 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Flow Matching for Motion Prediction
Dec 27, 2025Motion prediction has been studied in different contexts with models trained on narrow distributions and applied to downstream tasks in human motion prediction and robotics. Simultaneously, recent efforts in scaling video prediction have demonstrated impressive visual realism, yet they struggle to accurately model complex motions despite massive scale. Inspired by the scaling of video generation, we develop autoregressive flow matching (ARFM), a new method for probabilistic modeling of sequential continuous data and train it on diverse video datasets to generate future point track locations over long horizons. To evaluate our model, we develop benchmarks for evaluating the ability of motion prediction models to predict human and robot motion. Our model is able to predict complex motions, and we demonstrate that conditioning robot action prediction and human motion prediction on predicted future tracks can significantly improve downstream task performance. Code and models publicly available at: https://github.com/Johnathan-Xie/arfm-motion-prediction.
Understanding Complexity in VideoQA via Visual Program Generation
May 19, 2025We propose a data-driven approach to analyzing query complexity in Video Question Answering (VideoQA). Previous efforts in benchmark design have relied on human expertise to design challenging questions, yet we experimentally show that humans struggle to predict which questions are difficult for machine learning models. Our automatic approach leverages recent advances in code generation for visual question answering, using the complexity of generated code as a proxy for question difficulty. We demonstrate that this measure correlates significantly better with model performance than human estimates. To operationalize this insight, we propose an algorithm for estimating question complexity from code. It identifies fine-grained primitives that correlate with the hardest questions for any given set of models, making it easy to scale to new approaches in the future. Finally, to further illustrate the utility of our method, we extend it to automatically generate complex questions, constructing a new benchmark that is 1.9 times harder than the popular NExT-QA.
Re-thinking Temporal Search for Long-Form Video Understanding
Apr 03, 2025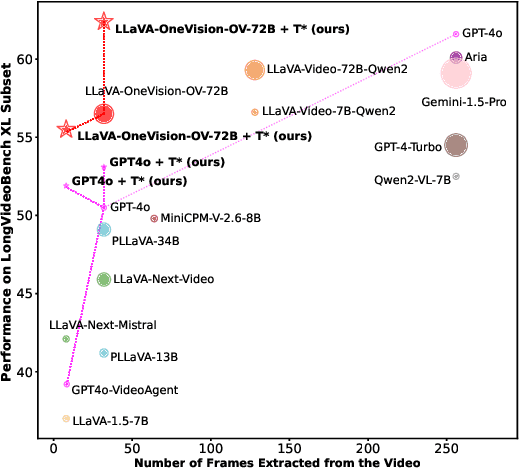
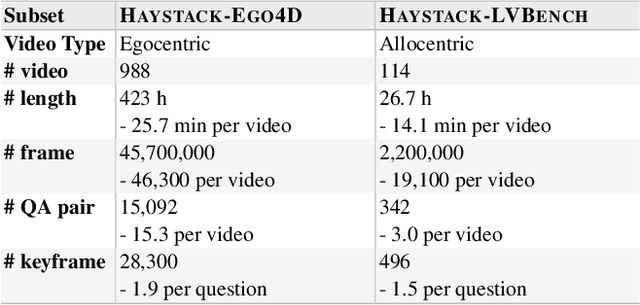
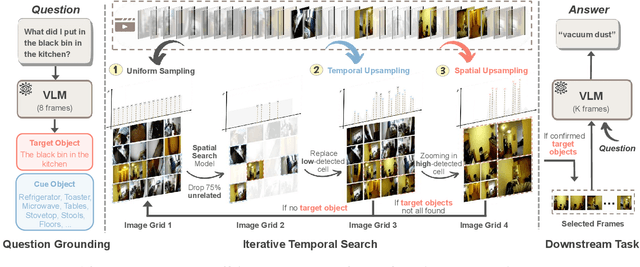
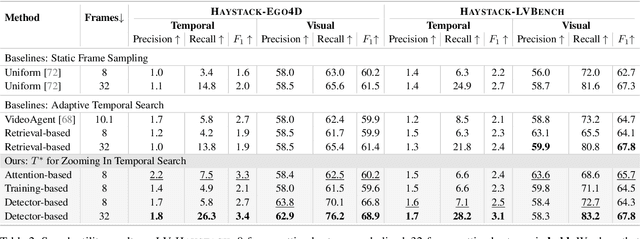
Efficient understanding of long-form videos remains a significant challenge in computer vision. In this work, we revisit temporal search paradigms for long-form video understanding, studying a fundamental issue pertaining to all state-of-the-art (SOTA) long-context vision-language models (VLMs). In particular, our contributions are two-fold: First, we formulate temporal search as a Long Video Haystack problem, i.e., finding a minimal set of relevant frames (typically one to five) among tens of thousands of frames from real-world long videos given specific queries. To validate our formulation, we create LV-Haystack, the first benchmark containing 3,874 human-annotated instances with fine-grained evaluation metrics for assessing keyframe search quality and computational efficiency. Experimental results on LV-Haystack highlight a significant research gap in temporal search capabilities, with SOTA keyframe selection methods achieving only 2.1% temporal F1 score on the LVBench subset. Next, inspired by visual search in images, we re-think temporal searching and propose a lightweight keyframe searching framework, T*, which casts the expensive temporal search as a spatial search problem. T* leverages superior visual localization capabilities typically used in images and introduces an adaptive zooming-in mechanism that operates across both temporal and spatial dimensions. Our extensive experiments show that when integrated with existing methods, T* significantly improves SOTA long-form video understanding performance. Specifically, under an inference budget of 32 frames, T* improves GPT-4o's performance from 50.5% to 53.1% and LLaVA-OneVision-72B's performance from 56.5% to 62.4% on LongVideoBench XL subset. Our PyTorch code, benchmark dataset and models are included in the Supplementary material.
Streaming Detection of Queried Event Start
Dec 04, 2024



Robotics, autonomous driving, augmented reality, and many embodied computer vision applications must quickly react to user-defined events unfolding in real time. We address this setting by proposing a novel task for multimodal video understanding-Streaming Detection of Queried Event Start (SDQES). The goal of SDQES is to identify the beginning of a complex event as described by a natural language query, with high accuracy and low latency. We introduce a new benchmark based on the Ego4D dataset, as well as new task-specific metrics to study streaming multimodal detection of diverse events in an egocentric video setting. Inspired by parameter-efficient fine-tuning methods in NLP and for video tasks, we propose adapter-based baselines that enable image-to-video transfer learning, allowing for efficient online video modeling. We evaluate three vision-language backbones and three adapter architectures on both short-clip and untrimmed video settings.
IKEA Manuals at Work: 4D Grounding of Assembly Instructions on Internet Videos
Nov 18, 2024Shape assembly is a ubiquitous task in daily life, integral for constructing complex 3D structures like IKEA furniture. While significant progress has been made in developing autonomous agents for shape assembly, existing datasets have not yet tackled the 4D grounding of assembly instructions in videos, essential for a holistic understanding of assembly in 3D space over time. We introduce IKEA Video Manuals, a dataset that features 3D models of furniture parts, instructional manuals, assembly videos from the Internet, and most importantly, annotations of dense spatio-temporal alignments between these data modalities. To demonstrate the utility of IKEA Video Manuals, we present five applications essential for shape assembly: assembly plan generation, part-conditioned segmentation, part-conditioned pose estimation, video object segmentation, and furniture assembly based on instructional video manuals. For each application, we provide evaluation metrics and baseline methods. Through experiments on our annotated data, we highlight many challenges in grounding assembly instructions in videos to improve shape assembly, including handling occlusions, varying viewpoints, and extended assembly sequences.
Differentiable Adaptive Computation Time for Visual Reasoning
May 22, 2020
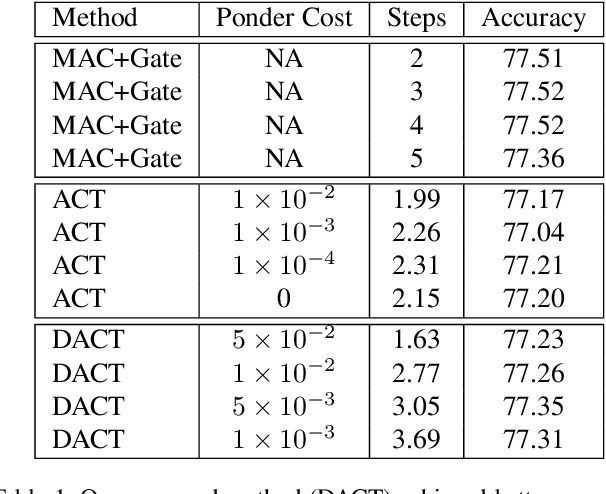
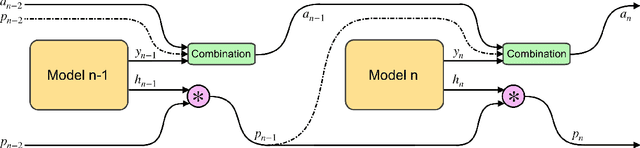
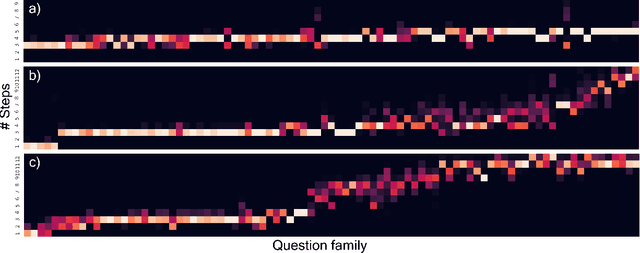
This paper presents a novel attention-based algorithm for achieving adaptive computation called DACT, which, unlike existing ones, is end-to-end differentiable. Our method can be used in conjunction with many networks; in particular, we study its application to the widely known MAC architecture, obtaining a significant reduction in the number of recurrent steps needed to achieve similar accuracies, therefore improving its performance to computation ratio. Furthermore, we show that by increasing the maximum number of steps used, we surpass the accuracy of even our best non-adaptive MAC in the CLEVR dataset, demonstrating that our approach is able to control the number of steps without significant loss of performance. Additional advantages provided by our approach include considerably improving interpretability by discarding useless steps and providing more insights into the underlying reasoning process. Finally, we present adaptive computation as an equivalent to an ensemble of models, similar to a mixture of expert formulation. Both the code and the configuration files for our experiments are made available to support further research in this area.