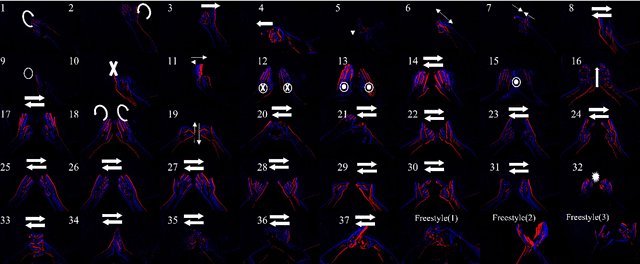
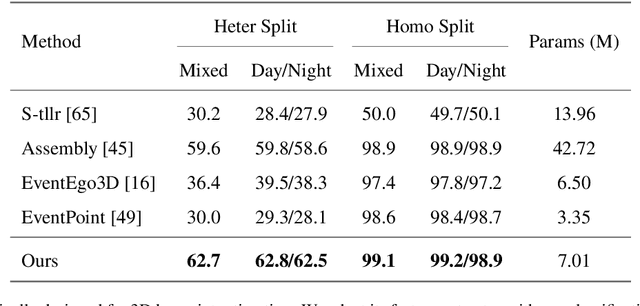
Egocentric gesture recognition is a pivotal technology for enhancing natural human-computer interaction, yet traditional RGB-based solutions suffer from motion blur and illumination variations in dynamic scenarios. While event cameras show distinct advantages in handling high dynamic range with ultra-low power consumption, existing RGB-based architectures face inherent limitations in processing asynchronous event streams due to their synchronous frame-based nature. Moreover, from an egocentric perspective, event cameras record data that include events generated by both head movements and hand gestures, thereby increasing the complexity of gesture recognition. To address this, we propose a novel network architecture specifically designed for event data processing, incorporating (1) a lightweight CNN with asymmetric depthwise convolutions to reduce parameters while preserving spatiotemporal features, (2) a plug-and-play state-space model as context block that decouples head movement noise from gesture dynamics, and (3) a parameter-free Bins-Temporal Shift Module (BSTM) that shifts features along bins and temporal dimensions to fuse sparse events efficiently. We further build the EgoEvGesture dataset, the first large-scale dataset for egocentric gesture recognition using event cameras. Experimental results demonstrate that our method achieves 62.7% accuracy in heterogeneous testing with only 7M parameters, 3.1% higher than state-of-the-art approaches. Notable misclassifications in freestyle motions stem from high inter-personal variability and unseen test patterns differing from training data. Moreover, our approach achieved a remarkable accuracy of 96.97% on DVS128 Gesture, demonstrating strong cross-dataset generalization capability. The dataset and models are made publicly available at https://github.com/3190105222/EgoEv_Gesture.
Omnidirectional Multi-Object Tracking
Mar 06, 2025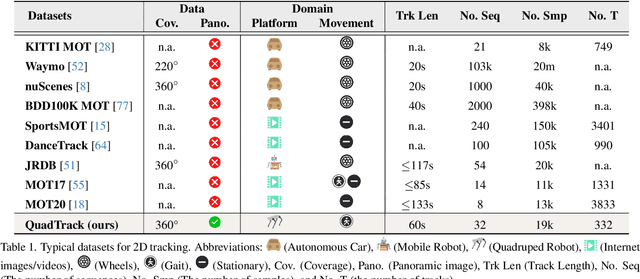
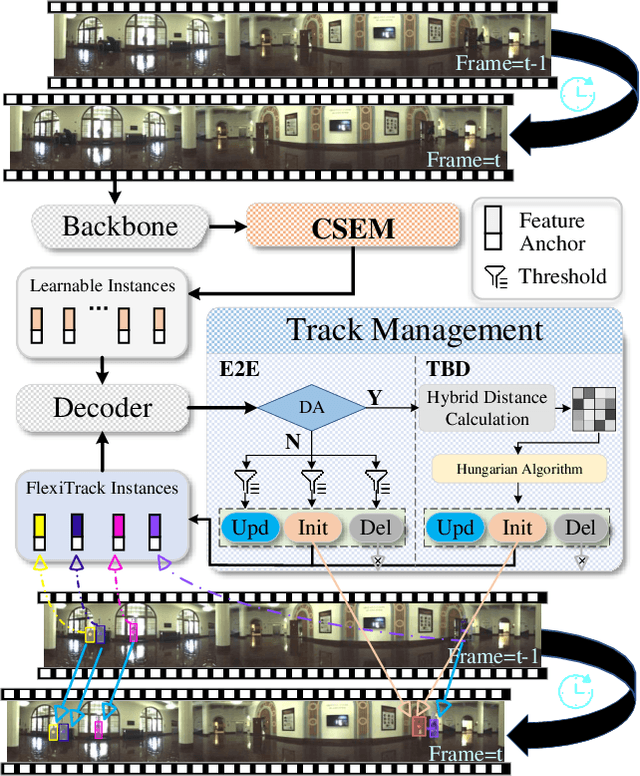
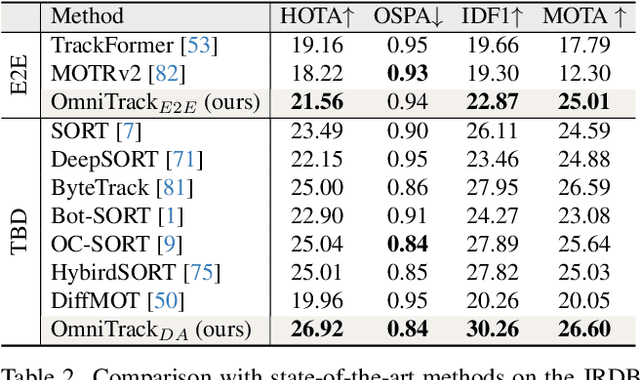
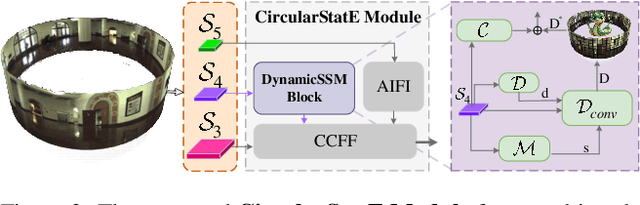
Panoramic imagery, with its 360{\deg} field of view, offers comprehensive information to support Multi-Object Tracking (MOT) in capturing spatial and temporal relationships of surrounding objects. However, most MOT algorithms are tailored for pinhole images with limited views, impairing their effectiveness in panoramic settings. Additionally, panoramic image distortions, such as resolution loss, geometric deformation, and uneven lighting, hinder direct adaptation of existing MOT methods, leading to significant performance degradation. To address these challenges, we propose OmniTrack, an omnidirectional MOT framework that incorporates Tracklet Management to introduce temporal cues, FlexiTrack Instances for object localization and association, and the CircularStatE Module to alleviate image and geometric distortions. This integration enables tracking in large field-of-view scenarios, even under rapid sensor motion. To mitigate the lack of panoramic MOT datasets, we introduce the QuadTrack dataset--a comprehensive panoramic dataset collected by a quadruped robot, featuring diverse challenges such as wide fields of view, intense motion, and complex environments. Extensive experiments on the public JRDB dataset and the newly introduced QuadTrack benchmark demonstrate the state-of-the-art performance of the proposed framework. OmniTrack achieves a HOTA score of 26.92% on JRDB, representing an improvement of 3.43%, and further achieves 23.45% on QuadTrack, surpassing the baseline by 6.81%. The dataset and code will be made publicly available at https://github.com/xifen523/OmniTrack.
One-Step Event-Driven High-Speed Autofocus
Mar 03, 2025



High-speed autofocus in extreme scenes remains a significant challenge. Traditional methods rely on repeated sampling around the focus position, resulting in ``focus hunting''. Event-driven methods have advanced focusing speed and improved performance in low-light conditions; however, current approaches still require at least one lengthy round of ``focus hunting'', involving the collection of a complete focus stack. We introduce the Event Laplacian Product (ELP) focus detection function, which combines event data with grayscale Laplacian information, redefining focus search as a detection task. This innovation enables the first one-step event-driven autofocus, cutting focusing time by up to two-thirds and reducing focusing error by 24 times on the DAVIS346 dataset and 22 times on the EVK4 dataset. Additionally, we present an autofocus pipeline tailored for event-only cameras, achieving accurate results across a range of challenging motion and lighting conditions. All datasets and code will be made publicly available.