 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoth Semantics and Reconstruction Matter: Making Representation Encoders Ready for Text-to-Image Generation and Editing
Dec 19, 2025Modern Latent Diffusion Models (LDMs) typically operate in low-level Variational Autoencoder (VAE) latent spaces that are primarily optimized for pixel-level reconstruction. To unify vision generation and understanding, a burgeoning trend is to adopt high-dimensional features from representation encoders as generative latents. However, we empirically identify two fundamental obstacles in this paradigm: (1) the discriminative feature space lacks compact regularization, making diffusion models prone to off-manifold latents that lead to inaccurate object structures; and (2) the encoder's inherently weak pixel-level reconstruction hinders the generator from learning accurate fine-grained geometry and texture. In this paper, we propose a systematic framework to adapt understanding-oriented encoder features for generative tasks. We introduce a semantic-pixel reconstruction objective to regularize the latent space, enabling the compression of both semantic information and fine-grained details into a highly compact representation (96 channels with 16x16 spatial downsampling). This design ensures that the latent space remains semantically rich and achieves state-of-the-art image reconstruction, while remaining compact enough for accurate generation. Leveraging this representation, we design a unified Text-to-Image (T2I) and image editing model. Benchmarking against various feature spaces, we demonstrate that our approach achieves state-of-the-art reconstruction, faster convergence, and substantial performance gains in both T2I and editing tasks, validating that representation encoders can be effectively adapted into robust generative components.
CompleteMe: Reference-based Human Image Completion
Apr 28, 2025Recent methods for human image completion can reconstruct plausible body shapes but often fail to preserve unique details, such as specific clothing patterns or distinctive accessories, without explicit reference images. Even state-of-the-art reference-based inpainting approaches struggle to accurately capture and integrate fine-grained details from reference images. To address this limitation, we propose CompleteMe, a novel reference-based human image completion framework. CompleteMe employs a dual U-Net architecture combined with a Region-focused Attention (RFA) Block, which explicitly guides the model's attention toward relevant regions in reference images. This approach effectively captures fine details and ensures accurate semantic correspondence, significantly improving the fidelity and consistency of completed images. Additionally, we introduce a challenging benchmark specifically designed for evaluating reference-based human image completion tasks. Extensive experiments demonstrate that our proposed method achieves superior visual quality and semantic consistency compared to existing techniques. Project page: https://liagm.github.io/CompleteMe/
TurboFill: Adapting Few-step Text-to-image Model for Fast Image Inpainting
Apr 01, 2025This paper introduces TurboFill, a fast image inpainting model that enhances a few-step text-to-image diffusion model with an inpainting adapter for high-quality and efficient inpainting. While standard diffusion models generate high-quality results, they incur high computational costs. We overcome this by training an inpainting adapter on a few-step distilled text-to-image model, DMD2, using a novel 3-step adversarial training scheme to ensure realistic, structurally consistent, and visually harmonious inpainted regions. To evaluate TurboFill, we propose two benchmarks: DilationBench, which tests performance across mask sizes, and HumanBench, based on human feedback for complex prompts. Experiments show that TurboFill outperforms both multi-step BrushNet and few-step inpainting methods, setting a new benchmark for high-performance inpainting tasks. Our project page: https://liangbinxie.github.io/projects/TurboFill/
Generative Image Layer Decomposition with Visual Effects
Nov 26, 2024



Recent advancements in large generative models, particularly diffusion-based methods, have significantly enhanced the capabilities of image editing. However, achieving precise control over image composition tasks remains a challenge. Layered representations, which allow for independent editing of image components, are essential for user-driven content creation, yet existing approaches often struggle to decompose image into plausible layers with accurately retained transparent visual effects such as shadows and reflections. We propose $\textbf{LayerDecomp}$, a generative framework for image layer decomposition which outputs photorealistic clean backgrounds and high-quality transparent foregrounds with faithfully preserved visual effects. To enable effective training, we first introduce a dataset preparation pipeline that automatically scales up simulated multi-layer data with synthesized visual effects. To further enhance real-world applicability, we supplement this simulated dataset with camera-captured images containing natural visual effects. Additionally, we propose a consistency loss which enforces the model to learn accurate representations for the transparent foreground layer when ground-truth annotations are not available. Our method achieves superior quality in layer decomposition, outperforming existing approaches in object removal and spatial editing tasks across several benchmarks and multiple user studies, unlocking various creative possibilities for layer-wise image editing. The project page is https://rayjryang.github.io/LayerDecomp.
Object-level Scene Deocclusion
Jun 11, 2024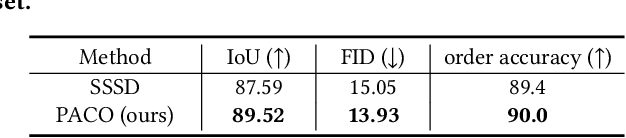

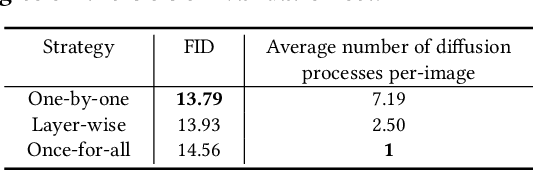
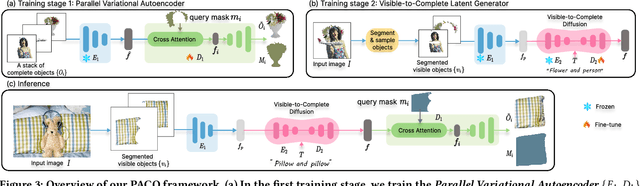
Deoccluding the hidden portions of objects in a scene is a formidable task, particularly when addressing real-world scenes. In this paper, we present a new self-supervised PArallel visible-to-COmplete diffusion framework, named PACO, a foundation model for object-level scene deocclusion. Leveraging the rich prior of pre-trained models, we first design the parallel variational autoencoder, which produces a full-view feature map that simultaneously encodes multiple complete objects, and the visible-to-complete latent generator, which learns to implicitly predict the full-view feature map from partial-view feature map and text prompts extracted from the incomplete objects in the input image. To train PACO, we create a large-scale dataset with 500k samples to enable self-supervised learning, avoiding tedious annotations of the amodal masks and occluded regions. At inference, we devise a layer-wise deocclusion strategy to improve efficiency while maintaining the deocclusion quality. Extensive experiments on COCOA and various real-world scenes demonstrate the superior capability of PACO for scene deocclusion, surpassing the state of the arts by a large margin. Our method can also be extended to cross-domain scenes and novel categories that are not covered by the training set. Further, we demonstrate the deocclusion applicability of PACO in single-view 3D scene reconstruction and object recomposition.
Segmentation in Style: Unsupervised Semantic Image Segmentation with Stylegan and CLIP
Jul 26, 2021

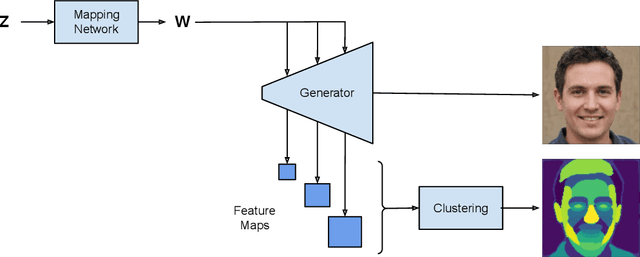
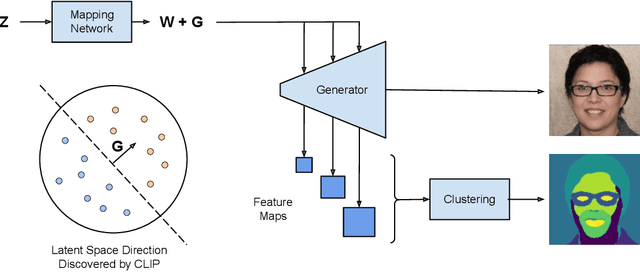
We introduce a method that allows to automatically segment images into semantically meaningful regions without human supervision. Derived regions are consistent across different images and coincide with human-defined semantic classes on some datasets. In cases where semantic regions might be hard for human to define and consistently label, our method is still able to find meaningful and consistent semantic classes. In our work, we use pretrained StyleGAN2~\cite{karras2020analyzing} generative model: clustering in the feature space of the generative model allows to discover semantic classes. Once classes are discovered, a synthetic dataset with generated images and corresponding segmentation masks can be created. After that a segmentation model is trained on the synthetic dataset and is able to generalize to real images. Additionally, by using CLIP~\cite{radford2021learning} we are able to use prompts defined in a natural language to discover some desired semantic classes. We test our method on publicly available datasets and show state-of-the-art results.
Delta Sampling R-BERT for limited data and low-light action recognition
Jul 12, 2021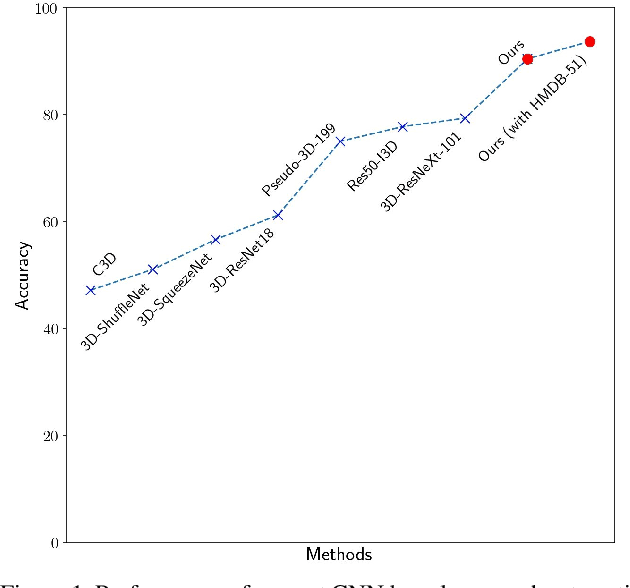


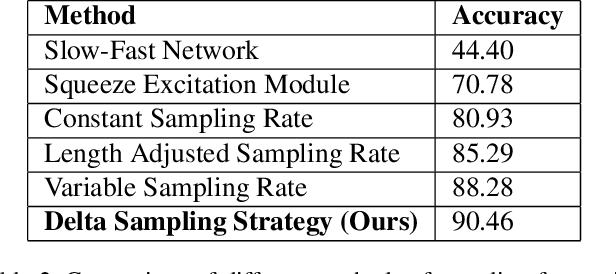
We present an approach to perform supervised action recognition in the dark. In this work, we present our results on the ARID dataset. Most previous works only evaluate performance on large, well illuminated datasets like Kinetics and HMDB51. We demonstrate that our work is able to achieve a very low error rate while being trained on a much smaller dataset of dark videos. We also explore a variety of training and inference strategies including domain transfer methodologies and also propose a simple but useful frame selection strategy. Our empirical results demonstrate that we beat previously published baseline models by 11%.
Towards Unsupervised Learning for Instrument Segmentation in Robotic Surgery with Cycle-Consistent Adversarial Networks
Jul 09, 2020
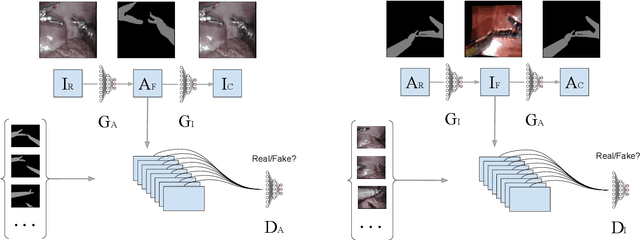

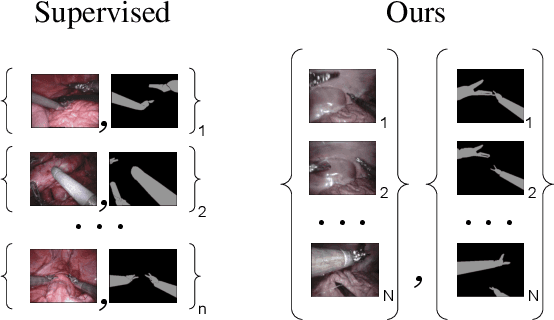
Surgical tool segmentation in endoscopic images is an important problem: it is a crucial step towards full instrument pose estimation and it is used for integration of pre- and intra-operative images into the endoscopic view. While many recent approaches based on convolutional neural networks have shown great results, a key barrier to progress lies in the acquisition of a large number of manually-annotated images which is necessary for an algorithm to generalize and work well in diverse surgical scenarios. Unlike the surgical image data itself, annotations are difficult to acquire and may be of variable quality. On the other hand, synthetic annotations can be automatically generated by using forward kinematic model of the robot and CAD models of tools by projecting them onto an image plane. Unfortunately, this model is very inaccurate and cannot be used for supervised learning of image segmentation models. Since generated annotations will not directly correspond to endoscopic images due to errors, we formulate the problem as an unpaired image-to-image translation where the goal is to learn the mapping between an input endoscopic image and a corresponding annotation using an adversarial model. Our approach allows to train image segmentation models without the need to acquire expensive annotations and can potentially exploit large unlabeled endoscopic image collection outside the annotated distributions of image/annotation data. We test our proposed method on Endovis 2017 challenge dataset and show that it is competitive with supervised segmentation methods.
Searching for Efficient Architecture for Instrument Segmentation in Robotic Surgery
Jul 08, 2020
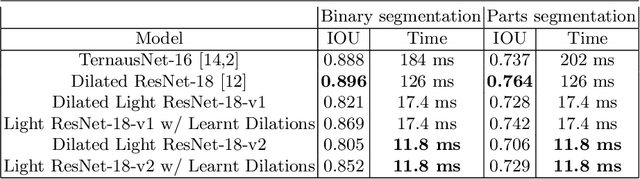


Segmentation of surgical instruments is an important problem in robot-assisted surgery: it is a crucial step towards full instrument pose estimation and is directly used for masking of augmented reality overlays during surgical procedures. Most applications rely on accurate real-time segmentation of high-resolution surgical images. While previous research focused primarily on methods that deliver high accuracy segmentation masks, majority of them can not be used for real-time applications due to their computational cost. In this work, we design a light-weight and highly-efficient deep residual architecture which is tuned to perform real-time inference of high-resolution images. To account for reduced accuracy of the discovered light-weight deep residual network and avoid adding any additional computational burden, we perform a differentiable search over dilation rates for residual units of our network. We test our discovered architecture on the EndoVis 2017 Robotic Instruments dataset and verify that our model is the state-of-the-art in terms of speed and accuracy tradeoff with a speed of up to 125 FPS on high resolution images.
Comparative evaluation of instrument segmentation and tracking methods in minimally invasive surgery
May 07, 2018
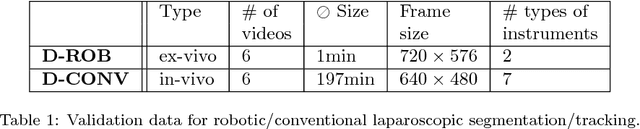

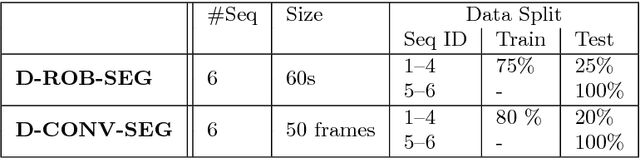
Intraoperative segmentation and tracking of minimally invasive instruments is a prerequisite for computer- and robotic-assisted surgery. Since additional hardware like tracking systems or the robot encoders are cumbersome and lack accuracy, surgical vision is evolving as promising techniques to segment and track the instruments using only the endoscopic images. However, what is missing so far are common image data sets for consistent evaluation and benchmarking of algorithms against each other. The paper presents a comparative validation study of different vision-based methods for instrument segmentation and tracking in the context of robotic as well as conventional laparoscopic surgery. The contribution of the paper is twofold: we introduce a comprehensive validation data set that was provided to the study participants and present the results of the comparative validation study. Based on the results of the validation study, we arrive at the conclusion that modern deep learning approaches outperform other methods in instrument segmentation tasks, but the results are still not perfect. Furthermore, we show that merging results from different methods actually significantly increases accuracy in comparison to the best stand-alone method. On the other hand, the results of the instrument tracking task show that this is still an open challenge, especially during challenging scenarios in conventional laparoscopic surgery.