 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Energy-Guided Diffusion Generation for Off-Dynamics Reinforcement Learning
May 24, 2026Off-dynamics offline reinforcement learning seeks to learn a target-domain policy from a large source dataset and a limited target dataset under mismatched transition dynamics. Existing approaches such as reward augmentation and data filtering are constrained to the source dataset and cannot synthesize new target behavior to improve coverage beyond the collected source trajectories. While recent model-based methods attempt to address this by learning target-aware dynamics, the generated experience is constructed only at the transition level, which leads to accumulated errors over long horizons. These limitations necessitate a shift toward trajectory-level generation for off-dynamics offline RL. We propose CEDGE, a Cross-domain Energy-guided Diffusion GEneration framework. CEDGE trains a trajectory diffusion model on source-domain trajectories and adapts the generated samples to the target domain through energy guidance. This guidance is derived by minimizing the distribution mismatch between the source and desired target-domain trajectories and is decomposed into return, domain, and behavior energy components. The resulting energy-guided trajectories are useful both for direct planning and as synthetic data for policy learning. Since target adaptation is achieved via energy guidance rather than retraining the diffusion model, CEDGE can be efficiently adapted to new target dynamics compared to previous methods. Experiments on the ODRL benchmark demonstrate that trajectory-level energy-guided generation improves diffusion planning under dynamics shifts and produces synthetic data that improves downstream target policy learning.
CorrectionPlanner: Self-Correction Planner with Reinforcement Learning in Autonomous Driving
Mar 16, 2026Autonomous driving requires safe planning, but most learning-based planners lack explicit self-correction ability: once an unsafe action is proposed, there is no mechanism to correct it. Thus, we propose CorrectionPlanner, an autoregressive planner with self-correction that models planning as motion-token generation within a propose, evaluate, and correct loop. At each planning step, the policy proposes an action, namely a motion token, and a learned collision critic predicts whether it will induce a collision within a short horizon. If the critic predicts a collision, we retain the sequence of historical unsafe motion tokens as a self-correction trace, generate the next motion token conditioned on it, and repeat this process until a safe motion token is proposed or the safety criterion is met. This self-correction trace, consisting of all unsafe motion tokens, represents the planner's correction process in motion-token space, analogous to a reasoning trace in language models. We train the planner with imitation learning followed by model-based reinforcement learning using rollouts from a pretrained world model that realistically models agents' reactive behaviors. Closed-loop evaluations show that CorrectionPlanner reduces collision rate by over 20% on Waymax and achieves state-of-the-art planning scores on nuPlan.
Group-Sensitive Offline Contextual Bandits
Oct 31, 2025Offline contextual bandits allow one to learn policies from historical/offline data without requiring online interaction. However, offline policy optimization that maximizes overall expected rewards can unintentionally amplify the reward disparities across groups. As a result, some groups might benefit more than others from the learned policy, raising concerns about fairness, especially when the resources are limited. In this paper, we study a group-sensitive fairness constraint in offline contextual bandits, reducing group-wise reward disparities that may arise during policy learning. We tackle the following common-parity requirements: the reward disparity is constrained within some user-defined threshold or the reward disparity should be minimized during policy optimization. We propose a constrained offline policy optimization framework by introducing group-wise reward disparity constraints into an off-policy gradient-based optimization procedure. To improve the estimation of the group-wise reward disparity during training, we employ a doubly robust estimator and further provide a convergence guarantee for policy optimization. Empirical results in synthetic and real-world datasets demonstrate that our method effectively reduces reward disparities while maintaining competitive overall performance.
MOBODY: Model Based Off-Dynamics Offline Reinforcement Learning
Jun 10, 2025We study the off-dynamics offline reinforcement learning problem, where the goal is to learn a policy from offline datasets collected from source and target domains with mismatched transition. Existing off-dynamics offline RL methods typically either filter source transitions that resemble those of the target domain or apply reward augmentation to source data, both constrained by the limited transitions available from the target domain. As a result, the learned policy is unable to explore target domain beyond the offline datasets. We propose MOBODY, a Model-Based Off-Dynamics offline RL algorithm that addresses this limitation by enabling exploration of the target domain via learned dynamics. MOBODY generates new synthetic transitions in the target domain through model rollouts, which are used as data augmentation during offline policy learning. Unlike existing model-based methods that learn dynamics from a single domain, MOBODY tackles the challenge of mismatched dynamics by leveraging both source and target datasets. Directly merging these datasets can bias the learned model toward source dynamics. Instead, MOBODY learns target dynamics by discovering a shared latent representation of states and transitions across domains through representation learning. To stabilize training, MOBODY incorporates a behavior cloning loss that regularizes the policy. Specifically, we introduce a Q-weighted behavior cloning loss that regularizes the policy toward actions with high target-domain Q-values, rather than uniformly imitating all actions in the dataset. These Q-values are learned from an enhanced target dataset composed of offline target data, augmented source data, and rollout data from the learned target dynamics. We evaluate MOBODY on MuJoCo benchmarks and show that it significantly outperforms state-of-the-art baselines, with especially pronounced improvements in challenging scenarios.
TSD-SR: One-Step Diffusion with Target Score Distillation for Real-World Image Super-Resolution
Nov 27, 2024



Pre-trained text-to-image diffusion models are increasingly applied to real-world image super-resolution (Real-ISR) task. Given the iterative refinement nature of diffusion models, most existing approaches are computationally expensive. While methods such as SinSR and OSEDiff have emerged to condense inference steps via distillation, their performance in image restoration or details recovery is not satisfied. To address this, we propose TSD-SR, a novel distillation framework specifically designed for real-world image super-resolution, aiming to construct an efficient and effective one-step model. We first introduce the Target Score Distillation, which leverages the priors of diffusion models and real image references to achieve more realistic image restoration. Secondly, we propose a Distribution-Aware Sampling Module to make detail-oriented gradients more readily accessible, addressing the challenge of recovering fine details. Extensive experiments demonstrate that our TSD-SR has superior restoration results (most of the metrics perform the best) and the fastest inference speed (e.g. 40 times faster than SeeSR) compared to the past Real-ISR approaches based on pre-trained diffusion priors.
Off-Dynamics Reinforcement Learning via Domain Adaptation and Reward Augmented Imitation
Nov 15, 2024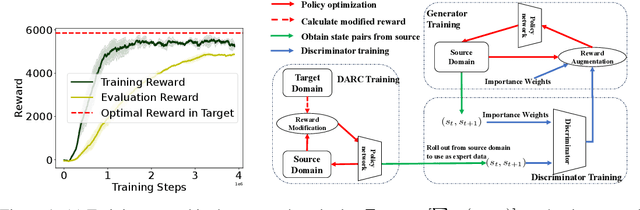
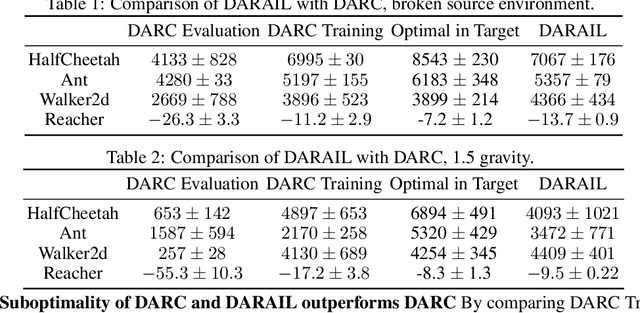
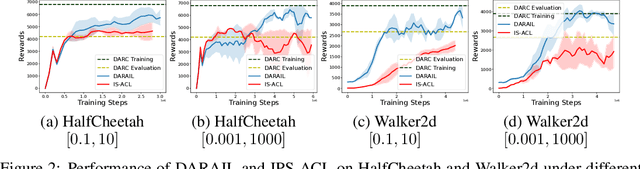
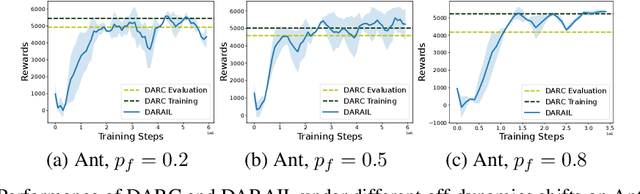
Training a policy in a source domain for deployment in the target domain under a dynamics shift can be challenging, often resulting in performance degradation. Previous work tackles this challenge by training on the source domain with modified rewards derived by matching distributions between the source and the target optimal trajectories. However, pure modified rewards only ensure the behavior of the learned policy in the source domain resembles trajectories produced by the target optimal policies, which does not guarantee optimal performance when the learned policy is actually deployed to the target domain. In this work, we propose to utilize imitation learning to transfer the policy learned from the reward modification to the target domain so that the new policy can generate the same trajectories in the target domain. Our approach, Domain Adaptation and Reward Augmented Imitation Learning (DARAIL), utilizes the reward modification for domain adaptation and follows the general framework of generative adversarial imitation learning from observation (GAIfO) by applying a reward augmented estimator for the policy optimization step. Theoretically, we present an error bound for our method under a mild assumption regarding the dynamics shift to justify the motivation of our method. Empirically, our method outperforms the pure modified reward method without imitation learning and also outperforms other baselines in benchmark off-dynamics environments.
Distributionally Robust Policy Evaluation under General Covariate Shift in Contextual Bandits
Jan 21, 2024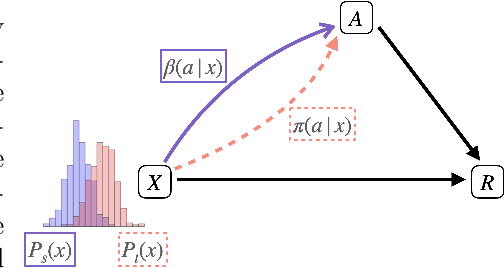



We introduce a distributionally robust approach that enhances the reliability of offline policy evaluation in contextual bandits under general covariate shifts. Our method aims to deliver robust policy evaluation results in the presence of discrepancies in both context and policy distribution between logging and target data. Central to our methodology is the application of robust regression, a distributionally robust technique tailored here to improve the estimation of conditional reward distribution from logging data. Utilizing the reward model obtained from robust regression, we develop a comprehensive suite of policy value estimators, by integrating our reward model into established evaluation frameworks, namely direct methods and doubly robust methods. Through theoretical analysis, we further establish that the proposed policy value estimators offer a finite sample upper bound for the bias, providing a clear advantage over traditional methods, especially when the shift is large. Finally, we designed an extensive range of policy evaluation scenarios, covering diverse magnitudes of shifts and a spectrum of logging and target policies. Our empirical results indicate that our approach significantly outperforms baseline methods, most notably in 90% of the cases under the policy shift-only settings and 72% of the scenarios under the general covariate shift settings.