 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuidance Contrastive Token Credit Assignment for Discrete Policy Optimization
May 28, 2026Group-advantage-based reinforcement learning methods, such as GRPO and DAPO, have demonstrated strong performance across diverse domains, including mathematical reasoning and text-to-image generation. However, their reliance on sample-level rewards introduces a key limitation as uniform credit assignment across all tokens fails to capture fine-grained, token-level contributions. To address this issue, we propose Guidance Contrastive Policy Optimization (GCPO), a novel algorithm that enables per-token credit assignment by contrasting model predictions under positive and negative prompts. Rather than uniformly broadcasting sample-level advantages, GCPO assigns token-level advantages proportional to the difference between these contrastive predictions, allowing more precise and informative learning signals. Empirically, we find that GCPO emphasizes semantically relevant regions such as visual areas aligned with textual prompts in text-to-image generation, and critical keywords within reasoning traces for chain-of-thought tasks. Through extensive experiments, GCPO consistently outperforms GRPO and DAPO baselines on both text-to-image generation and chain-of-thought reasoning benchmarks, demonstrating its effectiveness as a general and scalable optimization strategy for discrete policy learning.
MobileWorldBench: Towards Semantic World Modeling For Mobile Agents
Dec 16, 2025World models have shown great utility in improving the task performance of embodied agents. While prior work largely focuses on pixel-space world models, these approaches face practical limitations in GUI settings, where predicting complex visual elements in future states is often difficult. In this work, we explore an alternative formulation of world modeling for GUI agents, where state transitions are described in natural language rather than predicting raw pixels. First, we introduce MobileWorldBench, a benchmark that evaluates the ability of vision-language models (VLMs) to function as world models for mobile GUI agents. Second, we release MobileWorld, a large-scale dataset consisting of 1.4M samples, that significantly improves the world modeling capabilities of VLMs. Finally, we propose a novel framework that integrates VLM world models into the planning framework of mobile agents, demonstrating that semantic world models can directly benefit mobile agents by improving task success rates. The code and dataset is available at https://github.com/jacklishufan/MobileWorld
LaViDa: A Large Diffusion Language Model for Multimodal Understanding
May 22, 2025Modern Vision-Language Models (VLMs) can solve a wide range of tasks requiring visual reasoning. In real-world scenarios, desirable properties for VLMs include fast inference and controllable generation (e.g., constraining outputs to adhere to a desired format). However, existing autoregressive (AR) VLMs like LLaVA struggle in these aspects. Discrete diffusion models (DMs) offer a promising alternative, enabling parallel decoding for faster inference and bidirectional context for controllable generation through text-infilling. While effective in language-only settings, DMs' potential for multimodal tasks is underexplored. We introduce LaViDa, a family of VLMs built on DMs. We build LaViDa by equipping DMs with a vision encoder and jointly fine-tune the combined parts for multimodal instruction following. To address challenges encountered, LaViDa incorporates novel techniques such as complementary masking for effective training, prefix KV cache for efficient inference, and timestep shifting for high-quality sampling. Experiments show that LaViDa achieves competitive or superior performance to AR VLMs on multi-modal benchmarks such as MMMU, while offering unique advantages of DMs, including flexible speed-quality tradeoff, controllability, and bidirectional reasoning. On COCO captioning, LaViDa surpasses Open-LLaVa-Next-8B by +4.1 CIDEr with 1.92x speedup. On bidirectional tasks, it achieves +59% improvement on Constrained Poem Completion. These results demonstrate LaViDa as a strong alternative to AR VLMs. Code and models will be released in the camera-ready version.
VideoMultiAgents: A Multi-Agent Framework for Video Question Answering
Apr 30, 2025Video Question Answering (VQA) inherently relies on multimodal reasoning, integrating visual, temporal, and linguistic cues to achieve a deeper understanding of video content. However, many existing methods rely on feeding frame-level captions into a single model, making it difficult to adequately capture temporal and interactive contexts. To address this limitation, we introduce VideoMultiAgents, a framework that integrates specialized agents for vision, scene graph analysis, and text processing. It enhances video understanding leveraging complementary multimodal reasoning from independently operating agents. Our approach is also supplemented with a question-guided caption generation, which produces captions that highlight objects, actions, and temporal transitions directly relevant to a given query, thus improving the answer accuracy. Experimental results demonstrate that our method achieves state-of-the-art performance on Intent-QA (79.0%, +6.2% over previous SOTA), EgoSchema subset (75.4%, +3.4%), and NExT-QA (79.6%, +0.4%). The source code is available at https://github.com/PanasonicConnect/VideoMultiAgents.
Reflect-DiT: Inference-Time Scaling for Text-to-Image Diffusion Transformers via In-Context Reflection
Mar 15, 2025The predominant approach to advancing text-to-image generation has been training-time scaling, where larger models are trained on more data using greater computational resources. While effective, this approach is computationally expensive, leading to growing interest in inference-time scaling to improve performance. Currently, inference-time scaling for text-to-image diffusion models is largely limited to best-of-N sampling, where multiple images are generated per prompt and a selection model chooses the best output. Inspired by the recent success of reasoning models like DeepSeek-R1 in the language domain, we introduce an alternative to naive best-of-N sampling by equipping text-to-image Diffusion Transformers with in-context reflection capabilities. We propose Reflect-DiT, a method that enables Diffusion Transformers to refine their generations using in-context examples of previously generated images alongside textual feedback describing necessary improvements. Instead of passively relying on random sampling and hoping for a better result in a future generation, Reflect-DiT explicitly tailors its generations to address specific aspects requiring enhancement. Experimental results demonstrate that Reflect-DiT improves performance on the GenEval benchmark (+0.19) using SANA-1.0-1.6B as a base model. Additionally, it achieves a new state-of-the-art score of 0.81 on GenEval while generating only 20 samples per prompt, surpassing the previous best score of 0.80, which was obtained using a significantly larger model (SANA-1.5-4.8B) with 2048 samples under the best-of-N approach.
OmniFlow: Any-to-Any Generation with Multi-Modal Rectified Flows
Dec 02, 2024



We introduce OmniFlow, a novel generative model designed for any-to-any generation tasks such as text-to-image, text-to-audio, and audio-to-image synthesis. OmniFlow advances the rectified flow (RF) framework used in text-to-image models to handle the joint distribution of multiple modalities. It outperforms previous any-to-any models on a wide range of tasks, such as text-to-image and text-to-audio synthesis. Our work offers three key contributions: First, we extend RF to a multi-modal setting and introduce a novel guidance mechanism, enabling users to flexibly control the alignment between different modalities in the generated outputs. Second, we propose a novel architecture that extends the text-to-image MMDiT architecture of Stable Diffusion 3 and enables audio and text generation. The extended modules can be efficiently pretrained individually and merged with the vanilla text-to-image MMDiT for fine-tuning. Lastly, we conduct a comprehensive study on the design choices of rectified flow transformers for large-scale audio and text generation, providing valuable insights into optimizing performance across diverse modalities. The Code will be available at https://github.com/jacklishufan/OmniFlows.
SegLLM: Multi-round Reasoning Segmentation
Oct 24, 2024



We present SegLLM, a novel multi-round interactive reasoning segmentation model that enhances LLM-based segmentation by exploiting conversational memory of both visual and textual outputs. By leveraging a mask-aware multimodal LLM, SegLLM re-integrates previous segmentation results into its input stream, enabling it to reason about complex user intentions and segment objects in relation to previously identified entities, including positional, interactional, and hierarchical relationships, across multiple interactions. This capability allows SegLLM to respond to visual and text queries in a chat-like manner. Evaluated on the newly curated MRSeg benchmark, SegLLM outperforms existing methods in multi-round interactive reasoning segmentation by over 20%. Additionally, we observed that training on multi-round reasoning segmentation data enhances performance on standard single-round referring segmentation and localization tasks, resulting in a 5.5% increase in cIoU for referring expression segmentation and a 4.5% improvement in Acc@0.5 for referring expression localization.
Few-Shot Classification of Interactive Activities of Daily Living (InteractADL)
Jun 03, 2024

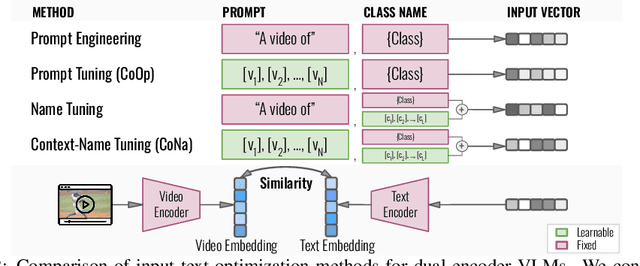

Understanding Activities of Daily Living (ADLs) is a crucial step for different applications including assistive robots, smart homes, and healthcare. However, to date, few benchmarks and methods have focused on complex ADLs, especially those involving multi-person interactions in home environments. In this paper, we propose a new dataset and benchmark, InteractADL, for understanding complex ADLs that involve interaction between humans (and objects). Furthermore, complex ADLs occurring in home environments comprise a challenging long-tailed distribution due to the rarity of multi-person interactions, and pose fine-grained visual recognition tasks due to the presence of semantically and visually similar classes. To address these issues, we propose a novel method for fine-grained few-shot video classification called Name Tuning that enables greater semantic separability by learning optimal class name vectors. We show that Name Tuning can be combined with existing prompt tuning strategies to learn the entire input text (rather than only learning the prompt or class names) and demonstrate improved performance for few-shot classification on InteractADL and 4 other fine-grained visual classification benchmarks. For transparency and reproducibility, we release our code at https://github.com/zanedurante/vlm_benchmark.
Aligning Diffusion Models by Optimizing Human Utility
Apr 06, 2024



We present Diffusion-KTO, a novel approach for aligning text-to-image diffusion models by formulating the alignment objective as the maximization of expected human utility. Since this objective applies to each generation independently, Diffusion-KTO does not require collecting costly pairwise preference data nor training a complex reward model. Instead, our objective requires simple per-image binary feedback signals, e.g. likes or dislikes, which are abundantly available. After fine-tuning using Diffusion-KTO, text-to-image diffusion models exhibit superior performance compared to existing techniques, including supervised fine-tuning and Diffusion-DPO, both in terms of human judgment and automatic evaluation metrics such as PickScore and ImageReward. Overall, Diffusion-KTO unlocks the potential of leveraging readily available per-image binary signals and broadens the applicability of aligning text-to-image diffusion models with human preferences.
Wild2Avatar: Rendering Humans Behind Occlusions
Dec 31, 2023Rendering the visual appearance of moving humans from occluded monocular videos is a challenging task. Most existing research renders 3D humans under ideal conditions, requiring a clear and unobstructed scene. Those methods cannot be used to render humans in real-world scenes where obstacles may block the camera's view and lead to partial occlusions. In this work, we present Wild2Avatar, a neural rendering approach catered for occluded in-the-wild monocular videos. We propose occlusion-aware scene parameterization for decoupling the scene into three parts - occlusion, human, and background. Additionally, extensive objective functions are designed to help enforce the decoupling of the human from both the occlusion and the background and to ensure the completeness of the human model. We verify the effectiveness of our approach with experiments on in-the-wild videos.