 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffGraph: An Automated Agent-driven Model Merging Framework for In-the-Wild Text-to-Image Generation
Mar 20, 2026The rapid growth of the text-to-image (T2I) community has fostered a thriving online ecosystem of expert models, which are variants of pretrained diffusion models specialized for diverse generative abilities. Yet, existing model merging methods remain limited in fully leveraging abundant online expert resources and still struggle to meet diverse in-the-wild user needs. We present DiffGraph, a novel agent-driven graph-based model merging framework, which automatically harnesses online experts and flexibly merges them for diverse user needs. Our DiffGraph constructs a scalable graph and organizes ever-expanding online experts within it through node registration and calibration. Then, DiffGraph dynamically activates specific subgraphs based on user needs, enabling flexible combinations of different experts to achieve user-desired generation. Extensive experiments show the efficacy of our method.
ViT-AdaLA: Adapting Vision Transformers with Linear Attention
Mar 17, 2026Vision Transformers (ViTs) based vision foundation models (VFMs) have achieved remarkable performance across diverse vision tasks, but suffer from quadratic complexity that limits scalability to long sequences. Existing linear attention approaches for ViTs are typically trained from scratch, requiring substantial computational resources, while linearization-based methods developed for large language model decoders do not transfer well to ViTs. To address these challenges, we propose ViT-AdaLA, a novel framework for effectively adapting and transferring prior knowledge from VFMs to linear attention ViTs. ViT-AdaLA consists of three stages: attention alignment, feature alignment, and supervised fine-tuning. In the attention alignment stage, we align vanilla linear attention with the original softmax-based attention in each block to approximate the behavior of softmax attention. However, residual approximation errors inevitably accumulate across layers. We mitigate this by fine-tuning the linearized ViT to align its final-layer features with a frozen softmax VFM teacher. Finally, the adapted prior knowledge is transferred to downstream tasks through supervised fine-tuning. Extensive experiments on classification and segmentation tasks demonstrate the effectiveness and generality of ViT-AdaLA over various state-of-the-art linear attention counterpart.
SNCE: Geometry-Aware Supervision for Scalable Discrete Image Generation
Mar 16, 2026Recent advancements in discrete image generation showed that scaling the VQ codebook size significantly improves reconstruction fidelity. However, training generative models with a large VQ codebook remains challenging, typically requiring larger model size and a longer training schedule. In this work, we propose Stochastic Neighbor Cross Entropy Minimization (SNCE), a novel training objective designed to address the optimization challenges of large-codebook discrete image generators. Instead of supervising the model with a hard one-hot target, SNCE constructs a soft categorical distribution over a set of neighboring tokens. The probability assigned to each token is proportional to the proximity between its code embedding and the ground-truth image embedding, encouraging the model to capture semantically meaningful geometric structure in the quantized embedding space. We conduct extensive experiments across class-conditional ImageNet-256 generation, large-scale text-to-image synthesis, and image editing tasks. Results show that SNCE significantly improves convergence speed and overall generation quality compared to standard cross-entropy objectives.
LaViDa-R1: Advancing Reasoning for Unified Multimodal Diffusion Language Models
Feb 15, 2026Diffusion language models (dLLMs) recently emerged as a promising alternative to auto-regressive LLMs. The latest works further extended it to multimodal understanding and generation tasks. In this work, we propose LaViDa-R1, a multimodal, general-purpose reasoning dLLM. Unlike existing works that build reasoning dLLMs through task-specific reinforcement learning, LaViDa-R1 incorporates diverse multimodal understanding and generation tasks in a unified manner. In particular, LaViDa-R1 is built with a novel unified post-training framework that seamlessly integrates supervised finetuning (SFT) and multi-task reinforcement learning (RL). It employs several novel training techniques, including answer-forcing, tree search, and complementary likelihood estimation, to enhance effectiveness and scalability. Extensive experiments demonstrate LaViDa-R1's strong performance on a wide range of multimodal tasks, including visual math reasoning, reason-intensive grounding, and image editing.
Sparse-LaViDa: Sparse Multimodal Discrete Diffusion Language Models
Dec 16, 2025Masked Discrete Diffusion Models (MDMs) have achieved strong performance across a wide range of multimodal tasks, including image understanding, generation, and editing. However, their inference speed remains suboptimal due to the need to repeatedly process redundant masked tokens at every sampling step. In this work, we propose Sparse-LaViDa, a novel modeling framework that dynamically truncates unnecessary masked tokens at each inference step to accelerate MDM sampling. To preserve generation quality, we introduce specialized register tokens that serve as compact representations for the truncated tokens. Furthermore, to ensure consistency between training and inference, we design a specialized attention mask that faithfully matches the truncated sampling procedure during training. Built upon the state-of-the-art unified MDM LaViDa-O, Sparse-LaViDa achieves up to a 2x speedup across diverse tasks including text-to-image generation, image editing, and mathematical reasoning, while maintaining generation quality.
VGent: Visual Grounding via Modular Design for Disentangling Reasoning and Prediction
Dec 11, 2025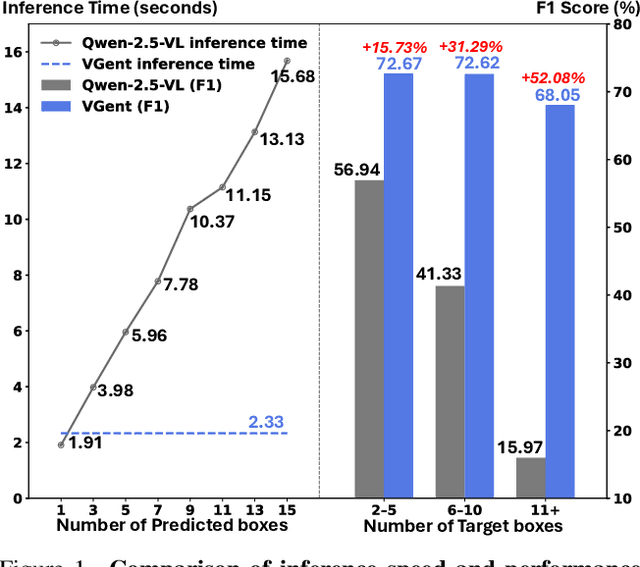
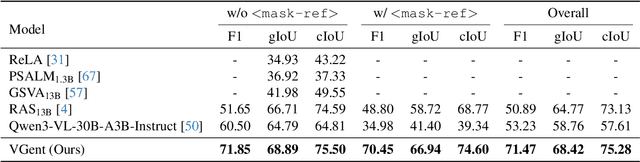
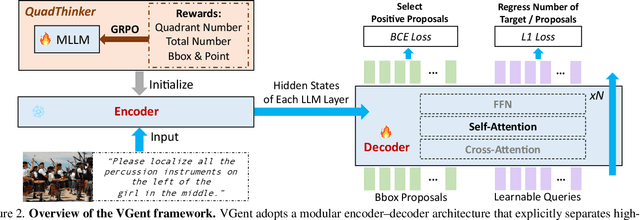
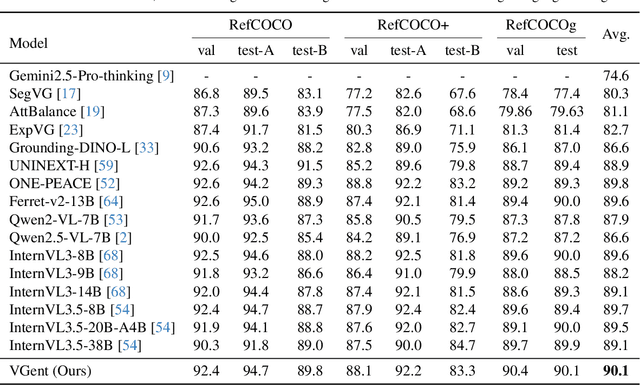
Current visual grounding models are either based on a Multimodal Large Language Model (MLLM) that performs auto-regressive decoding, which is slow and risks hallucinations, or on re-aligning an LLM with vision features to learn new special or object tokens for grounding, which may undermine the LLM's pretrained reasoning ability. In contrast, we propose VGent, a modular encoder-decoder architecture that explicitly disentangles high-level reasoning and low-level bounding box prediction. Specifically, a frozen MLLM serves as the encoder to provide untouched powerful reasoning capabilities, while a decoder takes high-quality boxes proposed by detectors as queries and selects target box(es) via cross-attending on encoder's hidden states. This design fully leverages advances in both object detection and MLLM, avoids the pitfalls of auto-regressive decoding, and enables fast inference. Moreover, it supports modular upgrades of both the encoder and decoder to benefit the whole system: we introduce (i) QuadThinker, an RL-based training paradigm for enhancing multi-target reasoning ability of the encoder; (ii) mask-aware label for resolving detection-segmentation ambiguity; and (iii) global target recognition to improve the recognition of all the targets which benefits the selection among augmented proposals. Experiments on multi-target visual grounding benchmarks show that VGent achieves a new state-of-the-art with +20.6% F1 improvement over prior methods, and further boosts gIoU by +8.2% and cIoU by +5.8% under visual reference challenges, while maintaining constant, fast inference latency.
OIDA-QA: A Multimodal Benchmark for Analyzing the Opioid Industry Documents Archive
Nov 14, 2025The opioid crisis represents a significant moment in public health that reveals systemic shortcomings across regulatory systems, healthcare practices, corporate governance, and public policy. Analyzing how these interconnected systems simultaneously failed to protect public health requires innovative analytic approaches for exploring the vast amounts of data and documents disclosed in the UCSF-JHU Opioid Industry Documents Archive (OIDA). The complexity, multimodal nature, and specialized characteristics of these healthcare-related legal and corporate documents necessitate more advanced methods and models tailored to specific data types and detailed annotations, ensuring the precision and professionalism in the analysis. In this paper, we tackle this challenge by organizing the original dataset according to document attributes and constructing a benchmark with 400k training documents and 10k for testing. From each document, we extract rich multimodal information-including textual content, visual elements, and layout structures-to capture a comprehensive range of features. Using multiple AI models, we then generate a large-scale dataset comprising 360k training QA pairs and 10k testing QA pairs. Building on this foundation, we develop domain-specific multimodal Large Language Models (LLMs) and explore the impact of multimodal inputs on task performance. To further enhance response accuracy, we incorporate historical QA pairs as contextual grounding for answering current queries. Additionally, we incorporate page references within the answers and introduce an importance-based page classifier, further improving the precision and relevance of the information provided. Preliminary results indicate the improvements with our AI assistant in document information extraction and question-answering tasks. The dataset is available at: https://huggingface.co/datasets/opioidarchive/oida-qa
Image Tokenizer Needs Post-Training
Sep 15, 2025Recent image generative models typically capture the image distribution in a pre-constructed latent space, relying on a frozen image tokenizer. However, there exists a significant discrepancy between the reconstruction and generation distribution, where current tokenizers only prioritize the reconstruction task that happens before generative training without considering the generation errors during sampling. In this paper, we comprehensively analyze the reason for this discrepancy in a discrete latent space, and, from which, we propose a novel tokenizer training scheme including both main-training and post-training, focusing on improving latent space construction and decoding respectively. During the main training, a latent perturbation strategy is proposed to simulate sampling noises, \ie, the unexpected tokens generated in generative inference. Specifically, we propose a plug-and-play tokenizer training scheme, which significantly enhances the robustness of tokenizer, thus boosting the generation quality and convergence speed, and a novel tokenizer evaluation metric, \ie, pFID, which successfully correlates the tokenizer performance to generation quality. During post-training, we further optimize the tokenizer decoder regarding a well-trained generative model to mitigate the distribution difference between generated and reconstructed tokens. With a $\sim$400M generator, a discrete tokenizer trained with our proposed main training achieves a notable 1.60 gFID and further obtains 1.36 gFID with the additional post-training. Further experiments are conducted to broadly validate the effectiveness of our post-training strategy on off-the-shelf discrete and continuous tokenizers, coupled with autoregressive and diffusion-based generators.
Refer to Anything with Vision-Language Prompts
Jun 05, 2025Recent image segmentation models have advanced to segment images into high-quality masks for visual entities, and yet they cannot provide comprehensive semantic understanding for complex queries based on both language and vision. This limitation reduces their effectiveness in applications that require user-friendly interactions driven by vision-language prompts. To bridge this gap, we introduce a novel task of omnimodal referring expression segmentation (ORES). In this task, a model produces a group of masks based on arbitrary prompts specified by text only or text plus reference visual entities. To address this new challenge, we propose a novel framework to "Refer to Any Segmentation Mask Group" (RAS), which augments segmentation models with complex multimodal interactions and comprehension via a mask-centric large multimodal model. For training and benchmarking ORES models, we create datasets MaskGroups-2M and MaskGroups-HQ to include diverse mask groups specified by text and reference entities. Through extensive evaluation, we demonstrate superior performance of RAS on our new ORES task, as well as classic referring expression segmentation (RES) and generalized referring expression segmentation (GRES) tasks. Project page: https://Ref2Any.github.io.
LaViDa: A Large Diffusion Language Model for Multimodal Understanding
May 22, 2025Modern Vision-Language Models (VLMs) can solve a wide range of tasks requiring visual reasoning. In real-world scenarios, desirable properties for VLMs include fast inference and controllable generation (e.g., constraining outputs to adhere to a desired format). However, existing autoregressive (AR) VLMs like LLaVA struggle in these aspects. Discrete diffusion models (DMs) offer a promising alternative, enabling parallel decoding for faster inference and bidirectional context for controllable generation through text-infilling. While effective in language-only settings, DMs' potential for multimodal tasks is underexplored. We introduce LaViDa, a family of VLMs built on DMs. We build LaViDa by equipping DMs with a vision encoder and jointly fine-tune the combined parts for multimodal instruction following. To address challenges encountered, LaViDa incorporates novel techniques such as complementary masking for effective training, prefix KV cache for efficient inference, and timestep shifting for high-quality sampling. Experiments show that LaViDa achieves competitive or superior performance to AR VLMs on multi-modal benchmarks such as MMMU, while offering unique advantages of DMs, including flexible speed-quality tradeoff, controllability, and bidirectional reasoning. On COCO captioning, LaViDa surpasses Open-LLaVa-Next-8B by +4.1 CIDEr with 1.92x speedup. On bidirectional tasks, it achieves +59% improvement on Constrained Poem Completion. These results demonstrate LaViDa as a strong alternative to AR VLMs. Code and models will be released in the camera-ready version.