 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Compositional Behaviors from Demonstration and Language
May 28, 2025



We introduce Behavior from Language and Demonstration (BLADE), a framework for long-horizon robotic manipulation by integrating imitation learning and model-based planning. BLADE leverages language-annotated demonstrations, extracts abstract action knowledge from large language models (LLMs), and constructs a library of structured, high-level action representations. These representations include preconditions and effects grounded in visual perception for each high-level action, along with corresponding controllers implemented as neural network-based policies. BLADE can recover such structured representations automatically, without manually labeled states or symbolic definitions. BLADE shows significant capabilities in generalizing to novel situations, including novel initial states, external state perturbations, and novel goals. We validate the effectiveness of our approach both in simulation and on real robots with a diverse set of objects with articulated parts, partial observability, and geometric constraints.
LayoutVLM: Differentiable Optimization of 3D Layout via Vision-Language Models
Dec 03, 2024



Open-universe 3D layout generation arranges unlabeled 3D assets conditioned on language instruction. Large language models (LLMs) struggle with generating physically plausible 3D scenes and adherence to input instructions, particularly in cluttered scenes. We introduce LayoutVLM, a framework and scene layout representation that exploits the semantic knowledge of Vision-Language Models (VLMs) and supports differentiable optimization to ensure physical plausibility. LayoutVLM employs VLMs to generate two mutually reinforcing representations from visually marked images, and a self-consistent decoding process to improve VLMs spatial planning. Our experiments show that LayoutVLM addresses the limitations of existing LLM and constraint-based approaches, producing physically plausible 3D layouts better aligned with the semantic intent of input language instructions. We also demonstrate that fine-tuning VLMs with the proposed scene layout representation extracted from existing scene datasets can improve performance.
IKEA Manuals at Work: 4D Grounding of Assembly Instructions on Internet Videos
Nov 18, 2024Shape assembly is a ubiquitous task in daily life, integral for constructing complex 3D structures like IKEA furniture. While significant progress has been made in developing autonomous agents for shape assembly, existing datasets have not yet tackled the 4D grounding of assembly instructions in videos, essential for a holistic understanding of assembly in 3D space over time. We introduce IKEA Video Manuals, a dataset that features 3D models of furniture parts, instructional manuals, assembly videos from the Internet, and most importantly, annotations of dense spatio-temporal alignments between these data modalities. To demonstrate the utility of IKEA Video Manuals, we present five applications essential for shape assembly: assembly plan generation, part-conditioned segmentation, part-conditioned pose estimation, video object segmentation, and furniture assembly based on instructional video manuals. For each application, we provide evaluation metrics and baseline methods. Through experiments on our annotated data, we highlight many challenges in grounding assembly instructions in videos to improve shape assembly, including handling occlusions, varying viewpoints, and extended assembly sequences.
Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making
Oct 09, 2024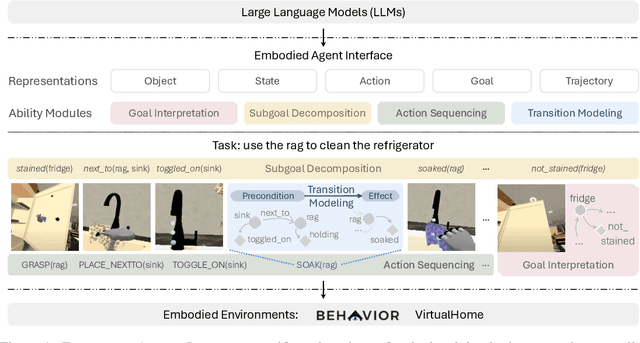

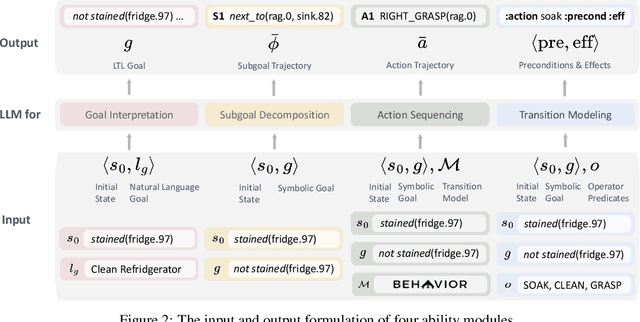
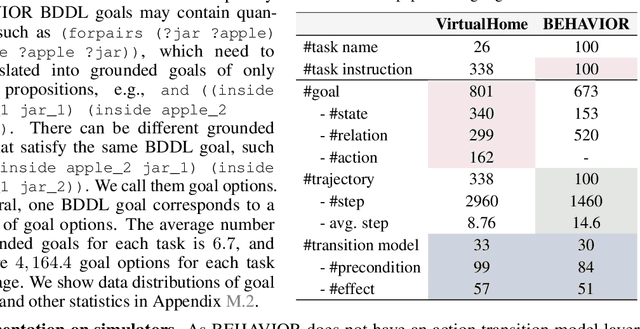
We aim to evaluate Large Language Models (LLMs) for embodied decision making. While a significant body of work has been leveraging LLMs for decision making in embodied environments, we still lack a systematic understanding of their performance because they are usually applied in different domains, for different purposes, and built based on different inputs and outputs. Furthermore, existing evaluations tend to rely solely on a final success rate, making it difficult to pinpoint what ability is missing in LLMs and where the problem lies, which in turn blocks embodied agents from leveraging LLMs effectively and selectively. To address these limitations, we propose a generalized interface (Embodied Agent Interface) that supports the formalization of various types of tasks and input-output specifications of LLM-based modules. Specifically, it allows us to unify 1) a broad set of embodied decision-making tasks involving both state and temporally extended goals, 2) four commonly-used LLM-based modules for decision making: goal interpretation, subgoal decomposition, action sequencing, and transition modeling, and 3) a collection of fine-grained metrics which break down evaluation into various types of errors, such as hallucination errors, affordance errors, various types of planning errors, etc. Overall, our benchmark offers a comprehensive assessment of LLMs' performance for different subtasks, pinpointing the strengths and weaknesses in LLM-powered embodied AI systems, and providing insights for effective and selective use of LLMs in embodied decision making.
MARPLE: A Benchmark for Long-Horizon Inference
Oct 02, 2024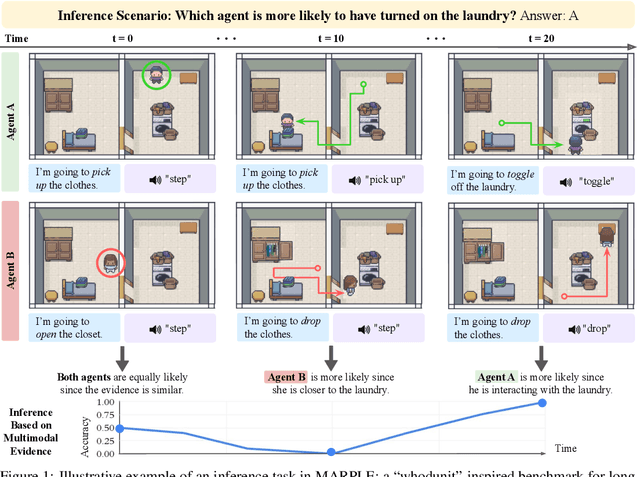

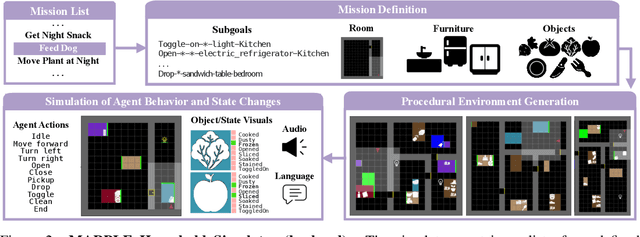

Reconstructing past events requires reasoning across long time horizons. To figure out what happened, we need to use our prior knowledge about the world and human behavior and draw inferences from various sources of evidence including visual, language, and auditory cues. We introduce MARPLE, a benchmark for evaluating long-horizon inference capabilities using multi-modal evidence. Our benchmark features agents interacting with simulated households, supporting vision, language, and auditory stimuli, as well as procedurally generated environments and agent behaviors. Inspired by classic ``whodunit'' stories, we ask AI models and human participants to infer which agent caused a change in the environment based on a step-by-step replay of what actually happened. The goal is to correctly identify the culprit as early as possible. Our findings show that human participants outperform both traditional Monte Carlo simulation methods and an LLM baseline (GPT-4) on this task. Compared to humans, traditional inference models are less robust and performant, while GPT-4 has difficulty comprehending environmental changes. We analyze what factors influence inference performance and ablate different modes of evidence, finding that all modes are valuable for performance. Overall, our experiments demonstrate that the long-horizon, multimodal inference tasks in our benchmark present a challenge to current models.
Semantically-Driven Disambiguation for Human-Robot Interaction
Sep 25, 2024Ambiguities are common in human-robot interaction, especially when a robot follows user instructions in a large collocated space. For instance, when the user asks the robot to find an object in a home environment, the object might be in several places depending on its varying semantic properties (e.g., a bowl can be in the kitchen cabinet or on the dining room table, depending on whether it is clean/dirty, full/empty and the other objects around it). Previous works on object semantics have predicted such relationships using one shot-inferences which are likely to fail for ambiguous or partially understood instructions. This paper focuses on this gap and suggests a semantically-driven disambiguation approach by utilizing follow-up clarifications to handle such uncertainties. To achieve this, we first obtain semantic knowledge embeddings, and then these embeddings are used to generate clarifying questions by following an iterative process. The evaluation of our method shows that our approach is model agnostic, i.e., applicable to different semantic embedding models, and follow-up clarifications improve the performance regardless of the embedding model. Additionally, our ablation studies show the significance of informative clarifications and iterative predictions to enhance system accuracies.
Composable Part-Based Manipulation
May 09, 2024



In this paper, we propose composable part-based manipulation (CPM), a novel approach that leverages object-part decomposition and part-part correspondences to improve learning and generalization of robotic manipulation skills. By considering the functional correspondences between object parts, we conceptualize functional actions, such as pouring and constrained placing, as combinations of different correspondence constraints. CPM comprises a collection of composable diffusion models, where each model captures a different inter-object correspondence. These diffusion models can generate parameters for manipulation skills based on the specific object parts. Leveraging part-based correspondences coupled with the task decomposition into distinct constraints enables strong generalization to novel objects and object categories. We validate our approach in both simulated and real-world scenarios, demonstrating its effectiveness in achieving robust and generalized manipulation capabilities.
Learning Planning Abstractions from Language
May 06, 2024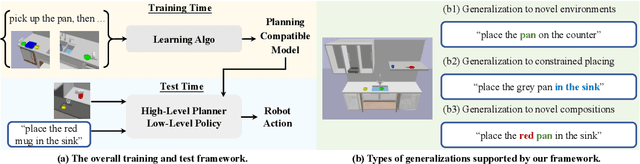
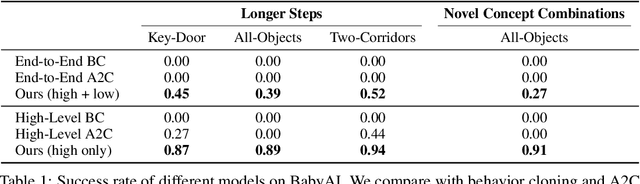


This paper presents a framework for learning state and action abstractions in sequential decision-making domains. Our framework, planning abstraction from language (PARL), utilizes language-annotated demonstrations to automatically discover a symbolic and abstract action space and induce a latent state abstraction based on it. PARL consists of three stages: 1) recovering object-level and action concepts, 2) learning state abstractions, abstract action feasibility, and transition models, and 3) applying low-level policies for abstract actions. During inference, given the task description, PARL first makes abstract action plans using the latent transition and feasibility functions, then refines the high-level plan using low-level policies. PARL generalizes across scenarios involving novel object instances and environments, unseen concept compositions, and tasks that require longer planning horizons than settings it is trained on.
Naturally Supervised 3D Visual Grounding with Language-Regularized Concept Learners
Apr 30, 2024



3D visual grounding is a challenging task that often requires direct and dense supervision, notably the semantic label for each object in the scene. In this paper, we instead study the naturally supervised setting that learns from only 3D scene and QA pairs, where prior works underperform. We propose the Language-Regularized Concept Learner (LARC), which uses constraints from language as regularization to significantly improve the accuracy of neuro-symbolic concept learners in the naturally supervised setting. Our approach is based on two core insights: the first is that language constraints (e.g., a word's relation to another) can serve as effective regularization for structured representations in neuro-symbolic models; the second is that we can query large language models to distill such constraints from language properties. We show that LARC improves performance of prior works in naturally supervised 3D visual grounding, and demonstrates a wide range of 3D visual reasoning capabilities-from zero-shot composition, to data efficiency and transferability. Our method represents a promising step towards regularizing structured visual reasoning frameworks with language-based priors, for learning in settings without dense supervision.
Foundation Models in Robotics: Applications, Challenges, and the Future
Dec 13, 2023


We survey applications of pretrained foundation models in robotics. Traditional deep learning models in robotics are trained on small datasets tailored for specific tasks, which limits their adaptability across diverse applications. In contrast, foundation models pretrained on internet-scale data appear to have superior generalization capabilities, and in some instances display an emergent ability to find zero-shot solutions to problems that are not present in the training data. Foundation models may hold the potential to enhance various components of the robot autonomy stack, from perception to decision-making and control. For example, large language models can generate code or provide common sense reasoning, while vision-language models enable open-vocabulary visual recognition. However, significant open research challenges remain, particularly around the scarcity of robot-relevant training data, safety guarantees and uncertainty quantification, and real-time execution. In this survey, we study recent papers that have used or built foundation models to solve robotics problems. We explore how foundation models contribute to improving robot capabilities in the domains of perception, decision-making, and control. We discuss the challenges hindering the adoption of foundation models in robot autonomy and provide opportunities and potential pathways for future advancements. The GitHub project corresponding to this paper (Preliminary release. We are committed to further enhancing and updating this work to ensure its quality and relevance) can be found here: https://github.com/robotics-survey/Awesome-Robotics-Foundation-Models