 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel Cube: Diffusion-based Portrait Video Relighting Through Realistic Lighting Reproduction
Jun 05, 2026We present a diffusion-based method for relighting dynamic portrait videos with photorealism and temporal consistency. Our method is fueled by a hybrid training dataset that consists of real-captured and rendered dynamic portrait videos with diverse subject appearances, facial motions, head poses, and known lighting conditions. Specifically, we construct an LED-based lighting system for realistic lighting emulation and high-speed video relighting data acquisition. By leveraging the image priors embedded in pre-trained video diffusion models, and using per-frame high dynamic range (HDR) environment map as lighting control, we train a high-performance generative model for realistic and identity-preserving dynamic portrait video relighting. In addition to the environment map control, our model uses a synthesized background image to enable control on the camera's exposure level and color tone. Our model can produce temporally consistent relit portrait video that looks realistic and harmonious under a provided new environment and faithfully preserve the subject's expression and fine facial features, including skin tone, wrinkles, and facial hair. Our model generalizes well to unseen data, in terms of the subject appearance, motion, and lighting condition. We perform extensive experiments on relighting in-the-wild videos with various environment maps and demonstrate practical applications on portrait photography. Results show that our method achieves state-of-the-art performance in photorealism, lighting harmony, and temporal consistency.
* ACM SIGGRAPH 2026 Journal Track / ACM Transactions on Graphics, 17 pages. Project page: https://yufanzhang82.github.io/PixelCube/
BigMac: Breaking the Pareto Frontier of Compute and Memory in Multimodal LLM Training
May 25, 2026Training multimodal large language models (MLLMs) is challenged by both model and data heterogeneity. Existing systems redesign the training pipeline to address these challenges, but remain bound by a Pareto frontier between compute and memory efficiency, improving one only at the expense of the other. We present BigMac, a new training pipeline for multimodal LLMs. The core idea of BigMac is to elegantly nest the encoder and generator computation into the original LLM pipeline, forming a dependency-safe nested pipeline structure. With this design, BigMac reduces the activation memory complexity of the encoder and generator to O(1) while keeping the activation memory complexity of the LLM unchanged. At the same time, it achieves the same computational efficiency as the idealized setting with unlimited memory. As a result, BigMac breaks the Pareto frontier between computational efficiency and memory usage, enabling simultaneous optimization of both computation and memory in MLLM training. We evaluate BigMac on multiple MLLMs and training workloads. Experimental results show that BigMac achieves a 1.08$\times$-1.9$\times$ training speedup over baseline systems while maintaining stable memory usage as batch size increases.
Covariance-Aware Transformers for Quadratic Programming and Decision Making
Feb 16, 2026We explore the use of transformers for solving quadratic programs and how this capability benefits decision-making problems that involve covariance matrices. We first show that the linear attention mechanism can provably solve unconstrained QPs by tokenizing the matrix variables (e.g.~$A$ of the objective $\frac{1}{2}x^\top Ax+b^\top x$) row-by-row and emulating gradient descent iterations. Furthermore, by incorporating MLPs, a transformer block can solve (i) $\ell_1$-penalized QPs by emulating iterative soft-thresholding and (ii) $\ell_1$-constrained QPs when equipped with an additional feedback loop. Our theory motivates us to introduce Time2Decide: a generic method that enhances a time series foundation model (TSFM) by explicitly feeding the covariance matrix between the variates. We empirically find that Time2Decide uniformly outperforms the base TSFM model for the classical portfolio optimization problem that admits an $\ell_1$-constrained QP formulation. Remarkably, Time2Decide also outperforms the classical "Predict-then-Optimize (PtO)" procedure, where we first forecast the returns and then explicitly solve a constrained QP, in suitable settings. Our results demonstrate that transformers benefit from explicit use of second-order statistics, and this can enable them to effectively solve complex decision-making problems, like portfolio construction, in one forward pass.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
AI Literacy Assessment Revisited: A Task-Oriented Approach Aligned with Real-world Occupations
Nov 07, 2025As artificial intelligence (AI) systems become ubiquitous in professional contexts, there is an urgent need to equip workers, often with backgrounds outside of STEM, with the skills to use these tools effectively as well as responsibly, that is, to be AI literate. However, prevailing definitions and therefore assessments of AI literacy often emphasize foundational technical knowledge, such as programming, mathematics, and statistics, over practical knowledge such as interpreting model outputs, selecting tools, or identifying ethical concerns. This leaves a noticeable gap in assessing someone's AI literacy for real-world job use. We propose a work-task-oriented assessment model for AI literacy which is grounded in the competencies required for effective use of AI tools in professional settings. We describe the development of a novel AI literacy assessment instrument, and accompanying formative assessments, in the context of a US Navy robotics training program. The program included training in robotics and AI literacy, as well as a competition with practical tasks and a multiple choice scenario task meant to simulate use of AI in a job setting. We found that, as a measure of applied AI literacy, the competition's scenario task outperformed the tests we adopted from past research or developed ourselves. We argue that when training people for AI-related work, educators should consider evaluating them with instruments that emphasize highly contextualized practical skills rather than abstract technical knowledge, especially when preparing workers without technical backgrounds for AI-integrated roles.
Utilizing Sequential Information of General Lab-test Results and Diagnoses History for Differential Diagnosis of Dementia
Feb 21, 2025



Early diagnosis of Alzheimer's Disease (AD) faces multiple data-related challenges, including high variability in patient data, limited access to specialized diagnostic tests, and overreliance on single-type indicators. These challenges are exacerbated by the progressive nature of AD, where subtle pathophysiological changes often precede clinical symptoms by decades. To address these limitations, this study proposes a novel approach that takes advantage of routinely collected general laboratory test histories for the early detection and differential diagnosis of AD. By modeling lab test sequences as "sentences", we apply word embedding techniques to capture latent relationships between tests and employ deep time series models, including long-short-term memory (LSTM) and Transformer networks, to model temporal patterns in patient records. Experimental results demonstrate that our approach improves diagnostic accuracy and enables scalable and costeffective AD screening in diverse clinical settings.
Benchmarking the Robustness of Optical Flow Estimation to Corruptions
Nov 22, 2024



Optical flow estimation is extensively used in autonomous driving and video editing. While existing models demonstrate state-of-the-art performance across various benchmarks, the robustness of these methods has been infrequently investigated. Despite some research focusing on the robustness of optical flow models against adversarial attacks, there has been a lack of studies investigating their robustness to common corruptions. Taking into account the unique temporal characteristics of optical flow, we introduce 7 temporal corruptions specifically designed for benchmarking the robustness of optical flow models, in addition to 17 classical single-image corruptions, in which advanced PSF Blur simulation method is performed. Two robustness benchmarks, KITTI-FC and GoPro-FC, are subsequently established as the first corruption robustness benchmark for optical flow estimation, with Out-Of-Domain (OOD) and In-Domain (ID) settings to facilitate comprehensive studies. Robustness metrics, Corruption Robustness Error (CRE), Corruption Robustness Error ratio (CREr), and Relative Corruption Robustness Error (RCRE) are further introduced to quantify the optical flow estimation robustness. 29 model variants from 15 optical flow methods are evaluated, yielding 10 intriguing observations, such as 1) the absolute robustness of the model is heavily dependent on the estimation performance; 2) the corruptions that diminish local information are more serious than that reduce visual effects. We also give suggestions for the design and application of optical flow models. We anticipate that our benchmark will serve as a foundational resource for advancing research in robust optical flow estimation. The benchmarks and source code will be released at https://github.com/ZhonghuaYi/optical_flow_robustness_benchmark.
EI-Nexus: Towards Unmediated and Flexible Inter-Modality Local Feature Extraction and Matching for Event-Image Data
Oct 29, 2024



Event cameras, with high temporal resolution and high dynamic range, have limited research on the inter-modality local feature extraction and matching of event-image data. We propose EI-Nexus, an unmediated and flexible framework that integrates two modality-specific keypoint extractors and a feature matcher. To achieve keypoint extraction across viewpoint and modality changes, we bring Local Feature Distillation (LFD), which transfers the viewpoint consistency from a well-learned image extractor to the event extractor, ensuring robust feature correspondence. Furthermore, with the help of Context Aggregation (CA), a remarkable enhancement is observed in feature matching. We further establish the first two inter-modality feature matching benchmarks, MVSEC-RPE and EC-RPE, to assess relative pose estimation on event-image data. Our approach outperforms traditional methods that rely on explicit modal transformation, offering more unmediated and adaptable feature extraction and matching, achieving better keypoint similarity and state-of-the-art results on the MVSEC-RPE and EC-RPE benchmarks. The source code and benchmarks will be made publicly available at https://github.com/ZhonghuaYi/EI-Nexus_official.
M2P2: A Multi-Modal Passive Perception Dataset for Off-Road Mobility in Extreme Low-Light Conditions
Oct 01, 2024


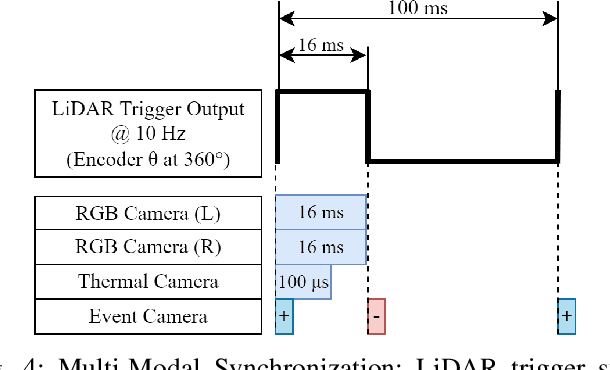
Long-duration, off-road, autonomous missions require robots to continuously perceive their surroundings regardless of the ambient lighting conditions. Most existing autonomy systems heavily rely on active sensing, e.g., LiDAR, RADAR, and Time-of-Flight sensors, or use (stereo) visible light imaging sensors, e.g., color cameras, to perceive environment geometry and semantics. In scenarios where fully passive perception is required and lighting conditions are degraded to an extent that visible light cameras fail to perceive, most downstream mobility tasks such as obstacle avoidance become impossible. To address such a challenge, this paper presents a Multi-Modal Passive Perception dataset, M2P2, to enable off-road mobility in low-light to no-light conditions. We design a multi-modal sensor suite including thermal, event, and stereo RGB cameras, GPS, two Inertia Measurement Units (IMUs), as well as a high-resolution LiDAR for ground truth, with a novel multi-sensor calibration procedure that can efficiently transform multi-modal perceptual streams into a common coordinate system. Our 10-hour, 32 km dataset also includes mobility data such as robot odometry and actions and covers well-lit, low-light, and no-light conditions, along with paved, on-trail, and off-trail terrain. Our results demonstrate that off-road mobility is possible through only passive perception in extreme low-light conditions using end-to-end learning and classical planning. The project website can be found at https://cs.gmu.edu/~xiao/Research/M2P2/
P2U-SLAM: A Monocular Wide-FoV SLAM System Based on Point Uncertainty and Pose Uncertainty
Sep 16, 2024



This paper presents P2U-SLAM, a visual Simultaneous Localization And Mapping (SLAM) system with a wide Field of View (FoV) camera, which utilizes pose uncertainty and point uncertainty. While the wide FoV enables considerable repetitive observations of historical map points for matching cross-view features, the data properties of the historical map points and the poses of historical keyframes have changed during the optimization process. The neglect of data property changes triggers the absence of a partial information matrix in optimization and leads to the risk of long-term positioning performance degradation. The purpose of our research is to reduce the risk of the wide field of view visual input to the SLAM system. Based on the conditional probability model, this work reveals the definite impact of the above data properties changes on the optimization process, concretizes it as point uncertainty and pose uncertainty, and gives a specific mathematical form. P2U-SLAM respectively embeds point uncertainty and pose uncertainty into the tracking module and local mapping, and updates these uncertainties after each optimization operation including local mapping, map merging, and loop closing. We present an exhaustive evaluation in 27 sequences from two popular public datasets with wide-FoV visual input. P2U-SLAM shows excellent performance compared with other state-of-the-art methods. The source code will be made publicly available at https://github.com/BambValley/P2U-SLAM.