 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Multimodal Protein Design Enables DNA-Encoding of Chemistry
Apr 06, 2026Evolution is an extraordinary engine for enzymatic diversity, yet the chemistry it has explored remains a narrow slice of what DNA can encode. Deep generative models can design new proteins that bind ligands, but none have created enzymes without pre-specifying catalytic residues. We introduce DISCO (DIffusion for Sequence-structure CO-design), a multimodal model that co-designs protein sequence and 3D structure around arbitrary biomolecules, as well as inference-time scaling methods that optimize objectives across both modalities. Conditioned solely on reactive intermediates, DISCO designs diverse heme enzymes with novel active-site geometries. These enzymes catalyze new-to-nature carbene-transfer reactions, including alkene cyclopropanation, spirocyclopropanation, B-H, and C(sp$^3$)-H insertions, with high activities exceeding those of engineered enzymes. Random mutagenesis of a selected design further confirmed that enzyme activity can be improved through directed evolution. By providing a scalable route to evolvable enzymes, DISCO broadens the potential scope of genetically encodable transformations. Code is available at https://github.com/DISCO-design/DISCO.
Predicate Hierarchies Improve Few-Shot State Classification
Feb 18, 2025



State classification of objects and their relations is core to many long-horizon tasks, particularly in robot planning and manipulation. However, the combinatorial explosion of possible object-predicate combinations, coupled with the need to adapt to novel real-world environments, makes it a desideratum for state classification models to generalize to novel queries with few examples. To this end, we propose PHIER, which leverages predicate hierarchies to generalize effectively in few-shot scenarios. PHIER uses an object-centric scene encoder, self-supervised losses that infer semantic relations between predicates, and a hyperbolic distance metric that captures hierarchical structure; it learns a structured latent space of image-predicate pairs that guides reasoning over state classification queries. We evaluate PHIER in the CALVIN and BEHAVIOR robotic environments and show that PHIER significantly outperforms existing methods in few-shot, out-of-distribution state classification, and demonstrates strong zero- and few-shot generalization from simulated to real-world tasks. Our results demonstrate that leveraging predicate hierarchies improves performance on state classification tasks with limited data.
Homomorphism Counts as Structural Encodings for Graph Learning
Oct 24, 2024Graph Transformers are popular neural networks that extend the well-known Transformer architecture to the graph domain. These architectures operate by applying self-attention on graph nodes and incorporating graph structure through the use of positional encodings (e.g., Laplacian positional encoding) or structural encodings (e.g., random-walk structural encoding). The quality of such encodings is critical, since they provide the necessary $\textit{graph inductive biases}$ to condition the model on graph structure. In this work, we propose $\textit{motif structural encoding}$ (MoSE) as a flexible and powerful structural encoding framework based on counting graph homomorphisms. Theoretically, we compare the expressive power of MoSE to random-walk structural encoding and relate both encodings to the expressive power of standard message passing neural networks. Empirically, we observe that MoSE outperforms other well-known positional and structural encodings across a range of architectures, and it achieves state-of-the-art performance on widely studied molecular property prediction datasets.
MARPLE: A Benchmark for Long-Horizon Inference
Oct 02, 2024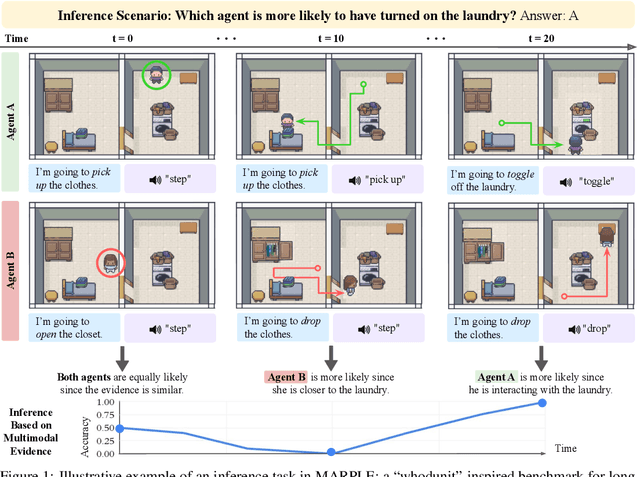

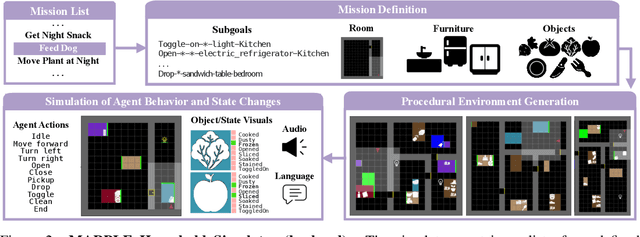

Reconstructing past events requires reasoning across long time horizons. To figure out what happened, we need to use our prior knowledge about the world and human behavior and draw inferences from various sources of evidence including visual, language, and auditory cues. We introduce MARPLE, a benchmark for evaluating long-horizon inference capabilities using multi-modal evidence. Our benchmark features agents interacting with simulated households, supporting vision, language, and auditory stimuli, as well as procedurally generated environments and agent behaviors. Inspired by classic ``whodunit'' stories, we ask AI models and human participants to infer which agent caused a change in the environment based on a step-by-step replay of what actually happened. The goal is to correctly identify the culprit as early as possible. Our findings show that human participants outperform both traditional Monte Carlo simulation methods and an LLM baseline (GPT-4) on this task. Compared to humans, traditional inference models are less robust and performant, while GPT-4 has difficulty comprehending environmental changes. We analyze what factors influence inference performance and ablate different modes of evidence, finding that all modes are valuable for performance. Overall, our experiments demonstrate that the long-horizon, multimodal inference tasks in our benchmark present a challenge to current models.
Homomorphism Counts for Graph Neural Networks: All About That Basis
Feb 24, 2024Graph neural networks are architectures for learning invariant functions over graphs. A large body of work has investigated the properties of graph neural networks and identified several limitations, particularly pertaining to their expressive power. Their inability to count certain patterns (e.g., cycles) in a graph lies at the heart of such limitations, since many functions to be learned rely on the ability of counting such patterns. Two prominent paradigms aim to address this limitation by enriching the graph features with subgraph or homomorphism pattern counts. In this work, we show that both of these approaches are sub-optimal in a certain sense and argue for a more fine-grained approach, which incorporates the homomorphism counts of all structures in the "basis" of the target pattern. This yields strictly more expressive architectures without incurring any additional overhead in terms of computational complexity compared to existing approaches. We prove a series of theoretical results on node-level and graph-level motif parameters and empirically validate them on standard benchmark datasets.
Mini-BEHAVIOR: A Procedurally Generated Benchmark for Long-horizon Decision-Making in Embodied AI
Oct 03, 2023



We present Mini-BEHAVIOR, a novel benchmark for embodied AI that challenges agents to use reasoning and decision-making skills to solve complex activities that resemble everyday human challenges. The Mini-BEHAVIOR environment is a fast, realistic Gridworld environment that offers the benefits of rapid prototyping and ease of use while preserving a symbolic level of physical realism and complexity found in complex embodied AI benchmarks. We introduce key features such as procedural generation, to enable the creation of countless task variations and support open-ended learning. Mini-BEHAVIOR provides implementations of various household tasks from the original BEHAVIOR benchmark, along with starter code for data collection and reinforcement learning agent training. In essence, Mini-BEHAVIOR offers a fast, open-ended benchmark for evaluating decision-making and planning solutions in embodied AI. It serves as a user-friendly entry point for research and facilitates the evaluation and development of solutions, simplifying their assessment and development while advancing the field of embodied AI. Code is publicly available at https://github.com/StanfordVL/mini_behavior.
Modeling Dynamic Environments with Scene Graph Memory
Jun 12, 2023Embodied AI agents that search for objects in large environments such as households often need to make efficient decisions by predicting object locations based on partial information. We pose this as a new type of link prediction problem: link prediction on partially observable dynamic graphs. Our graph is a representation of a scene in which rooms and objects are nodes, and their relationships are encoded in the edges; only parts of the changing graph are known to the agent at each timestep. This partial observability poses a challenge to existing link prediction approaches, which we address. We propose a novel state representation -- Scene Graph Memory (SGM) -- with captures the agent's accumulated set of observations, as well as a neural net architecture called a Node Edge Predictor (NEP) that extracts information from the SGM to search efficiently. We evaluate our method in the Dynamic House Simulator, a new benchmark that creates diverse dynamic graphs following the semantic patterns typically seen at homes, and show that NEP can be trained to predict the locations of objects in a variety of environments with diverse object movement dynamics, outperforming baselines both in terms of new scene adaptability and overall accuracy. The codebase and more can be found at https://www.scenegraphmemory.com.