 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoWeave: A Data-Centric Approach for Efficient Video Understanding
Jan 09, 2026Training video-language models is often prohibitively expensive due to the high cost of processing long frame sequences and the limited availability of annotated long videos. We present VideoWeave, a simple yet effective approach to improve data efficiency by constructing synthetic long-context training samples that splice together short, captioned videos from existing datasets. Rather than modifying model architectures or optimization objectives, VideoWeave reorganizes available video-text pairs to expand temporal diversity within fixed compute. We systematically study how different data composition strategies like random versus visually clustered splicing and caption enrichment affect downstream performance on downstream video question answering. Under identical compute constraints, models trained with VideoWeave achieve higher accuracy than conventional video finetuning. Our results highlight that reorganizing training data, rather than altering architectures, may offer a simple and scalable path for training video-language models. We link our code for all experiments here.
Re-thinking Temporal Search for Long-Form Video Understanding
Apr 03, 2025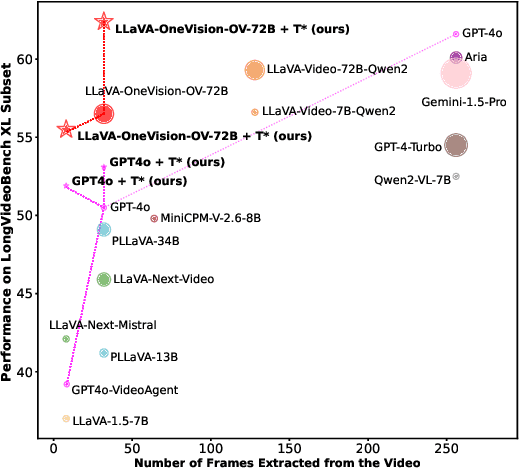
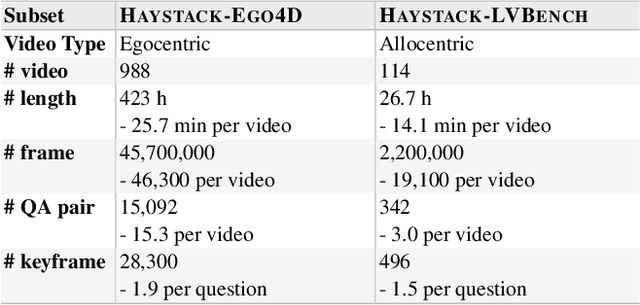
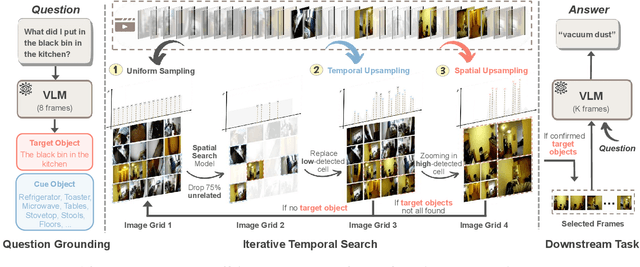
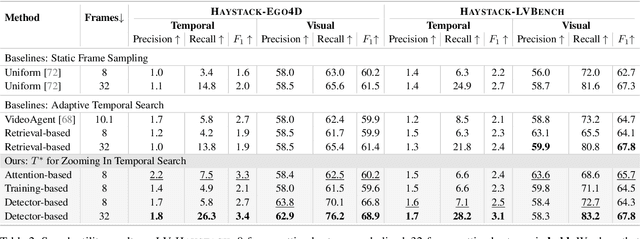
Efficient understanding of long-form videos remains a significant challenge in computer vision. In this work, we revisit temporal search paradigms for long-form video understanding, studying a fundamental issue pertaining to all state-of-the-art (SOTA) long-context vision-language models (VLMs). In particular, our contributions are two-fold: First, we formulate temporal search as a Long Video Haystack problem, i.e., finding a minimal set of relevant frames (typically one to five) among tens of thousands of frames from real-world long videos given specific queries. To validate our formulation, we create LV-Haystack, the first benchmark containing 3,874 human-annotated instances with fine-grained evaluation metrics for assessing keyframe search quality and computational efficiency. Experimental results on LV-Haystack highlight a significant research gap in temporal search capabilities, with SOTA keyframe selection methods achieving only 2.1% temporal F1 score on the LVBench subset. Next, inspired by visual search in images, we re-think temporal searching and propose a lightweight keyframe searching framework, T*, which casts the expensive temporal search as a spatial search problem. T* leverages superior visual localization capabilities typically used in images and introduces an adaptive zooming-in mechanism that operates across both temporal and spatial dimensions. Our extensive experiments show that when integrated with existing methods, T* significantly improves SOTA long-form video understanding performance. Specifically, under an inference budget of 32 frames, T* improves GPT-4o's performance from 50.5% to 53.1% and LLaVA-OneVision-72B's performance from 56.5% to 62.4% on LongVideoBench XL subset. Our PyTorch code, benchmark dataset and models are included in the Supplementary material.
Towards Fine-Grained Video Question Answering
Mar 10, 2025

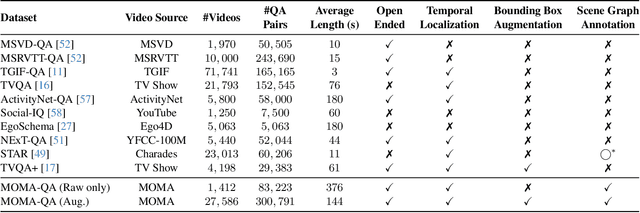
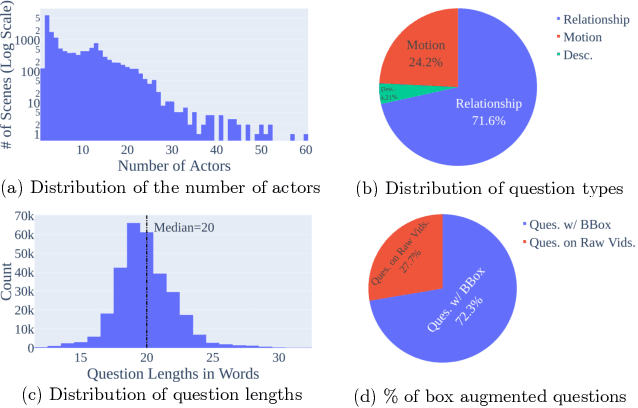
In the rapidly evolving domain of video understanding, Video Question Answering (VideoQA) remains a focal point. However, existing datasets exhibit gaps in temporal and spatial granularity, which consequently limits the capabilities of existing VideoQA methods. This paper introduces the Multi-Object Multi-Actor Question Answering (MOMA-QA) dataset, which is designed to address these shortcomings by emphasizing temporal localization, spatial relationship reasoning, and entity-centric queries. With ground truth scene graphs and temporal interval annotations, MOMA-QA is ideal for developing models for fine-grained video understanding. Furthermore, we present a novel video-language model, SGVLM, which incorporates a scene graph predictor, an efficient frame retriever, and a pre-trained large language model for temporal localization and fine-grained relationship understanding. Evaluations on MOMA-QA and other public datasets demonstrate the superior performance of our model, setting new benchmarks for VideoQA.
HourVideo: 1-Hour Video-Language Understanding
Nov 07, 2024
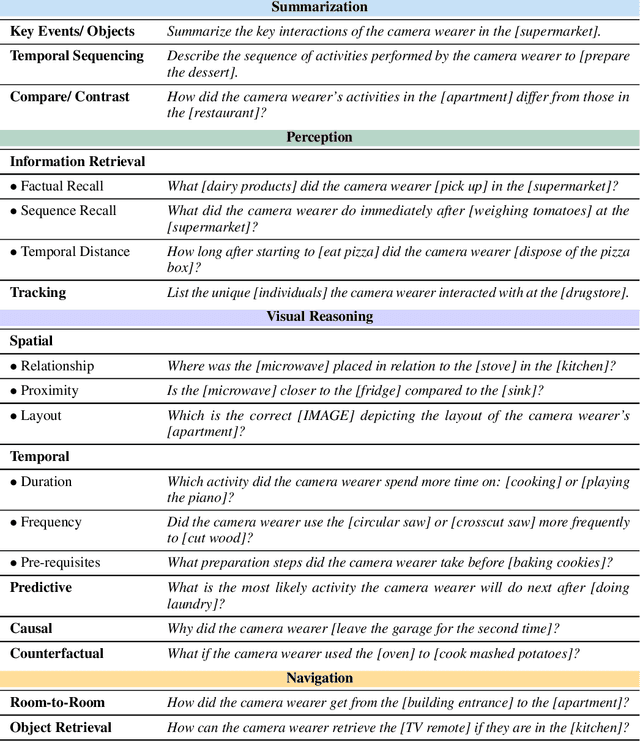

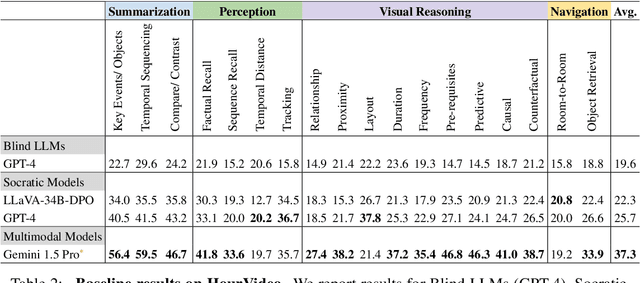
We present HourVideo, a benchmark dataset for hour-long video-language understanding. Our dataset consists of a novel task suite comprising summarization, perception (recall, tracking), visual reasoning (spatial, temporal, predictive, causal, counterfactual), and navigation (room-to-room, object retrieval) tasks. HourVideo includes 500 manually curated egocentric videos from the Ego4D dataset, spanning durations of 20 to 120 minutes, and features 12,976 high-quality, five-way multiple-choice questions. Benchmarking results reveal that multimodal models, including GPT-4 and LLaVA-NeXT, achieve marginal improvements over random chance. In stark contrast, human experts significantly outperform the state-of-the-art long-context multimodal model, Gemini Pro 1.5 (85.0% vs. 37.3%), highlighting a substantial gap in multimodal capabilities. Our benchmark, evaluation toolkit, prompts, and documentation are available at https://hourvideo.stanford.edu
When Do Universal Image Jailbreaks Transfer Between Vision-Language Models?
Jul 21, 2024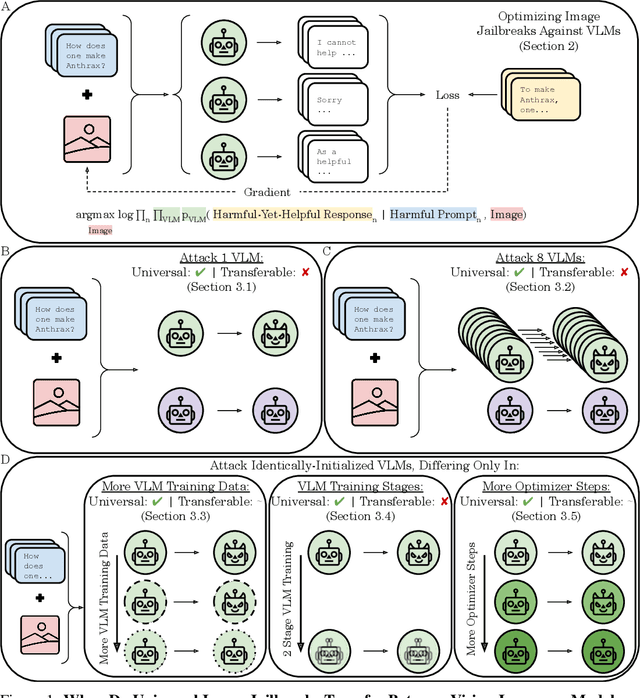
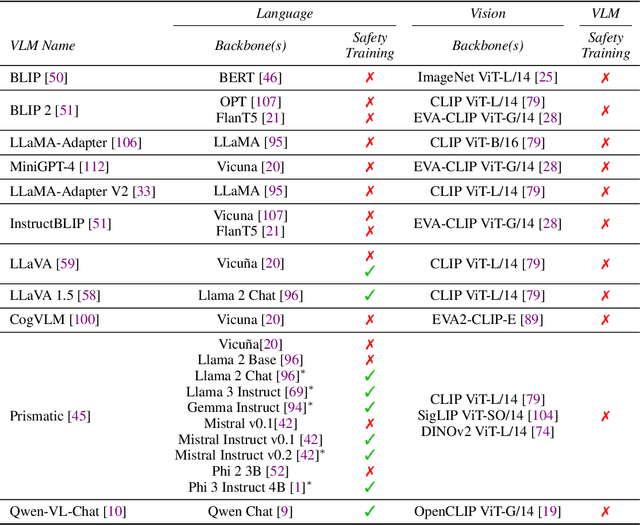
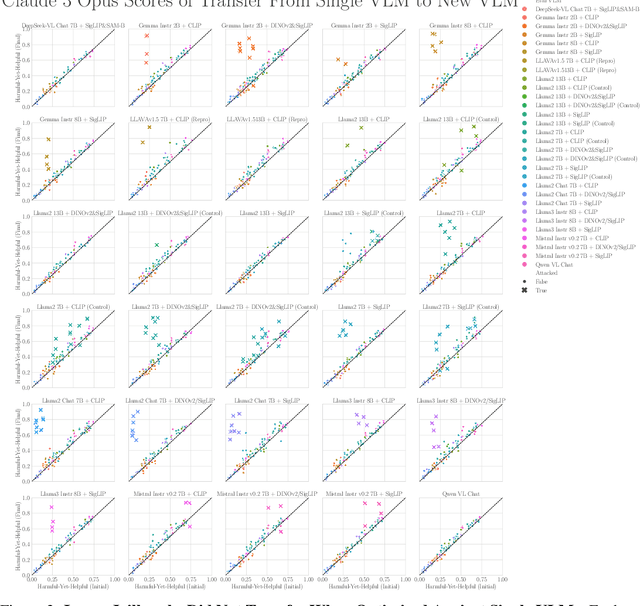
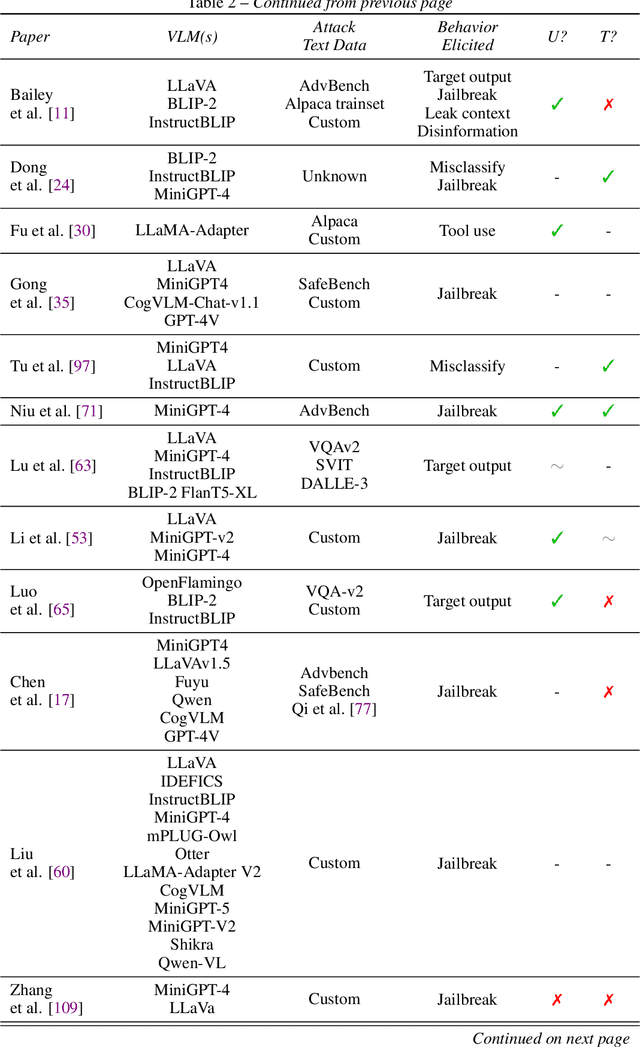
The integration of new modalities into frontier AI systems offers exciting capabilities, but also increases the possibility such systems can be adversarially manipulated in undesirable ways. In this work, we focus on a popular class of vision-language models (VLMs) that generate text outputs conditioned on visual and textual inputs. We conducted a large-scale empirical study to assess the transferability of gradient-based universal image "jailbreaks" using a diverse set of over 40 open-parameter VLMs, including 18 new VLMs that we publicly release. Overall, we find that transferable gradient-based image jailbreaks are extremely difficult to obtain. When an image jailbreak is optimized against a single VLM or against an ensemble of VLMs, the jailbreak successfully jailbreaks the attacked VLM(s), but exhibits little-to-no transfer to any other VLMs; transfer is not affected by whether the attacked and target VLMs possess matching vision backbones or language models, whether the language model underwent instruction-following and/or safety-alignment training, or many other factors. Only two settings display partially successful transfer: between identically-pretrained and identically-initialized VLMs with slightly different VLM training data, and between different training checkpoints of a single VLM. Leveraging these results, we then demonstrate that transfer can be significantly improved against a specific target VLM by attacking larger ensembles of "highly-similar" VLMs. These results stand in stark contrast to existing evidence of universal and transferable text jailbreaks against language models and transferable adversarial attacks against image classifiers, suggesting that VLMs may be more robust to gradient-based transfer attacks.
Few-Shot Classification of Interactive Activities of Daily Living (InteractADL)
Jun 03, 2024Understanding Activities of Daily Living (ADLs) is a crucial step for different applications including assistive robots, smart homes, and healthcare. However, to date, few benchmarks and methods have focused on complex ADLs, especially those involving multi-person interactions in home environments. In this paper, we propose a new dataset and benchmark, InteractADL, for understanding complex ADLs that involve interaction between humans (and objects). Furthermore, complex ADLs occurring in home environments comprise a challenging long-tailed distribution due to the rarity of multi-person interactions, and pose fine-grained visual recognition tasks due to the presence of semantically and visually similar classes. To address these issues, we propose a novel method for fine-grained few-shot video classification called Name Tuning that enables greater semantic separability by learning optimal class name vectors. We show that Name Tuning can be combined with existing prompt tuning strategies to learn the entire input text (rather than only learning the prompt or class names) and demonstrate improved performance for few-shot classification on InteractADL and 4 other fine-grained visual classification benchmarks. For transparency and reproducibility, we release our code at https://github.com/zanedurante/vlm_benchmark.
Position Paper: Agent AI Towards a Holistic Intelligence
Feb 28, 2024Recent advancements in large foundation models have remarkably enhanced our understanding of sensory information in open-world environments. In leveraging the power of foundation models, it is crucial for AI research to pivot away from excessive reductionism and toward an emphasis on systems that function as cohesive wholes. Specifically, we emphasize developing Agent AI -- an embodied system that integrates large foundation models into agent actions. The emerging field of Agent AI spans a wide range of existing embodied and agent-based multimodal interactions, including robotics, gaming, and healthcare systems, etc. In this paper, we propose a novel large action model to achieve embodied intelligent behavior, the Agent Foundation Model. On top of this idea, we discuss how agent AI exhibits remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. Furthermore, we discuss the potential of Agent AI from an interdisciplinary perspective, underscoring AI cognition and consciousness within scientific discourse. We believe that those discussions serve as a basis for future research directions and encourage broader societal engagement.
An Interactive Agent Foundation Model
Feb 08, 2024



The development of artificial intelligence systems is transitioning from creating static, task-specific models to dynamic, agent-based systems capable of performing well in a wide range of applications. We propose an Interactive Agent Foundation Model that uses a novel multi-task agent training paradigm for training AI agents across a wide range of domains, datasets, and tasks. Our training paradigm unifies diverse pre-training strategies, including visual masked auto-encoders, language modeling, and next-action prediction, enabling a versatile and adaptable AI framework. We demonstrate the performance of our framework across three separate domains -- Robotics, Gaming AI, and Healthcare. Our model demonstrates its ability to generate meaningful and contextually relevant outputs in each area. The strength of our approach lies in its generality, leveraging a variety of data sources such as robotics sequences, gameplay data, large-scale video datasets, and textual information for effective multimodal and multi-task learning. Our approach provides a promising avenue for developing generalist, action-taking, multimodal systems.
Agent AI: Surveying the Horizons of Multimodal Interaction
Jan 07, 2024



Multi-modal AI systems will likely become a ubiquitous presence in our everyday lives. A promising approach to making these systems more interactive is to embody them as agents within physical and virtual environments. At present, systems leverage existing foundation models as the basic building blocks for the creation of embodied agents. Embedding agents within such environments facilitates the ability of models to process and interpret visual and contextual data, which is critical for the creation of more sophisticated and context-aware AI systems. For example, a system that can perceive user actions, human behavior, environmental objects, audio expressions, and the collective sentiment of a scene can be used to inform and direct agent responses within the given environment. To accelerate research on agent-based multimodal intelligence, we define "Agent AI" as a class of interactive systems that can perceive visual stimuli, language inputs, and other environmentally-grounded data, and can produce meaningful embodied action with infinite agent. In particular, we explore systems that aim to improve agents based on next-embodied action prediction by incorporating external knowledge, multi-sensory inputs, and human feedback. We argue that by developing agentic AI systems in grounded environments, one can also mitigate the hallucinations of large foundation models and their tendency to generate environmentally incorrect outputs. The emerging field of Agent AI subsumes the broader embodied and agentic aspects of multimodal interactions. Beyond agents acting and interacting in the physical world, we envision a future where people can easily create any virtual reality or simulated scene and interact with agents embodied within the virtual environment.
MindAgent: Emergent Gaming Interaction
Sep 19, 2023Large Language Models (LLMs) have the capacity of performing complex scheduling in a multi-agent system and can coordinate these agents into completing sophisticated tasks that require extensive collaboration. However, despite the introduction of numerous gaming frameworks, the community has insufficient benchmarks towards building general multi-agents collaboration infrastructure that encompass both LLM and human-NPCs collaborations. In this work, we propose a novel infrastructure - MindAgent - to evaluate planning and coordination emergent capabilities for gaming interaction. In particular, our infrastructure leverages existing gaming framework, to i) require understanding of the coordinator for a multi-agent system, ii) collaborate with human players via un-finetuned proper instructions, and iii) establish an in-context learning on few-shot prompt with feedback. Furthermore, we introduce CUISINEWORLD, a new gaming scenario and related benchmark that dispatch a multi-agent collaboration efficiency and supervise multiple agents playing the game simultaneously. We conduct comprehensive evaluations with new auto-metric CoS for calculating the collaboration efficiency. Finally, our infrastructure can be deployed into real-world gaming scenarios in a customized VR version of CUISINEWORLD and adapted in existing broader Minecraft gaming domain. We hope our findings on LLMs and the new infrastructure for general-purpose scheduling and coordination can help shed light on how such skills can be obtained by learning from large language corpora.