 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision-calibrated prediction sets for robust power system operations
Jun 01, 2026Robust optimization offers a tractable approach to balance operating costs and reliability in power systems dominated by weather-dependent renewable uncertainty, but its performance depends critically on the uncertainty set. Standard data-driven approaches often calibrate uncertainty sets to attain predictive coverage, which can produce unnecessarily large sets and costly operating decisions. In contrast, we introduce decision-calibrated prediction sets and embed them as uncertainty sets in robust optimization problems; these are conditional multivariate prediction sets where calibration is defined in terms of the reliability of downstream decisions, rather than in terms of the coverage. First, we learn these conditional prediction sets as sub-level sets of norm-based score functions represented by partially input-convex neural networks, capturing contextual information and multivariate dependence while preserving convexity and tractability in downstream robust formulations. Second, inspired by conformal risk control, we calibrate a score-threshold parameter that sets the volume of the uncertainty set, thereby controlling the expected violations of downstream operational constraints. We apply our approach to 15-minute-ahead reserve scheduling with network-constrained deliverability, which we formulate as a robust DC optimal power flow problem with affine recourse. Numerical experiments show that decision-calibrated sets attain prescribed constraint-satisfaction targets within about three percentage points, whereas standard coverage-based calibration systematically exceeds these targets by more than eleven percentage points, leading to larger sets and higher operating costs.
Stabilizing distribution-free probabilistic forecasts
May 27, 2026Multi-step-ahead forecasts are often updated as new observations become available, since shorter forecast horizons typically improve forecast quality. However, such improvements come at the cost of forecast instability, i.e., variability in forecasts for the same target period. This instability can trigger costly changes to plans formulated based on the forecasts and may erode trust in the forecasting system. In this work, we integrate forecast stability alongside forecast quality into the training of distribution-free probabilistic time-series forecasting models, allowing us to control this trade-off. We propose a method for generating stabilized forecasted conditional quantile functions using regression splines parameterized by a neural network. This approach enables joint optimization of quality and stability, as it allows us to directly penalize dissimilarities arising from forecast updates. Furthermore, it allows assigning varying importance to stabilizing different parts of the forecast distributions (e.g., central parts vs. tails) to focus on the parts most relevant for the intended downstream use (e.g., the upper tail for inventory management). We empirically evaluate the proposed method on two datasets with different statistical properties and show that it can effectively reduce forecast instability without a substantial loss in forecast quality, and that it can target stabilization effort toward specific parts of the forecast distributions.
Predict-then-Optimize for Seaport Power-Logistics Scheduling: Generalization across Varying Tasks Stream
Nov 13, 2025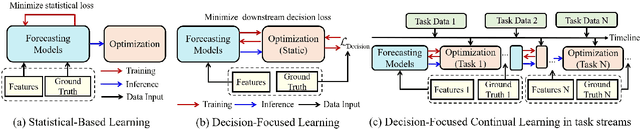



Power-logistics scheduling in modern seaports typically follow a predict-then-optimize pipeline. To enhance the decision quality of forecasts, decision-focused learning has been proposed, which aligns the training of forecasting models with downstream decision outcomes. However, this end-to-end design inherently restricts the value of forecasting models to only a specific task structure, and thus generalize poorly to evolving tasks induced by varying seaport vessel arrivals. We address this gap with a decision-focused continual learning framework that adapts online to a stream of scheduling tasks. Specifically, we introduce Fisher information based regularization to enhance cross-task generalization by preserving parameters critical to prior tasks. A differentiable convex surrogate is also developed to stabilize gradient backpropagation. The proposed approach enables learning a decision-aligned forecasting model across a varying tasks stream with a sustainable long-term computational burden. Experiments calibrated to the Jurong Port demonstrate superior decision performance and generalization over existing methods with reduced computational cost.
Value-oriented forecast reconciliation for renewables in electricity markets
Jan 27, 2025Forecast reconciliation is considered an effective method for achieving coherence and improving forecast accuracy. However, the value of reconciled forecasts in downstream decision-making tasks has been mostly overlooked. In a multi-agent setup with heterogeneous loss functions, this oversight may lead to unfair outcomes, hence resulting in conflicts during the reconciliation process. To address this, we propose a value-oriented forecast reconciliation approach that focuses on the forecast value for individual agents. Fairness is ensured through the use of a Nash bargaining framework. Specifically, we model this problem as a cooperative bargaining game, where each agent aims to optimize their own gain while contributing to the overall reconciliation process. We then present a primal-dual algorithm for parameter estimation based on empirical risk minimization. From an application perspective, we consider an aggregated wind energy trading problem, where profits are distributed using a weighted allocation rule. We demonstrate the effectiveness of our approach through several numerical experiments, showing that it consistently results in increased profits for all agents involved.
Improving Sequential Market Clearing via Value-oriented Renewable Energy Forecasting
May 15, 2024



Large penetration of renewable energy sources (RESs) brings huge uncertainty into the electricity markets. While existing deterministic market clearing fails to accommodate the uncertainty, the recently proposed stochastic market clearing struggles to achieve desirable market properties. In this work, we propose a value-oriented forecasting approach, which tactically determines the RESs generation that enters the day-ahead market. With such a forecast, the existing deterministic market clearing framework can be maintained, and the day-ahead and real-time overall operation cost is reduced. At the training phase, the forecast model parameters are estimated to minimize expected day-ahead and real-time overall operation costs, instead of minimizing forecast errors in a statistical sense. Theoretically, we derive the exact form of the loss function for training the forecast model that aligns with such a goal. For market clearing modeled by linear programs, this loss function is a piecewise linear function. Additionally, we derive the analytical gradient of the loss function with respect to the forecast, which inspires an efficient training strategy. A numerical study shows our forecasts can bring significant benefits of the overall cost reduction to deterministic market clearing, compared to quality-oriented forecasting approach.
Tackling Missing Values in Probabilistic Wind Power Forecasting: A Generative Approach
Mar 06, 2024Machine learning techniques have been successfully used in probabilistic wind power forecasting. However, the issue of missing values within datasets due to sensor failure, for instance, has been overlooked for a long time. Although it is natural to consider addressing this issue by imputing missing values before model estimation and forecasting, we suggest treating missing values and forecasting targets indifferently and predicting all unknown values simultaneously based on observations. In this paper, we offer an efficient probabilistic forecasting approach by estimating the joint distribution of features and targets based on a generative model. It is free of preprocessing, and thus avoids introducing potential errors. Compared with the traditional "impute, then predict" pipeline, the proposed approach achieves better performance in terms of continuous ranked probability score.
Enabling Fast Unit Commitment Constraint Screening via Learning Cost Model
Dec 01, 2022

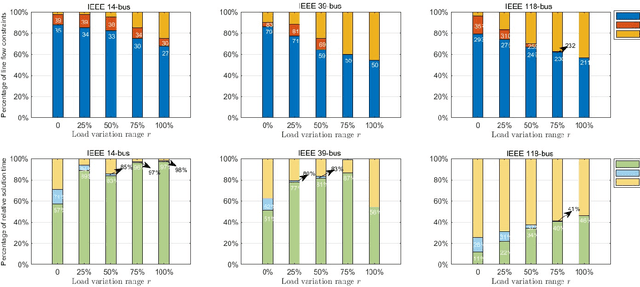

Unit commitment (UC) are essential tools to transmission system operators for finding the most economical and feasible generation schedules and dispatch signals. Constraint screening has been receiving attention as it holds the promise for reducing a number of inactive or redundant constraints in the UC problem, so that the solution process of large scale UC problem can be accelerated by considering the reduced optimization problem. Standard constraint screening approach relies on optimizing over load and generations to find binding line flow constraints, yet the screening is conservative with a large percentage of constraints still reserved for the UC problem. In this paper, we propose a novel machine learning (ML) model to predict the most economical costs given load inputs. Such ML model bridges the cost perspectives of UC decisions to the optimization-based constraint screening model, and can screen out higher proportion of operational constraints. We verify the proposed method's performance on both sample-aware and sample-agnostic setting, and illustrate the proposed scheme can further reduce the computation time on a variety of setup for UC problems.
Continuous and Distribution-free Probabilistic Wind Power Forecasting: A Conditional Normalizing Flow Approach
Jun 06, 2022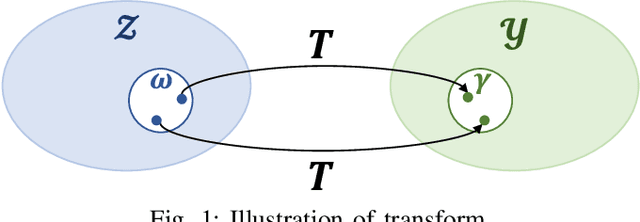
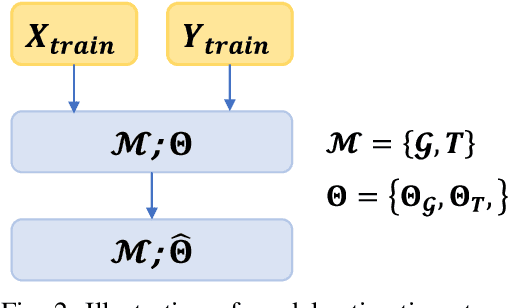
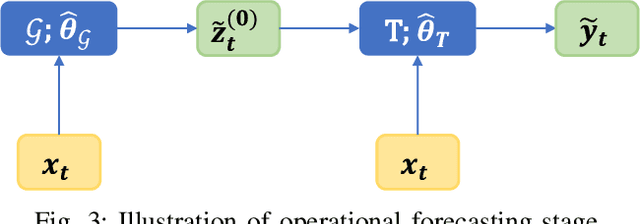
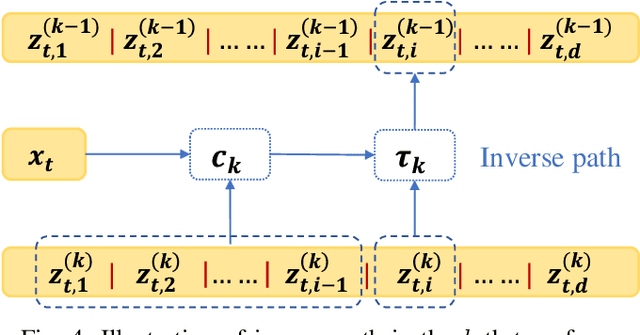
We present a data-driven approach for probabilistic wind power forecasting based on conditional normalizing flow (CNF). In contrast with the existing, this approach is distribution-free (as for non-parametric and quantile-based approaches) and can directly yield continuous probability densities, hence avoiding quantile crossing. It relies on a base distribution and a set of bijective mappings. Both the shape parameters of the base distribution and the bijective mappings are approximated with neural networks. Spline-based conditional normalizing flow is considered owing to its non-affine characteristics. Over the training phase, the model sequentially maps input examples onto samples of base distribution, given the conditional contexts, where parameters are estimated through maximum likelihood. To issue probabilistic forecasts, one eventually maps samples of the base distribution into samples of a desired distribution. Case studies based on open datasets validate the effectiveness of the proposed model, and allows us to discuss its advantages and caveats with respect to the state of the art.
Optimal Adaptive Prediction Intervals for Electricity Load Forecasting in Distribution Systems via Reinforcement Learning
May 18, 2022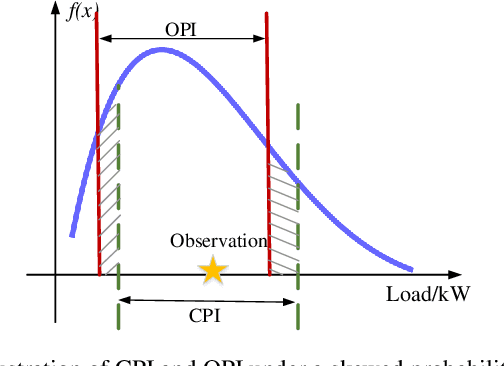
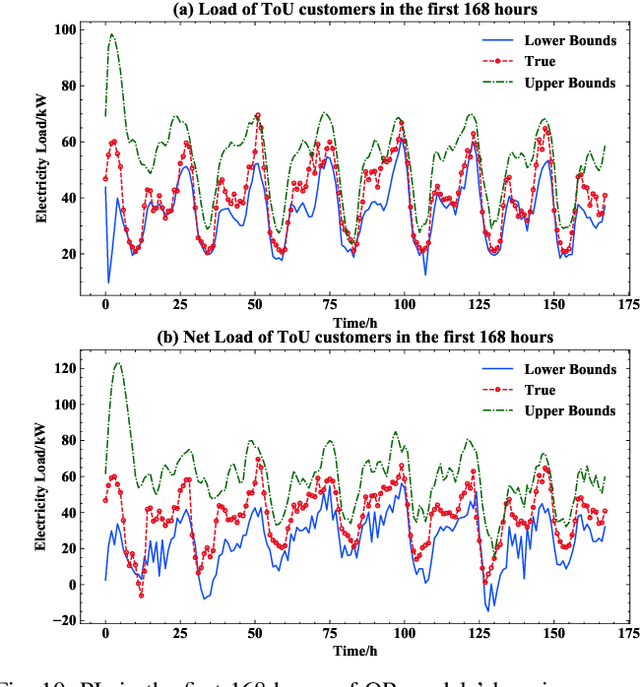

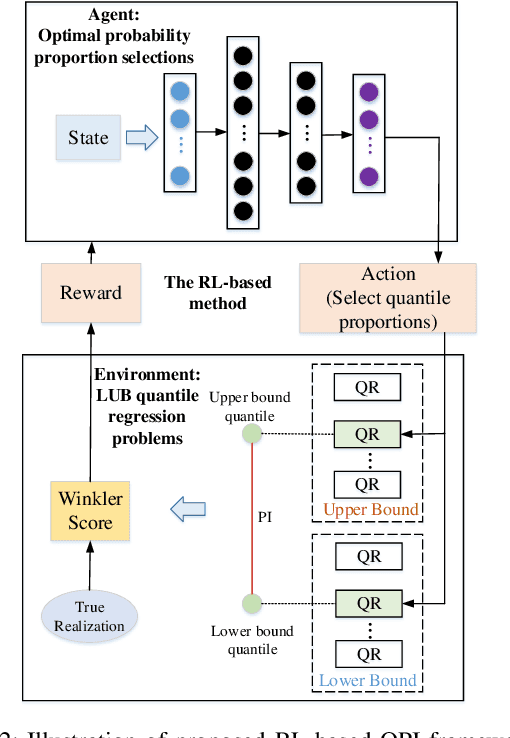
Prediction intervals offer an effective tool for quantifying the uncertainty of loads in distribution systems. The traditional central PIs cannot adapt well to skewed distributions, and their offline training fashion is vulnerable to unforeseen changes in future load patterns. Therefore, we propose an optimal PI estimation approach, which is online and adaptive to different data distributions by adaptively determining symmetric or asymmetric probability proportion pairs for quantiles. It relies on the online learning ability of reinforcement learning to integrate the two online tasks, i.e., the adaptive selection of probability proportion pairs and quantile predictions, both of which are modeled by neural networks. As such, the quality of quantiles-formed PI can guide the selection process of optimal probability proportion pairs, which forms a closed loop to improve the quality of PIs. Furthermore, to improve the learning efficiency of quantile forecasts, a prioritized experience replay strategy is proposed for online quantile regression processes. Case studies on both load and net load demonstrate that the proposed method can better adapt to data distribution compared with online central PIs method. Compared with offline-trained methods, it obtains PIs with better quality and is more robust against concept drift.
Skeleton Sequence and RGB Frame Based Multi-Modality Feature Fusion Network for Action Recognition
Feb 23, 2022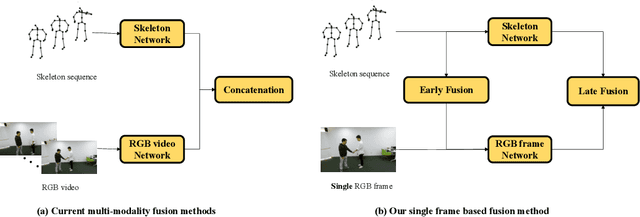
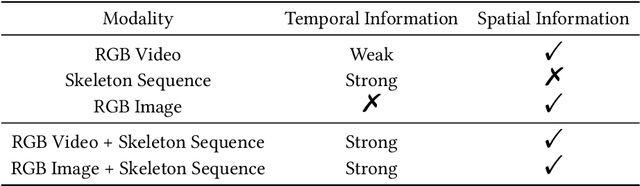
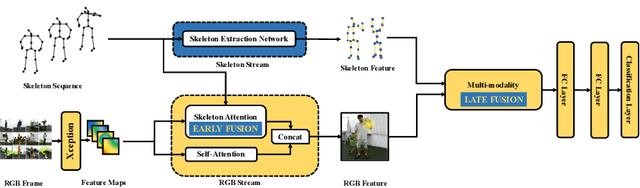
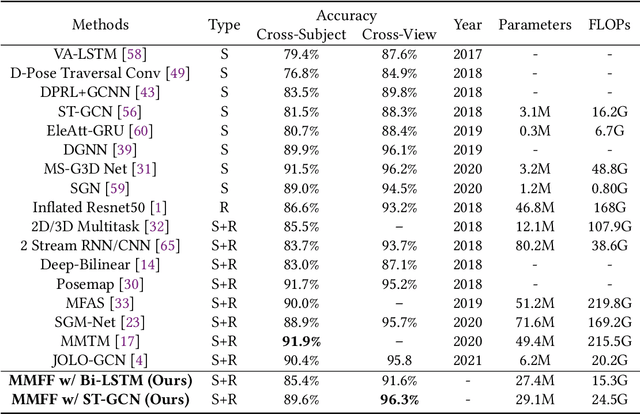
Action recognition has been a heated topic in computer vision for its wide application in vision systems. Previous approaches achieve improvement by fusing the modalities of the skeleton sequence and RGB video. However, such methods have a dilemma between the accuracy and efficiency for the high complexity of the RGB video network. To solve the problem, we propose a multi-modality feature fusion network to combine the modalities of the skeleton sequence and RGB frame instead of the RGB video, as the key information contained by the combination of skeleton sequence and RGB frame is close to that of the skeleton sequence and RGB video. In this way, the complementary information is retained while the complexity is reduced by a large margin. To better explore the correspondence of the two modalities, a two-stage fusion framework is introduced in the network. In the early fusion stage, we introduce a skeleton attention module that projects the skeleton sequence on the single RGB frame to help the RGB frame focus on the limb movement regions. In the late fusion stage, we propose a cross-attention module to fuse the skeleton feature and the RGB feature by exploiting the correlation. Experiments on two benchmarks NTU RGB+D and SYSU show that the proposed model achieves competitive performance compared with the state-of-the-art methods while reduces the complexity of the network.