 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlbumFill: Album-Guided Reasoning and Retrieval for Personalized Image Completion
May 04, 2026Personalized image completion aims to restore occluded regions in personal photos while preserving identity and appearance. Existing methods either rely on generic inpainting models that often fail to maintain identity consistency, or assume that suitable reference images are explicitly provided. In practice, suitable references are often not explicitly provided, requiring the system to search for identity-consistent images within personal photo collections. We present AlbumFill, a training-free framework that retrieves identity-consistent references from personal albums for personalized completion. Given an occluded image and a personal album, a vision-language model infers missing semantic cues to guide composed image retrieval, and the retrieved references are used by reference-based completion models. To facilitate this task, we introduce a dataset containing 54K human-centric samples with associated album images. Experiments across multiple baselines demonstrate the difficulty of personalized completion and highlight the importance of identity-consistent reference retrieval. Project Page: https://liagm.github.io/AlbumFill/
LightMover: Generative Light Movement with Color and Intensity Controls
Mar 28, 2026We present LightMover, a framework for controllable light manipulation in single images that leverages video diffusion priors to produce physically plausible illumination changes without re-rendering the scene. We formulate light editing as a sequence-to-sequence prediction problem in visual token space: given an image and light-control tokens, the model adjusts light position, color, and intensity together with resulting reflections, shadows, and falloff from a single view. This unified treatment of spatial (movement) and appearance (color, intensity) controls improves both manipulation and illumination understanding. We further introduce an adaptive token-pruning mechanism that preserves spatially informative tokens while compactly encoding non-spatial attributes, reducing control sequence length by 41% while maintaining editing fidelity. To train our framework, we construct a scalable rendering pipeline that generates large numbers of image pairs across varied light positions, colors, and intensities while keeping the scene content consistent with the original image. LightMover enables precise, independent control over light position, color, and intensity, and achieves high PSNR and strong semantic consistency (DINO, CLIP) across different tasks.
CompleteMe: Reference-based Human Image Completion
Apr 28, 2025Recent methods for human image completion can reconstruct plausible body shapes but often fail to preserve unique details, such as specific clothing patterns or distinctive accessories, without explicit reference images. Even state-of-the-art reference-based inpainting approaches struggle to accurately capture and integrate fine-grained details from reference images. To address this limitation, we propose CompleteMe, a novel reference-based human image completion framework. CompleteMe employs a dual U-Net architecture combined with a Region-focused Attention (RFA) Block, which explicitly guides the model's attention toward relevant regions in reference images. This approach effectively captures fine details and ensures accurate semantic correspondence, significantly improving the fidelity and consistency of completed images. Additionally, we introduce a challenging benchmark specifically designed for evaluating reference-based human image completion tasks. Extensive experiments demonstrate that our proposed method achieves superior visual quality and semantic consistency compared to existing techniques. Project page: https://liagm.github.io/CompleteMe/
MetaShadow: Object-Centered Shadow Detection, Removal, and Synthesis
Dec 03, 2024



Shadows are often under-considered or even ignored in image editing applications, limiting the realism of the edited results. In this paper, we introduce MetaShadow, a three-in-one versatile framework that enables detection, removal, and controllable synthesis of shadows in natural images in an object-centered fashion. MetaShadow combines the strengths of two cooperative components: Shadow Analyzer, for object-centered shadow detection and removal, and Shadow Synthesizer, for reference-based controllable shadow synthesis. Notably, we optimize the learning of the intermediate features from Shadow Analyzer to guide Shadow Synthesizer to generate more realistic shadows that blend seamlessly with the scene. Extensive evaluations on multiple shadow benchmark datasets show significant improvements of MetaShadow over the existing state-of-the-art methods on object-centered shadow detection, removal, and synthesis. MetaShadow excels in image-editing tasks such as object removal, relocation, and insertion, pushing the boundaries of object-centered image editing.
Refine-by-Align: Reference-Guided Artifacts Refinement through Semantic Alignment
Nov 30, 2024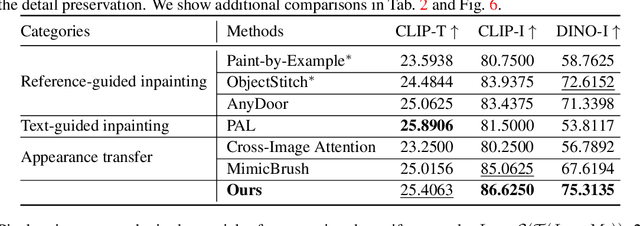

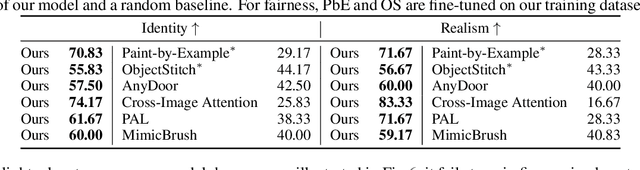
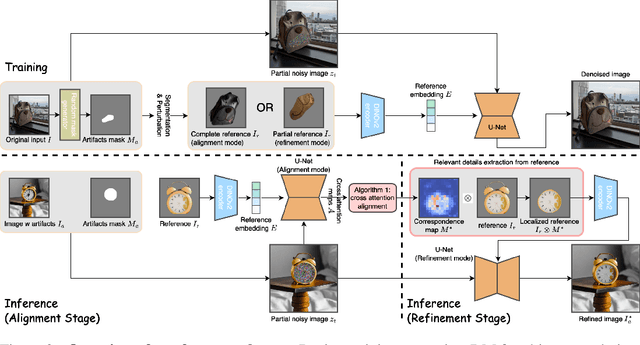
Personalized image generation has emerged from the recent advancements in generative models. However, these generated personalized images often suffer from localized artifacts such as incorrect logos, reducing fidelity and fine-grained identity details of the generated results. Furthermore, there is little prior work tackling this problem. To help improve these identity details in the personalized image generation, we introduce a new task: reference-guided artifacts refinement. We present Refine-by-Align, a first-of-its-kind model that employs a diffusion-based framework to address this challenge. Our model consists of two stages: Alignment Stage and Refinement Stage, which share weights of a unified neural network model. Given a generated image, a masked artifact region, and a reference image, the alignment stage identifies and extracts the corresponding regional features in the reference, which are then used by the refinement stage to fix the artifacts. Our model-agnostic pipeline requires no test-time tuning or optimization. It automatically enhances image fidelity and reference identity in the generated image, generalizing well to existing models on various tasks including but not limited to customization, generative compositing, view synthesis, and virtual try-on. Extensive experiments and comparisons demonstrate that our pipeline greatly pushes the boundary of fine details in the image synthesis models.
FairDeDup: Detecting and Mitigating Vision-Language Fairness Disparities in Semantic Dataset Deduplication
Apr 24, 2024



Recent dataset deduplication techniques have demonstrated that content-aware dataset pruning can dramatically reduce the cost of training Vision-Language Pretrained (VLP) models without significant performance losses compared to training on the original dataset. These results have been based on pruning commonly used image-caption datasets collected from the web -- datasets that are known to harbor harmful social biases that may then be codified in trained models. In this work, we evaluate how deduplication affects the prevalence of these biases in the resulting trained models and introduce an easy-to-implement modification to the recent SemDeDup algorithm that can reduce the negative effects that we observe. When examining CLIP-style models trained on deduplicated variants of LAION-400M, we find our proposed FairDeDup algorithm consistently leads to improved fairness metrics over SemDeDup on the FairFace and FACET datasets while maintaining zero-shot performance on CLIP benchmarks.
FINEMATCH: Aspect-based Fine-grained Image and Text Mismatch Detection and Correction
Apr 23, 2024

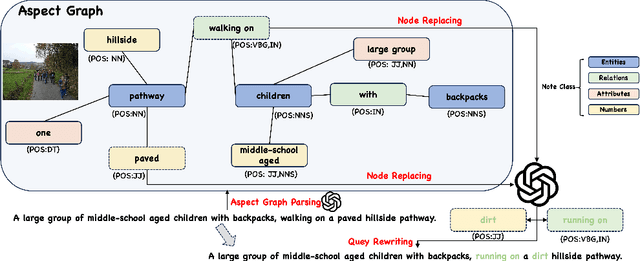
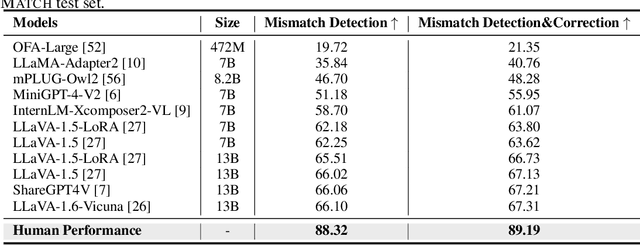
Recent progress in large-scale pre-training has led to the development of advanced vision-language models (VLMs) with remarkable proficiency in comprehending and generating multimodal content. Despite the impressive ability to perform complex reasoning for VLMs, current models often struggle to effectively and precisely capture the compositional information on both the image and text sides. To address this, we propose FineMatch, a new aspect-based fine-grained text and image matching benchmark, focusing on text and image mismatch detection and correction. This benchmark introduces a novel task for boosting and evaluating the VLMs' compositionality for aspect-based fine-grained text and image matching. In this task, models are required to identify mismatched aspect phrases within a caption, determine the aspect's class, and propose corrections for an image-text pair that may contain between 0 and 3 mismatches. To evaluate the models' performance on this new task, we propose a new evaluation metric named ITM-IoU for which our experiments show a high correlation to human evaluation. In addition, we also provide a comprehensive experimental analysis of existing mainstream VLMs, including fully supervised learning and in-context learning settings. We have found that models trained on FineMatch demonstrate enhanced proficiency in detecting fine-grained text and image mismatches. Moreover, models (e.g., GPT-4V, Gemini Pro Vision) with strong abilities to perform multimodal in-context learning are not as skilled at fine-grained compositional image and text matching analysis. With FineMatch, we are able to build a system for text-to-image generation hallucination detection and correction.
IMPRINT: Generative Object Compositing by Learning Identity-Preserving Representation
Mar 15, 2024



Generative object compositing emerges as a promising new avenue for compositional image editing. However, the requirement of object identity preservation poses a significant challenge, limiting practical usage of most existing methods. In response, this paper introduces IMPRINT, a novel diffusion-based generative model trained with a two-stage learning framework that decouples learning of identity preservation from that of compositing. The first stage is targeted for context-agnostic, identity-preserving pretraining of the object encoder, enabling the encoder to learn an embedding that is both view-invariant and conducive to enhanced detail preservation. The subsequent stage leverages this representation to learn seamless harmonization of the object composited to the background. In addition, IMPRINT incorporates a shape-guidance mechanism offering user-directed control over the compositing process. Extensive experiments demonstrate that IMPRINT significantly outperforms existing methods and various baselines on identity preservation and composition quality.
Latent Feature-Guided Diffusion Models for Shadow Removal
Dec 04, 2023



Recovering textures under shadows has remained a challenging problem due to the difficulty of inferring shadow-free scenes from shadow images. In this paper, we propose the use of diffusion models as they offer a promising approach to gradually refine the details of shadow regions during the diffusion process. Our method improves this process by conditioning on a learned latent feature space that inherits the characteristics of shadow-free images, thus avoiding the limitation of conventional methods that condition on degraded images only. Additionally, we propose to alleviate potential local optima during training by fusing noise features with the diffusion network. We demonstrate the effectiveness of our approach which outperforms the previous best method by 13% in terms of RMSE on the AISTD dataset. Further, we explore instance-level shadow removal, where our model outperforms the previous best method by 82% in terms of RMSE on the DESOBA dataset.
SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data
Aug 24, 2023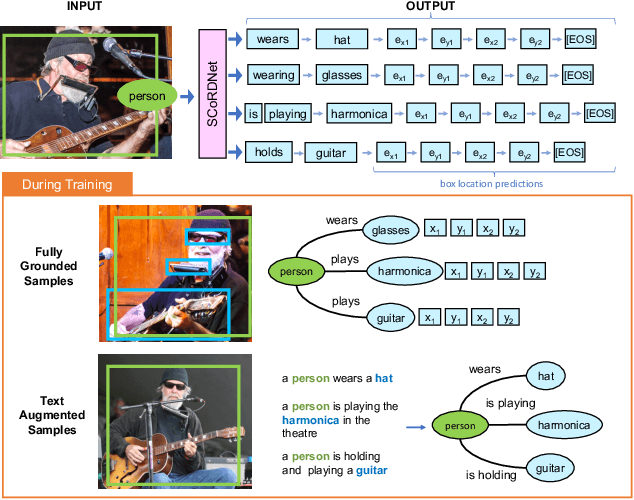
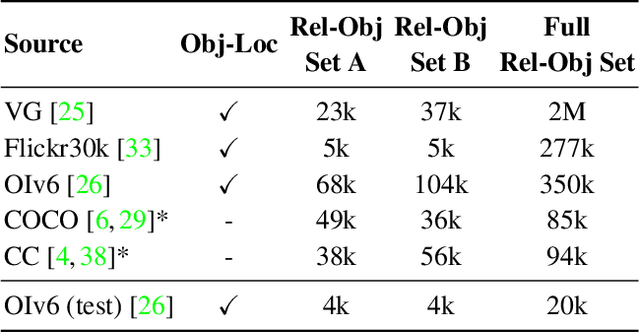
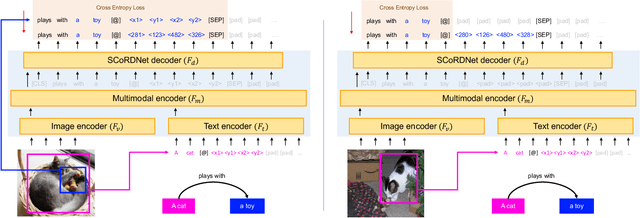
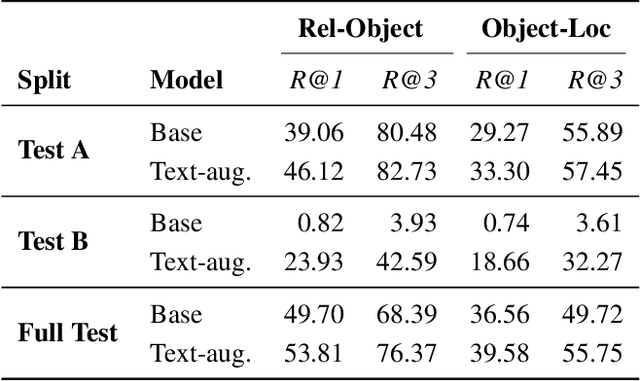
We propose Subject-Conditional Relation Detection SCoRD, where conditioned on an input subject, the goal is to predict all its relations to other objects in a scene along with their locations. Based on the Open Images dataset, we propose a challenging OIv6-SCoRD benchmark such that the training and testing splits have a distribution shift in terms of the occurrence statistics of $\langle$subject, relation, object$\rangle$ triplets. To solve this problem, we propose an auto-regressive model that given a subject, it predicts its relations, objects, and object locations by casting this output as a sequence of tokens. First, we show that previous scene-graph prediction methods fail to produce as exhaustive an enumeration of relation-object pairs when conditioned on a subject on this benchmark. Particularly, we obtain a recall@3 of 83.8% for our relation-object predictions compared to the 49.75% obtained by a recent scene graph detector. Then, we show improved generalization on both relation-object and object-box predictions by leveraging during training relation-object pairs obtained automatically from textual captions and for which no object-box annotations are available. Particularly, for $\langle$subject, relation, object$\rangle$ triplets for which no object locations are available during training, we are able to obtain a recall@3 of 42.59% for relation-object pairs and 32.27% for their box locations.