 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank Adaptation for Critic Learning in Off-Policy Reinforcement Learning
Apr 21, 2026Scaling critic capacity is a promising direction for enhancing off-policy reinforcement learning (RL). However, larger critics are prone to overfitting and unstable in replay-buffer-based bootstrap training. This paper leverages Low-Rank Adaptation (LoRA) as a structural-sparsity regularizer for off-policy critics. Our approach freezes randomly initialized base matrices and solely optimizes low-rank adapters, thereby constraining critic updates to a low-dimensional subspace. Built on top of SimbaV2, we further develop a LoRA formulation, compatible with SimbaV2, that preserves its hyperspherical normalization geometry under frozen-backbone training. We evaluate our method with SAC and FastTD3 on DeepMind Control locomotion and IsaacLab robotics benchmarks. LoRA consistently achieves lower critic loss during training and stronger policy performance. Extensive experiments demonstrate that adaptive low-rank updates provide a simple, scalable, and effective structural regularization for critic learning in off-policy RL.
Predictor-Based Output-Feedback Control of Linear Systems with Time-Varying Input and Measurement Delays via Neural-Approximated Prediction Horizons
Mar 31, 2026Due to simplicity and strong stability guarantees, predictor feedback methods have stood as a popular approach for time delay systems since the 1950s. For time-varying delays, however, implementation requires computing a prediction horizon defined by the inverse of the delay function, which is rarely available in closed form and must be approximated. In this work, we formulate the inverse delay mapping as an operator learning problem and study predictor feedback under approximation of the prediction horizon. We propose two approaches: (i) a numerical method based on time integration of an equivalent ODE, and (ii) a data-driven method using neural operators to learn the inverse mapping. We show that both approaches achieve arbitrary approximation accuracy over compact sets, with complementary trade-offs in computational cost and scalability. Building on these approximations, we then develop an output-feedback predictor design for systems with delays in both the input and the measurement. We prove that the resulting closed-loop system is globally exponentially stable when the prediction horizon is approximated with sufficiently small error. Lastly, numerical experiments validate the proposed methods and illustrate their trade-offs between accuracy and computational efficiency.
Sampling-Horizon Neural Operator Predictors for Nonlinear Control under Delayed Inputs
Mar 31, 2026Modern control systems frequently operate under input delays and sampled state measurements. A common delay-compensation strategy is predictor feedback; however, practical implementations require solving an implicit ODE online, resulting in intractable computational cost. Moreover, predictor formulations typically assume continuously available state measurements, whereas in practice measurements may be sampled, irregular, or temporarily missing due to hardware faults. In this work, we develop two neural-operator predictor-feedback designs for nonlinear systems with delayed inputs and sampled measurements. In the first design, we introduce a sampling-horizon prediction operator that maps the current measurement and input history to the predicted state trajectory over the next sampling interval. In the second design, the neural operator approximates only the delay-compensating predictor, which is then composed with the closed-loop flow between measurements. The first approach requires uniform sampling but yields residual bounds that scale directly with the operator approximation error. In contrast, the second accommodates non-uniform, but bounded sampling schedules at the cost of amplified approximation error, revealing a practical tradeoff between sampling flexibility and approximation sensitivity for the control engineer. For both schemes, we establish semi-global practical stability with explicit neural operator error-dependent bounds. Numerical experiments on a 6-link nonlinear robotic manipulator demonstrate accurate tracking and substantial computational speedup of 25$\times$ over a baseline approach.
Benchmarking State Space Models, Transformers, and Recurrent Networks for US Grid Forecasting
Feb 24, 2026Selecting the right deep learning model for power grid forecasting is challenging, as performance heavily depends on the data available to the operator. This paper presents a comprehensive benchmark of five modern neural architectures: two state space models (PowerMamba, S-Mamba), two Transformers (iTransformer, PatchTST), and a traditional LSTM. We evaluate these models on hourly electricity demand across six diverse US power grids for forecast windows between 24 and 168 hours. To ensure a fair comparison, we adapt each model with specialized temporal processing and a modular layer that cleanly integrates weather covariates. Our results reveal that there is no single best model for all situations. When forecasting using only historical load, PatchTST and the state space models provide the highest accuracy. However, when explicit weather data is added to the inputs, the rankings reverse: iTransformer improves its accuracy three times more efficiently than PatchTST. By controlling for model size, we confirm that this advantage stems from the architecture's inherent ability to mix information across different variables. Extending our evaluation to solar generation, wind power, and wholesale prices further demonstrates that model rankings depend on the forecast task: PatchTST excels on highly rhythmic signals like solar, while state space models are better suited for the chaotic fluctuations of wind and price. Ultimately, this benchmark provides grid operators with actionable guidelines for selecting the optimal forecasting architecture based on their specific data environments.
RN-D: Discretized Categorical Actors with Regularized Networks for On-Policy Reinforcement Learning
Jan 30, 2026On-policy deep reinforcement learning remains a dominant paradigm for continuous control, yet standard implementations rely on Gaussian actors and relatively shallow MLP policies, often leading to brittle optimization when gradients are noisy and policy updates must be conservative. In this paper, we revisit policy representation as a first-class design choice for on-policy optimization. We study discretized categorical actors that represent each action dimension with a distribution over bins, yielding a policy objective that resembles a cross-entropy loss. Building on architectural advances from supervised learning, we further propose regularized actor networks, while keeping critic design fixed. Our results show that simply replacing the standard actor network with our discretized regularized actor yields consistent gains and achieve the state-of-the-art performance across diverse continuous-control benchmarks.
Anatomical Region-Guided Contrastive Decoding: A Plug-and-Play Strategy for Mitigating Hallucinations in Medical VLMs
Dec 19, 2025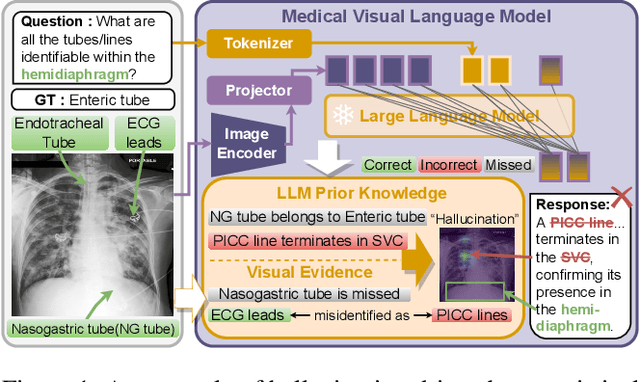
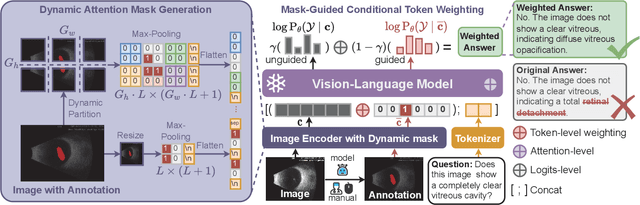

Medical Vision-Language Models (MedVLMs) show immense promise in clinical applicability. However, their reliability is hindered by hallucinations, where models often fail to derive answers from visual evidence, instead relying on learned textual priors. Existing mitigation strategies for MedVLMs have distinct limitations: training-based methods rely on costly expert annotations, limiting scalability, while training-free interventions like contrastive decoding, though data-efficient, apply a global, untargeted correction whose effects in complex real-world clinical settings can be unreliable. To address these challenges, we introduce Anatomical Region-Guided Contrastive Decoding (ARCD), a plug-and-play strategy that mitigates hallucinations by providing targeted, region-specific guidance. Our module leverages an anatomical mask to direct a three-tiered contrastive decoding process. By dynamically re-weighting at the token, attention, and logits levels, it verifiably steers the model's focus onto specified regions, reinforcing anatomical understanding and suppressing factually incorrect outputs. Extensive experiments across diverse datasets, including chest X-ray, CT, brain MRI, and ocular ultrasound, demonstrate our method's effectiveness in improving regional understanding, reducing hallucinations, and enhancing overall diagnostic accuracy.
Stabilization of nonlinear systems with unknown delays via delay-adaptive neural operator approximate predictors
Sep 30, 2025This work establishes the first rigorous stability guarantees for approximate predictors in delay-adaptive control of nonlinear systems, addressing a key challenge in practical implementations where exact predictors are unavailable. We analyze two scenarios: (i) when the actuated input is directly measurable, and (ii) when it is estimated online. For the measurable input case, we prove semi-global practical asymptotic stability with an explicit bound proportional to the approximation error $\epsilon$. For the unmeasured input case, we demonstrate local practical asymptotic stability, with the region of attraction explicitly dependent on both the initial delay estimate and the predictor approximation error. To bridge theory and practice, we show that neural operators-a flexible class of neural network-based approximators-can achieve arbitrarily small approximation errors, thus satisfying the conditions of our stability theorems. Numerical experiments on two nonlinear benchmark systems-a biological protein activator/repressor model and a micro-organism growth Chemostat model-validate our theoretical results. In particular, our numerical simulations confirm stability under approximate predictors, highlight the strong generalization capabilities of neural operators, and demonstrate a substantial computational speedup of up to 15x compared to a baseline fixed-point method.
Uncovering the Bigger Picture: Comprehensive Event Understanding Via Diverse News Retrieval
Aug 27, 2025Access to diverse perspectives is essential for understanding real-world events, yet most news retrieval systems prioritize textual relevance, leading to redundant results and limited viewpoint exposure. We propose NEWSCOPE, a two-stage framework for diverse news retrieval that enhances event coverage by explicitly modeling semantic variation at the sentence level. The first stage retrieves topically relevant content using dense retrieval, while the second stage applies sentence-level clustering and diversity-aware re-ranking to surface complementary information. To evaluate retrieval diversity, we introduce three interpretable metrics, namely Average Pairwise Distance, Positive Cluster Coverage, and Information Density Ratio, and construct two paragraph-level benchmarks: LocalNews and DSGlobal. Experiments show that NEWSCOPE consistently outperforms strong baselines, achieving significantly higher diversity without compromising relevance. Our results demonstrate the effectiveness of fine-grained, interpretable modeling in mitigating redundancy and promoting comprehensive event understanding. The data and code are available at https://github.com/tangyixuan/NEWSCOPE.
Data-driven operator learning for energy-efficient building control
Apr 30, 2025Energy-efficient ventilation control plays a vital role in reducing building energy consumption while ensuring occupant health and comfort. While Computational Fluid Dynamics (CFD) simulations offer high-fidelity modeling of airflow for building HVAC design, their high computational cost makes them impractical for practical adoption in real-time building management system. In this work, we present a data-driven framework that combines the physical accuracy of CFD with the computational efficiency of machine learning to enable energy-efficient building ventilation control. Our method jointly optimizes airflow supply rates and vent angles to reduce energy use and adhere to air quality constraints. We train a neural operator transformer to learn the mapping from building control actions to airflow field distributions using high-resolution CFD data. This learned operator enables a gradient-based control framework capable of optimal decision-making. Experimental results demonstrate that our approach achieves substantial energy savings compared to maximum airflow rate control, rule-based control, and data-driven control based on regional average CO2 predictions, while consistently maintaining safe indoor air quality. These results highlight the practicality and scalability of our method for enabling safe and energy-efficient building management.
Analytical Lyapunov Function Discovery: An RL-based Generative Approach
Feb 04, 2025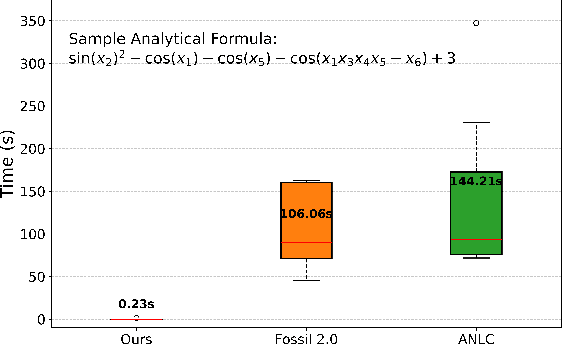

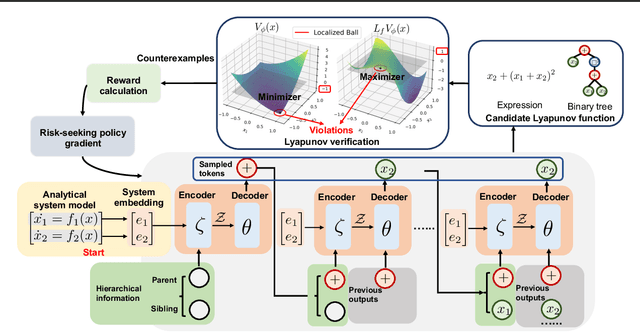

Despite advances in learning-based methods, finding valid Lyapunov functions for nonlinear dynamical systems remains challenging. Current neural network approaches face two main issues: challenges in scalable verification and limited interpretability. To address these, we propose an end-to-end framework using transformers to construct analytical Lyapunov functions (local), which simplifies formal verification, enhances interpretability, and provides valuable insights for control engineers. Our framework consists of a transformer-based trainer that generates candidate Lyapunov functions and a falsifier that verifies candidate expressions and refines the model via risk-seeking policy gradient. Unlike Alfarano et al. (2024), which utilizes pre-training and seeks global Lyapunov functions for low-dimensional systems, our model is trained from scratch via reinforcement learning (RL) and succeeds in finding local Lyapunov functions for high-dimensional and non-polynomial systems. Given the analytical nature of the candidates, we employ efficient optimization methods for falsification during training and formal verification tools for the final verification. We demonstrate the efficiency of our approach on a range of nonlinear dynamical systems with up to ten dimensions and show that it can discover Lyapunov functions not previously identified in the control literature.