 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Arithmetic Gap: The Cognitive Complexity Benchmark and Financial-PoT for Robust Financial Reasoning
Jan 29, 2026While Large Language Models excel at semantic tasks, they face a critical bottleneck in financial quantitative reasoning, frequently suffering from "Arithmetic Hallucinations" and a systemic failure mode we term "Cognitive Collapse". To strictly quantify this phenomenon, we introduce the Cognitive Complexity Benchmark (CCB), a robust evaluation framework grounded in a dataset constructed from 95 real-world Chinese A-share annual reports. Unlike traditional datasets, the CCB stratifies financial queries into a three-dimensional taxonomy, Data Source, Mapping Difficulty, and Result Unit, enabling the precise diagnosis of reasoning degradation in high-cognitive-load scenarios. To address these failures, we propose the Iterative Dual-Phase Financial-PoT framework. This neuro-symbolic architecture enforces a strict architectural decoupling: it first isolates semantic variable extraction and logic formulation, then offloads computation to an iterative, self-correcting Python sandbox to ensure deterministic execution. Evaluation on the CCB demonstrates that while standard Chain-of-Thought falters on complex tasks, our approach offers superior robustness, elevating the Qwen3-235B model's average accuracy from 59.7\% to 67.3\% and achieving gains of up to 10-fold in high-complexity reasoning tasks. These findings suggest that architectural decoupling is a critical enabling factor for improving reliability in financial reasoning tasks, providing a transferable architectural insight for precision-critical domains that require tight alignment between semantic understanding and quantitative computation.
OpenGT: A Comprehensive Benchmark For Graph Transformers
Jun 05, 2025Graph Transformers (GTs) have recently demonstrated remarkable performance across diverse domains. By leveraging attention mechanisms, GTs are capable of modeling long-range dependencies and complex structural relationships beyond local neighborhoods. However, their applicable scenarios are still underexplored, this highlights the need to identify when and why they excel. Furthermore, unlike GNNs, which predominantly rely on message-passing mechanisms, GTs exhibit a diverse design space in areas such as positional encoding, attention mechanisms, and graph-specific adaptations. Yet, it remains unclear which of these design choices are truly effective and under what conditions. As a result, the community currently lacks a comprehensive benchmark and library to promote a deeper understanding and further development of GTs. To address this gap, this paper introduces OpenGT, a comprehensive benchmark for Graph Transformers. OpenGT enables fair comparisons and multidimensional analysis by establishing standardized experimental settings and incorporating a broad selection of state-of-the-art GNNs and GTs. Our benchmark evaluates GTs from multiple perspectives, encompassing diverse tasks and datasets with varying properties. Through extensive experiments, our benchmark has uncovered several critical insights, including the difficulty of transferring models across task levels, the limitations of local attention, the efficiency trade-offs in several models, the application scenarios of specific positional encodings, and the preprocessing overhead of some positional encodings. We aspire for this work to establish a foundation for future graph transformer research emphasizing fairness, reproducibility, and generalizability. We have developed an easy-to-use library OpenGT for training and evaluating existing GTs. The benchmark code is available at https://github.com/eaglelab-zju/OpenGT.
TurboFill: Adapting Few-step Text-to-image Model for Fast Image Inpainting
Apr 01, 2025This paper introduces TurboFill, a fast image inpainting model that enhances a few-step text-to-image diffusion model with an inpainting adapter for high-quality and efficient inpainting. While standard diffusion models generate high-quality results, they incur high computational costs. We overcome this by training an inpainting adapter on a few-step distilled text-to-image model, DMD2, using a novel 3-step adversarial training scheme to ensure realistic, structurally consistent, and visually harmonious inpainted regions. To evaluate TurboFill, we propose two benchmarks: DilationBench, which tests performance across mask sizes, and HumanBench, based on human feedback for complex prompts. Experiments show that TurboFill outperforms both multi-step BrushNet and few-step inpainting methods, setting a new benchmark for high-performance inpainting tasks. Our project page: https://liangbinxie.github.io/projects/TurboFill/
TSD-SR: One-Step Diffusion with Target Score Distillation for Real-World Image Super-Resolution
Nov 27, 2024



Pre-trained text-to-image diffusion models are increasingly applied to real-world image super-resolution (Real-ISR) task. Given the iterative refinement nature of diffusion models, most existing approaches are computationally expensive. While methods such as SinSR and OSEDiff have emerged to condense inference steps via distillation, their performance in image restoration or details recovery is not satisfied. To address this, we propose TSD-SR, a novel distillation framework specifically designed for real-world image super-resolution, aiming to construct an efficient and effective one-step model. We first introduce the Target Score Distillation, which leverages the priors of diffusion models and real image references to achieve more realistic image restoration. Secondly, we propose a Distribution-Aware Sampling Module to make detail-oriented gradients more readily accessible, addressing the challenge of recovering fine details. Extensive experiments demonstrate that our TSD-SR has superior restoration results (most of the metrics perform the best) and the fastest inference speed (e.g. 40 times faster than SeeSR) compared to the past Real-ISR approaches based on pre-trained diffusion priors.
OOD-SEG: Out-Of-Distribution detection for image SEGmentation with sparse multi-class positive-only annotations
Nov 14, 2024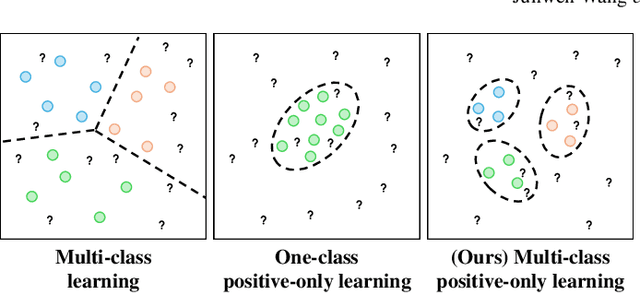


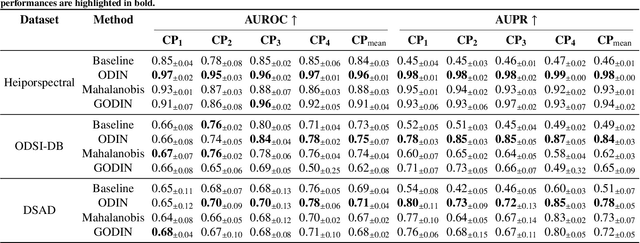
Despite significant advancements, segmentation based on deep neural networks in medical and surgical imaging faces several challenges, two of which we aim to address in this work. First, acquiring complete pixel-level segmentation labels for medical images is time-consuming and requires domain expertise. Second, typical segmentation pipelines cannot detect out-of-distribution (OOD) pixels, leaving them prone to spurious outputs during deployment. In this work, we propose a novel segmentation approach exploiting OOD detection that learns only from sparsely annotated pixels from multiple positive-only classes. %but \emph{no background class} annotation. These multi-class positive annotations naturally fall within the in-distribution (ID) set. Unlabelled pixels may contain positive classes but also negative ones, including what is typically referred to as \emph{background} in standard segmentation formulations. Here, we forgo the need for background annotation and consider these together with any other unseen classes as part of the OOD set. Our framework can integrate, at a pixel-level, any OOD detection approaches designed for classification tasks. To address the lack of existing OOD datasets and established evaluation metric for medical image segmentation, we propose a cross-validation strategy that treats held-out labelled classes as OOD. Extensive experiments on both multi-class hyperspectral and RGB surgical imaging datasets demonstrate the robustness and generalisation capability of our proposed framework.
Xinyu: An Efficient LLM-based System for Commentary Generation
Aug 21, 2024



Commentary provides readers with a deep understanding of events by presenting diverse arguments and evidence. However, creating commentary is a time-consuming task, even for skilled commentators. Large language models (LLMs) have simplified the process of natural language generation, but their direct application in commentary creation still faces challenges due to unique task requirements. These requirements can be categorized into two levels: 1) fundamental requirements, which include creating well-structured and logically consistent narratives, and 2) advanced requirements, which involve generating quality arguments and providing convincing evidence. In this paper, we introduce Xinyu, an efficient LLM-based system designed to assist commentators in generating Chinese commentaries. To meet the fundamental requirements, we deconstruct the generation process into sequential steps, proposing targeted strategies and supervised fine-tuning (SFT) for each step. To address the advanced requirements, we present an argument ranking model for arguments and establish a comprehensive evidence database that includes up-to-date events and classic books, thereby strengthening the substantiation of the evidence with retrieval augmented generation (RAG) technology. To evaluate the generated commentaries more fairly, corresponding to the two-level requirements, we introduce a comprehensive evaluation metric that considers five distinct perspectives in commentary generation. Our experiments confirm the effectiveness of our proposed system. We also observe a significant increase in the efficiency of commentators in real-world scenarios, with the average time spent on creating a commentary dropping from 4 hours to 20 minutes. Importantly, such an increase in efficiency does not compromise the quality of the commentaries.
Scribble-Based Interactive Segmentation of Medical Hyperspectral Images
Aug 05, 2024

Hyperspectral imaging (HSI) is an advanced medical imaging modality that captures optical data across a broad spectral range, providing novel insights into the biochemical composition of tissues. HSI may enable precise differentiation between various tissue types and pathologies, making it particularly valuable for tumour detection, tissue classification, and disease diagnosis. Deep learning-based segmentation methods have shown considerable advancements, offering automated and accurate results. However, these methods face challenges with HSI datasets due to limited annotated data and discrepancies from hardware and acquisition techniques~\cite{clancy2020surgical,studier2023heiporspectral}. Variability in clinical protocols also leads to different definitions of structure boundaries. Interactive segmentation methods, utilizing user knowledge and clinical insights, can overcome these issues and achieve precise segmentation results \cite{zhao2013overview}. This work introduces a scribble-based interactive segmentation framework for medical hyperspectral images. The proposed method utilizes deep learning for feature extraction and a geodesic distance map generated from user-provided scribbles to obtain the segmentation results. The experiment results show that utilising the geodesic distance maps based on deep learning-extracted features achieved better segmentation results than geodesic distance maps directly generated from hyperspectral images, reconstructed RGB images, or Euclidean distance maps.
NoisyGL: A Comprehensive Benchmark for Graph Neural Networks under Label Noise
Jun 07, 2024

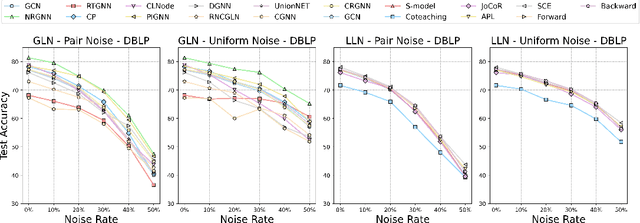

Graph Neural Networks (GNNs) exhibit strong potential in node classification task through a message-passing mechanism. However, their performance often hinges on high-quality node labels, which are challenging to obtain in real-world scenarios due to unreliable sources or adversarial attacks. Consequently, label noise is common in real-world graph data, negatively impacting GNNs by propagating incorrect information during training. To address this issue, the study of Graph Neural Networks under Label Noise (GLN) has recently gained traction. However, due to variations in dataset selection, data splitting, and preprocessing techniques, the community currently lacks a comprehensive benchmark, which impedes deeper understanding and further development of GLN. To fill this gap, we introduce NoisyGL in this paper, the first comprehensive benchmark for graph neural networks under label noise. NoisyGL enables fair comparisons and detailed analyses of GLN methods on noisy labeled graph data across various datasets, with unified experimental settings and interface. Our benchmark has uncovered several important insights that were missed in previous research, and we believe these findings will be highly beneficial for future studies. We hope our open-source benchmark library will foster further advancements in this field. The code of the benchmark can be found in https://github.com/eaglelab-zju/NoisyGL.
HiFi Tuner: High-Fidelity Subject-Driven Fine-Tuning for Diffusion Models
Nov 30, 2023



This paper explores advancements in high-fidelity personalized image generation through the utilization of pre-trained text-to-image diffusion models. While previous approaches have made significant strides in generating versatile scenes based on text descriptions and a few input images, challenges persist in maintaining the subject fidelity within the generated images. In this work, we introduce an innovative algorithm named HiFi Tuner to enhance the appearance preservation of objects during personalized image generation. Our proposed method employs a parameter-efficient fine-tuning framework, comprising a denoising process and a pivotal inversion process. Key enhancements include the utilization of mask guidance, a novel parameter regularization technique, and the incorporation of step-wise subject representations to elevate the sample fidelity. Additionally, we propose a reference-guided generation approach that leverages the pivotal inversion of a reference image to mitigate unwanted subject variations and artifacts. We further extend our method to a novel image editing task: substituting the subject in an image through textual manipulations. Experimental evaluations conducted on the DreamBooth dataset using the Stable Diffusion model showcase promising results. Fine-tuning solely on textual embeddings improves CLIP-T score by 3.6 points and improves DINO score by 9.6 points over Textual Inversion. When fine-tuning all parameters, HiFi Tuner improves CLIP-T score by 1.2 points and improves DINO score by 1.2 points over DreamBooth, establishing a new state of the art.
UHGEval: Benchmarking the Hallucination of Chinese Large Language Models via Unconstrained Generation
Nov 26, 2023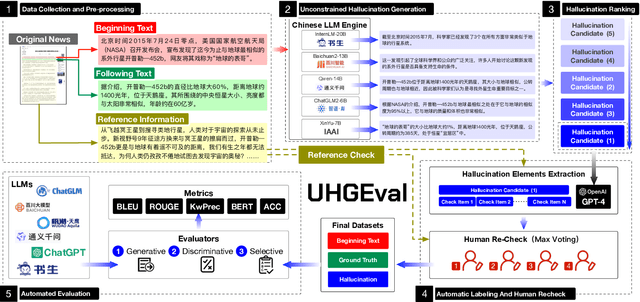
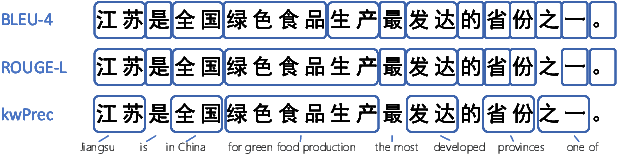

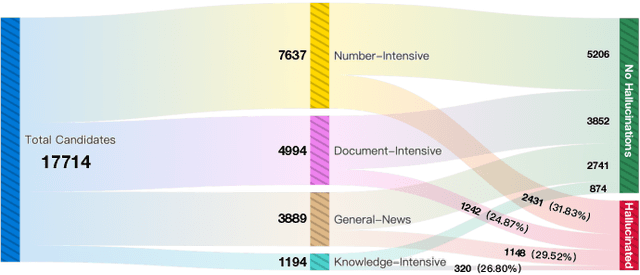
Large language models (LLMs) have emerged as pivotal contributors in contemporary natural language processing and are increasingly being applied across a diverse range of industries. However, these large-scale probabilistic statistical models cannot currently ensure the requisite quality in professional content generation. These models often produce hallucinated text, compromising their practical utility in professional contexts. To assess the authentic reliability of LLMs in text generation, numerous initiatives have developed benchmark evaluations for hallucination phenomena. Nevertheless, these benchmarks frequently utilize constrained generation techniques due to cost and temporal constraints. These techniques encompass the use of directed hallucination induction and strategies that deliberately alter authentic text to produce hallucinations. These approaches are not congruent with the unrestricted text generation demanded by real-world applications. Furthermore, a well-established Chinese-language dataset dedicated to the evaluation of hallucinations in text generation is presently lacking. Consequently, we have developed an Unconstrained Hallucination Generation Evaluation (UHGEval) benchmark, designed to compile outputs produced with minimal restrictions by LLMs. Concurrently, we have established a comprehensive benchmark evaluation framework to aid subsequent researchers in undertaking scalable and reproducible experiments. We have also executed extensive experiments, evaluating prominent Chinese language models and the GPT series models to derive professional performance insights regarding hallucination challenges.