 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-literal Understanding of Number Words by Language Models
Feb 10, 2025
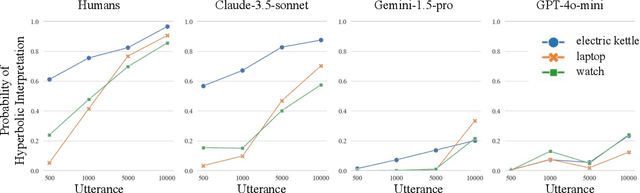

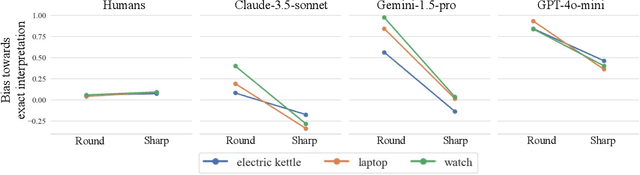
Humans naturally interpret numbers non-literally, effortlessly combining context, world knowledge, and speaker intent. We investigate whether large language models (LLMs) interpret numbers similarly, focusing on hyperbole and pragmatic halo effects. Through systematic comparison with human data and computational models of pragmatic reasoning, we find that LLMs diverge from human interpretation in striking ways. By decomposing pragmatic reasoning into testable components, grounded in the Rational Speech Act framework, we pinpoint where LLM processing diverges from human cognition -- not in prior knowledge, but in reasoning with it. This insight leads us to develop a targeted solution -- chain-of-thought prompting inspired by an RSA model makes LLMs' interpretations more human-like. Our work demonstrates how computational cognitive models can both diagnose AI-human differences and guide development of more human-like language understanding capabilities.
MARPLE: A Benchmark for Long-Horizon Inference
Oct 02, 2024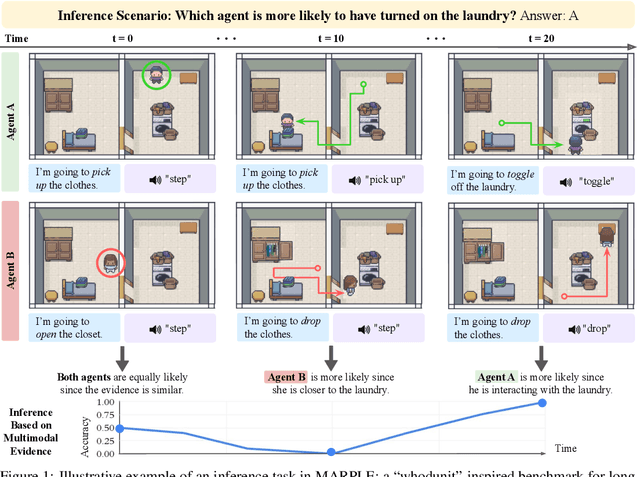

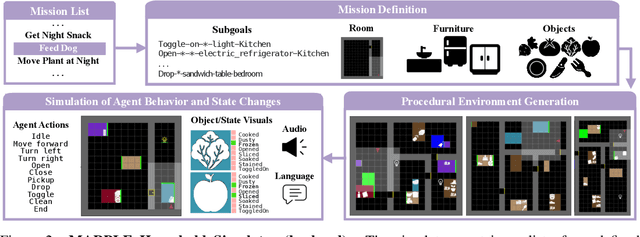

Reconstructing past events requires reasoning across long time horizons. To figure out what happened, we need to use our prior knowledge about the world and human behavior and draw inferences from various sources of evidence including visual, language, and auditory cues. We introduce MARPLE, a benchmark for evaluating long-horizon inference capabilities using multi-modal evidence. Our benchmark features agents interacting with simulated households, supporting vision, language, and auditory stimuli, as well as procedurally generated environments and agent behaviors. Inspired by classic ``whodunit'' stories, we ask AI models and human participants to infer which agent caused a change in the environment based on a step-by-step replay of what actually happened. The goal is to correctly identify the culprit as early as possible. Our findings show that human participants outperform both traditional Monte Carlo simulation methods and an LLM baseline (GPT-4) on this task. Compared to humans, traditional inference models are less robust and performant, while GPT-4 has difficulty comprehending environmental changes. We analyze what factors influence inference performance and ablate different modes of evidence, finding that all modes are valuable for performance. Overall, our experiments demonstrate that the long-horizon, multimodal inference tasks in our benchmark present a challenge to current models.
Human-like Affective Cognition in Foundation Models
Sep 19, 2024Understanding emotions is fundamental to human interaction and experience. Humans easily infer emotions from situations or facial expressions, situations from emotions, and do a variety of other affective cognition. How adept is modern AI at these inferences? We introduce an evaluation framework for testing affective cognition in foundation models. Starting from psychological theory, we generate 1,280 diverse scenarios exploring relationships between appraisals, emotions, expressions, and outcomes. We evaluate the abilities of foundation models (GPT-4, Claude-3, Gemini-1.5-Pro) and humans (N = 567) across carefully selected conditions. Our results show foundation models tend to agree with human intuitions, matching or exceeding interparticipant agreement. In some conditions, models are ``superhuman'' -- they better predict modal human judgements than the average human. All models benefit from chain-of-thought reasoning. This suggests foundation models have acquired a human-like understanding of emotions and their influence on beliefs and behavior.
PERSONA: A Reproducible Testbed for Pluralistic Alignment
Jul 24, 2024The rapid advancement of language models (LMs) necessitates robust alignment with diverse user values. However, current preference optimization approaches often fail to capture the plurality of user opinions, instead reinforcing majority viewpoints and marginalizing minority perspectives. We introduce PERSONA, a reproducible test bed designed to evaluate and improve pluralistic alignment of LMs. We procedurally generate diverse user profiles from US census data, resulting in 1,586 synthetic personas with varied demographic and idiosyncratic attributes. We then generate a large-scale evaluation dataset containing 3,868 prompts and 317,200 feedback pairs obtained from our synthetic personas. Leveraging this dataset, we systematically evaluate LM capabilities in role-playing diverse users, verified through human judges, and the establishment of both a benchmark, PERSONA Bench, for pluralistic alignment approaches as well as an extensive dataset to create new and future benchmarks. The full dataset and benchmarks are available here: https://www.synthlabs.ai/research/persona.
Self-Supervised Alignment with Mutual Information: Learning to Follow Principles without Preference Labels
Apr 22, 2024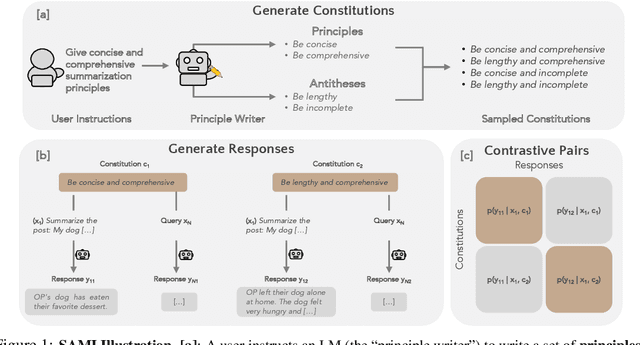
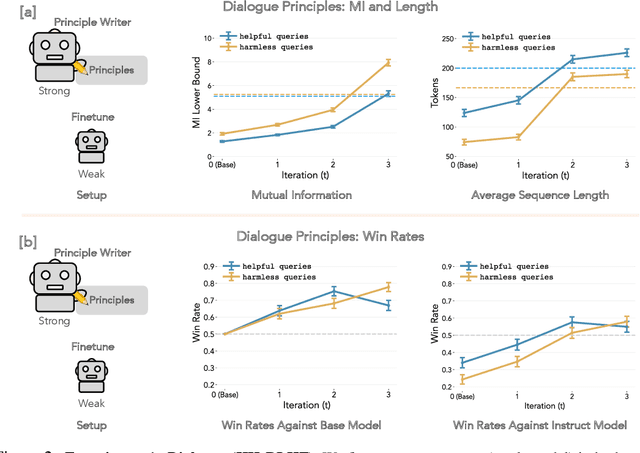

When prompting a language model (LM), users frequently expect the model to adhere to a set of behavioral principles across diverse tasks, such as producing insightful content while avoiding harmful or biased language. Instilling such principles into a model can be resource-intensive and technically challenging, generally requiring human preference labels or examples. We introduce SAMI, a method for teaching a pretrained LM to follow behavioral principles that does not require any preference labels or demonstrations. SAMI is an iterative algorithm that finetunes a pretrained LM to increase the conditional mutual information between constitutions and self-generated responses given queries from a datasest. On single-turn dialogue and summarization, a SAMI-trained mistral-7b outperforms the initial pretrained model, with win rates between 66% and 77%. Strikingly, it also surpasses an instruction-finetuned baseline (mistral-7b-instruct) with win rates between 55% and 57% on single-turn dialogue. SAMI requires a "principle writer" model; to avoid dependence on stronger models, we further evaluate aligning a strong pretrained model (mixtral-8x7b) using constitutions written by a weak instruction-finetuned model (mistral-7b-instruct). The SAMI-trained mixtral-8x7b outperforms both the initial model and the instruction-finetuned model, achieving a 65% win rate on summarization. Our results indicate that a pretrained LM can learn to follow constitutions without using preference labels, demonstrations, or human oversight.
Procedural Dilemma Generation for Evaluating Moral Reasoning in Humans and Language Models
Apr 17, 2024



As AI systems like language models are increasingly integrated into decision-making processes affecting people's lives, it's critical to ensure that these systems have sound moral reasoning. To test whether they do, we need to develop systematic evaluations. We provide a framework that uses a language model to translate causal graphs that capture key aspects of moral dilemmas into prompt templates. With this framework, we procedurally generated a large and diverse set of moral dilemmas -- the OffTheRails benchmark -- consisting of 50 scenarios and 400 unique test items. We collected moral permissibility and intention judgments from human participants for a subset of our items and compared these judgments to those from two language models (GPT-4 and Claude-2) across eight conditions. We find that moral dilemmas in which the harm is a necessary means (as compared to a side effect) resulted in lower permissibility and higher intention ratings for both participants and language models. The same pattern was observed for evitable versus inevitable harmful outcomes. However, there was no clear effect of whether the harm resulted from an agent's action versus from having omitted to act. We discuss limitations of our prompt generation pipeline and opportunities for improving scenarios to increase the strength of experimental effects.
STaR-GATE: Teaching Language Models to Ask Clarifying Questions
Mar 29, 2024When prompting language models to complete a task, users often leave important aspects unsaid. While asking questions could resolve this ambiguity (GATE; Li et al., 2023), models often struggle to ask good questions. We explore a language model's ability to self-improve (STaR; Zelikman et al., 2022) by rewarding the model for generating useful questions-a simple method we dub STaR-GATE. We generate a synthetic dataset of 25,500 unique persona-task prompts to simulate conversations between a pretrained language model-the Questioner-and a Roleplayer whose preferences are unknown to the Questioner. By asking questions, the Questioner elicits preferences from the Roleplayer. The Questioner is iteratively finetuned on questions that increase the probability of high-quality responses to the task, which are generated by an Oracle with access to the Roleplayer's latent preferences. After two iterations of self-improvement, the Questioner asks better questions, allowing it to generate responses that are preferred over responses from the initial model on 72% of tasks. Our results indicate that teaching a language model to ask better questions leads to better personalized responses.
Social Contract AI: Aligning AI Assistants with Implicit Group Norms
Oct 26, 2023We explore the idea of aligning an AI assistant by inverting a model of users' (unknown) preferences from observed interactions. To validate our proposal, we run proof-of-concept simulations in the economic ultimatum game, formalizing user preferences as policies that guide the actions of simulated players. We find that the AI assistant accurately aligns its behavior to match standard policies from the economic literature (e.g., selfish, altruistic). However, the assistant's learned policies lack robustness and exhibit limited generalization in an out-of-distribution setting when confronted with a currency (e.g., grams of medicine) that was not included in the assistant's training distribution. Additionally, we find that when there is inconsistency in the relationship between language use and an unknown policy (e.g., an altruistic policy combined with rude language), the assistant's learning of the policy is slowed. Overall, our preliminary results suggest that developing simulation frameworks in which AI assistants need to infer preferences from diverse users can provide a valuable approach for studying practical alignment questions.
Understanding Social Reasoning in Language Models with Language Models
Jun 21, 2023



As Large Language Models (LLMs) become increasingly integrated into our everyday lives, understanding their ability to comprehend human mental states becomes critical for ensuring effective interactions. However, despite the recent attempts to assess the Theory-of-Mind (ToM) reasoning capabilities of LLMs, the degree to which these models can align with human ToM remains a nuanced topic of exploration. This is primarily due to two distinct challenges: (1) the presence of inconsistent results from previous evaluations, and (2) concerns surrounding the validity of existing evaluation methodologies. To address these challenges, we present a novel framework for procedurally generating evaluations with LLMs by populating causal templates. Using our framework, we create a new social reasoning benchmark (BigToM) for LLMs which consists of 25 controls and 5,000 model-written evaluations. We find that human participants rate the quality of our benchmark higher than previous crowd-sourced evaluations and comparable to expert-written evaluations. Using BigToM, we evaluate the social reasoning capabilities of a variety of LLMs and compare model performances with human performance. Our results suggest that GPT4 has ToM capabilities that mirror human inference patterns, though less reliable, while other LLMs struggle.