 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODESteer: A Unified ODE-Based Steering Framework for LLM Alignment
Feb 19, 2026Activation steering, or representation engineering, offers a lightweight approach to align large language models (LLMs) by manipulating their internal activations at inference time. However, current methods suffer from two key limitations: \textit{(i)} the lack of a unified theoretical framework for guiding the design of steering directions, and \textit{(ii)} an over-reliance on \textit{one-step steering} that fail to capture complex patterns of activation distributions. In this work, we propose a unified ordinary differential equations (ODEs)-based \textit{theoretical} framework for activation steering in LLM alignment. We show that conventional activation addition can be interpreted as a first-order approximation to the solution of an ODE. Based on this ODE perspective, identifying a steering direction becomes equivalent to designing a \textit{barrier function} from control theory. Derived from this framework, we introduce ODESteer, a kind of ODE-based steering guided by barrier functions, which shows \textit{empirical} advancement in LLM alignment. ODESteer identifies steering directions by defining the barrier function as the log-density ratio between positive and negative activations, and employs it to construct an ODE for \textit{multi-step and adaptive} steering. Compared to state-of-the-art activation steering methods, ODESteer achieves consistent empirical improvements on diverse LLM alignment benchmarks, a notable $5.7\%$ improvement over TruthfulQA, $2.5\%$ over UltraFeedback, and $2.4\%$ over RealToxicityPrompts. Our work establishes a principled new view of activation steering in LLM alignment by unifying its theoretical foundations via ODEs, and validating it empirically through the proposed ODESteer method.
PROGRESSLM: Towards Progress Reasoning in Vision-Language Models
Jan 21, 2026Estimating task progress requires reasoning over long-horizon dynamics rather than recognizing static visual content. While modern Vision-Language Models (VLMs) excel at describing what is visible, it remains unclear whether they can infer how far a task has progressed from partial observations. To this end, we introduce Progress-Bench, a benchmark for systematically evaluating progress reasoning in VLMs. Beyond benchmarking, we further explore a human-inspired two-stage progress reasoning paradigm through both training-free prompting and training-based approach based on curated dataset ProgressLM-45K. Experiments on 14 VLMs show that most models are not yet ready for task progress estimation, exhibiting sensitivity to demonstration modality and viewpoint changes, as well as poor handling of unanswerable cases. While training-free prompting that enforces structured progress reasoning yields limited and model-dependent gains, the training-based ProgressLM-3B achieves consistent improvements even at a small model scale, despite being trained on a task set fully disjoint from the evaluation tasks. Further analyses reveal characteristic error patterns and clarify when and why progress reasoning succeeds or fails.
Re-thinking Temporal Search for Long-Form Video Understanding
Apr 03, 2025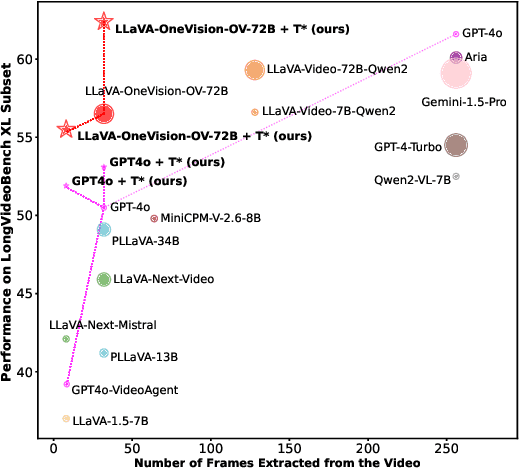
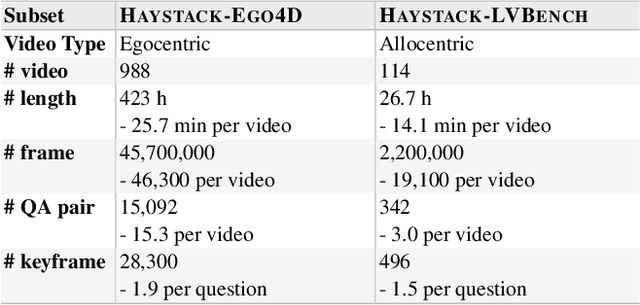
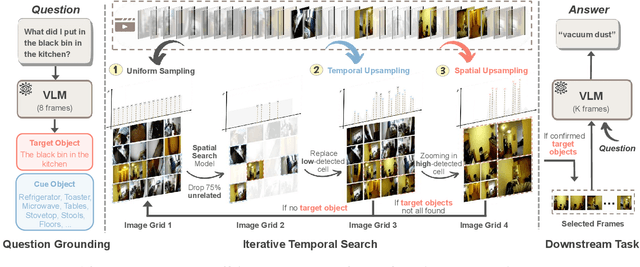
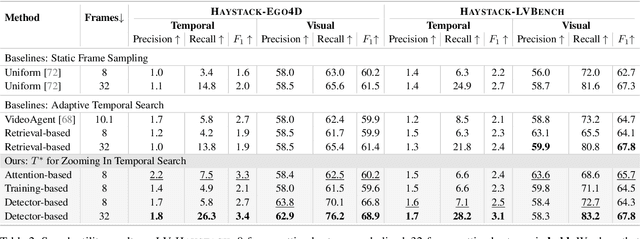
Efficient understanding of long-form videos remains a significant challenge in computer vision. In this work, we revisit temporal search paradigms for long-form video understanding, studying a fundamental issue pertaining to all state-of-the-art (SOTA) long-context vision-language models (VLMs). In particular, our contributions are two-fold: First, we formulate temporal search as a Long Video Haystack problem, i.e., finding a minimal set of relevant frames (typically one to five) among tens of thousands of frames from real-world long videos given specific queries. To validate our formulation, we create LV-Haystack, the first benchmark containing 3,874 human-annotated instances with fine-grained evaluation metrics for assessing keyframe search quality and computational efficiency. Experimental results on LV-Haystack highlight a significant research gap in temporal search capabilities, with SOTA keyframe selection methods achieving only 2.1% temporal F1 score on the LVBench subset. Next, inspired by visual search in images, we re-think temporal searching and propose a lightweight keyframe searching framework, T*, which casts the expensive temporal search as a spatial search problem. T* leverages superior visual localization capabilities typically used in images and introduces an adaptive zooming-in mechanism that operates across both temporal and spatial dimensions. Our extensive experiments show that when integrated with existing methods, T* significantly improves SOTA long-form video understanding performance. Specifically, under an inference budget of 32 frames, T* improves GPT-4o's performance from 50.5% to 53.1% and LLaVA-OneVision-72B's performance from 56.5% to 62.4% on LongVideoBench XL subset. Our PyTorch code, benchmark dataset and models are included in the Supplementary material.
Inpaint4DNeRF: Promptable Spatio-Temporal NeRF Inpainting with Generative Diffusion Models
Dec 30, 2023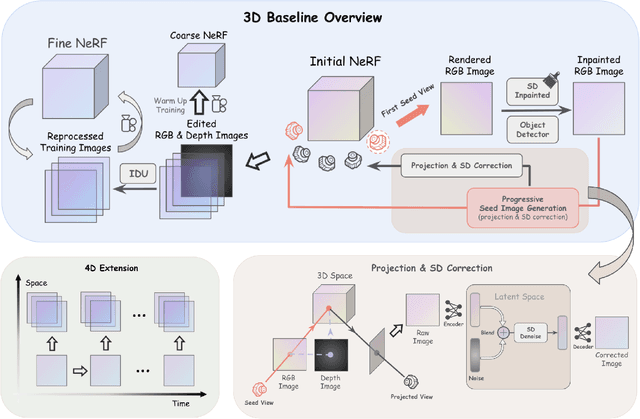



Current Neural Radiance Fields (NeRF) can generate photorealistic novel views. For editing 3D scenes represented by NeRF, with the advent of generative models, this paper proposes Inpaint4DNeRF to capitalize on state-of-the-art stable diffusion models (e.g., ControlNet) for direct generation of the underlying completed background content, regardless of static or dynamic. The key advantages of this generative approach for NeRF inpainting are twofold. First, after rough mask propagation, to complete or fill in previously occluded content, we can individually generate a small subset of completed images with plausible content, called seed images, from which simple 3D geometry proxies can be derived. Second and the remaining problem is thus 3D multiview consistency among all completed images, now guided by the seed images and their 3D proxies. Without other bells and whistles, our generative Inpaint4DNeRF baseline framework is general which can be readily extended to 4D dynamic NeRFs, where temporal consistency can be naturally handled in a similar way as our multiview consistency.
Registering Neural Radiance Fields as 3D Density Images
May 22, 2023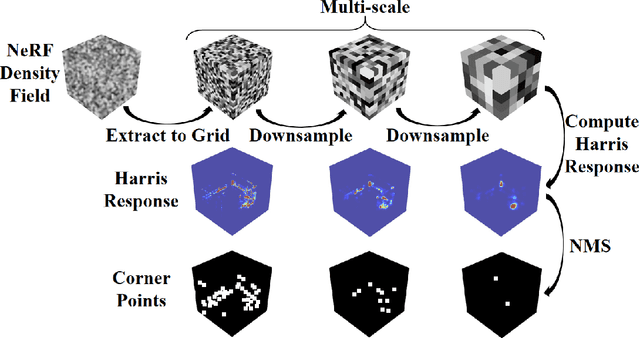
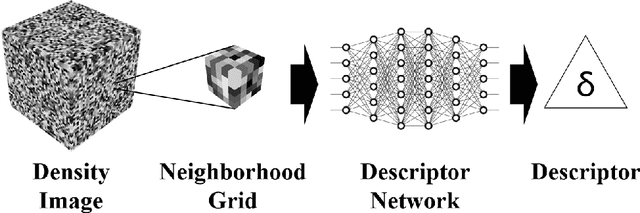

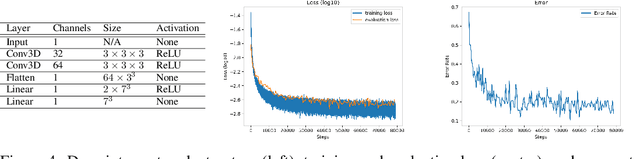
No significant work has been done to directly merge two partially overlapping scenes using NeRF representations. Given pre-trained NeRF models of a 3D scene with partial overlapping, this paper aligns them with a rigid transform, by generalizing the traditional registration pipeline, that is, key point detection and point set registration, to operate on 3D density fields. To describe corner points as key points in 3D, we propose to use universal pre-trained descriptor-generating neural networks that can be trained and tested on different scenes. We perform experiments to demonstrate that the descriptor networks can be conveniently trained using a contrastive learning strategy. We demonstrate that our method, as a global approach, can effectively register NeRF models, thus making possible future large-scale NeRF construction by registering its smaller and overlapping NeRFs captured individually.