 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Retrieving Information to Reasoning with AI: Exploring Different Interaction Modalities to Support Human-AI Coordination in Clinical Decision-Making
Jan 29, 2026LLMs are popular among clinicians for decision-support because of simple text-based interaction. However, their impact on clinicians' performance is ambiguous. Not knowing how clinicians use this new technology and how they compare it to traditional clinical decision-support systems (CDSS) restricts designing novel mechanisms that overcome existing tool limitations and enhance performance and experience. This qualitative study examines how clinicians (n=12) perceive different interaction modalities (text-based conversation with LLMs, interactive and static UI, and voice) for decision-support. In open-ended use of LLM-based tools, our participants took a tool-centric approach using them for information retrieval and confirmation with simple prompts instead of use as active deliberation partners that can handle complex questions. Critical engagement emerged with changes to the interaction setup. Engagement also differed with individual cognitive styles. Lastly, benefits and drawbacks of interaction with text, voice and traditional UIs for clinical decision-support show the lack of a one-size-fits-all interaction modality.
Causal-PIK: Causality-based Physical Reasoning with a Physics-Informed Kernel
May 28, 2025



Tasks that involve complex interactions between objects with unknown dynamics make planning before execution difficult. These tasks require agents to iteratively improve their actions after actively exploring causes and effects in the environment. For these type of tasks, we propose Causal-PIK, a method that leverages Bayesian optimization to reason about causal interactions via a Physics-Informed Kernel to help guide efficient search for the best next action. Experimental results on Virtual Tools and PHYRE physical reasoning benchmarks show that Causal-PIK outperforms state-of-the-art results, requiring fewer actions to reach the goal. We also compare Causal-PIK to human studies, including results from a new user study we conducted on the PHYRE benchmark. We find that Causal-PIK remains competitive on tasks that are very challenging, even for human problem-solvers.
Imagining and building wise machines: The centrality of AI metacognition
Nov 04, 2024


Recent advances in artificial intelligence (AI) have produced systems capable of increasingly sophisticated performance on cognitive tasks. However, AI systems still struggle in critical ways: unpredictable and novel environments (robustness), lack of transparency in their reasoning (explainability), challenges in communication and commitment (cooperation), and risks due to potential harmful actions (safety). We argue that these shortcomings stem from one overarching failure: AI systems lack wisdom. Drawing from cognitive and social sciences, we define wisdom as the ability to navigate intractable problems - those that are ambiguous, radically uncertain, novel, chaotic, or computationally explosive - through effective task-level and metacognitive strategies. While AI research has focused on task-level strategies, metacognition - the ability to reflect on and regulate one's thought processes - is underdeveloped in AI systems. In humans, metacognitive strategies such as recognizing the limits of one's knowledge, considering diverse perspectives, and adapting to context are essential for wise decision-making. We propose that integrating metacognitive capabilities into AI systems is crucial for enhancing their robustness, explainability, cooperation, and safety. By focusing on developing wise AI, we suggest an alternative to aligning AI with specific human values - a task fraught with conceptual and practical difficulties. Instead, wise AI systems can thoughtfully navigate complex situations, account for diverse human values, and avoid harmful actions. We discuss potential approaches to building wise AI, including benchmarking metacognitive abilities and training AI systems to employ wise reasoning. Prioritizing metacognition in AI research will lead to systems that act not only intelligently but also wisely in complex, real-world situations.
MARPLE: A Benchmark for Long-Horizon Inference
Oct 02, 2024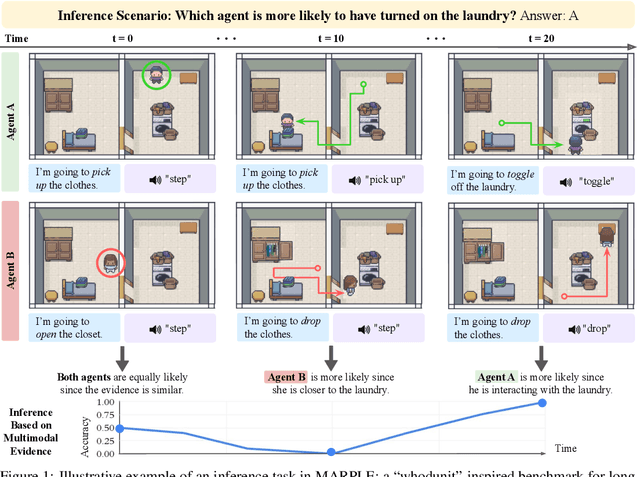

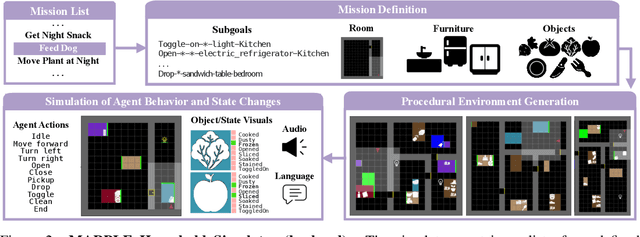

Reconstructing past events requires reasoning across long time horizons. To figure out what happened, we need to use our prior knowledge about the world and human behavior and draw inferences from various sources of evidence including visual, language, and auditory cues. We introduce MARPLE, a benchmark for evaluating long-horizon inference capabilities using multi-modal evidence. Our benchmark features agents interacting with simulated households, supporting vision, language, and auditory stimuli, as well as procedurally generated environments and agent behaviors. Inspired by classic ``whodunit'' stories, we ask AI models and human participants to infer which agent caused a change in the environment based on a step-by-step replay of what actually happened. The goal is to correctly identify the culprit as early as possible. Our findings show that human participants outperform both traditional Monte Carlo simulation methods and an LLM baseline (GPT-4) on this task. Compared to humans, traditional inference models are less robust and performant, while GPT-4 has difficulty comprehending environmental changes. We analyze what factors influence inference performance and ablate different modes of evidence, finding that all modes are valuable for performance. Overall, our experiments demonstrate that the long-horizon, multimodal inference tasks in our benchmark present a challenge to current models.
Human-like Affective Cognition in Foundation Models
Sep 19, 2024Understanding emotions is fundamental to human interaction and experience. Humans easily infer emotions from situations or facial expressions, situations from emotions, and do a variety of other affective cognition. How adept is modern AI at these inferences? We introduce an evaluation framework for testing affective cognition in foundation models. Starting from psychological theory, we generate 1,280 diverse scenarios exploring relationships between appraisals, emotions, expressions, and outcomes. We evaluate the abilities of foundation models (GPT-4, Claude-3, Gemini-1.5-Pro) and humans (N = 567) across carefully selected conditions. Our results show foundation models tend to agree with human intuitions, matching or exceeding interparticipant agreement. In some conditions, models are ``superhuman'' -- they better predict modal human judgements than the average human. All models benefit from chain-of-thought reasoning. This suggests foundation models have acquired a human-like understanding of emotions and their influence on beliefs and behavior.
To Err is Robotic: Rapid Value-Based Trial-and-Error during Deployment
Jun 22, 2024



When faced with a novel scenario, it can be hard to succeed on the first attempt. In these challenging situations, it is important to know how to retry quickly and meaningfully. Retrying behavior can emerge naturally in robots trained on diverse data, but such robot policies will typically only exhibit undirected retrying behavior and may not terminate a suboptimal approach before an unrecoverable mistake. We can improve these robot policies by instilling an explicit ability to try, evaluate, and retry a diverse range of strategies. We introduce Bellman-Guided Retrials, an algorithm that works on top of a base robot policy by monitoring the robot's progress, detecting when a change of plan is needed, and adapting the executed strategy until the robot succeeds. We start with a base policy trained on expert demonstrations of a variety of scenarios. Then, using the same expert demonstrations, we train a value function to estimate task completion. During test time, we use the value function to compare our expected rate of progress to our achieved rate of progress. If our current strategy fails to make progress at a reasonable rate, we recover the robot and sample a new strategy from the base policy while skewing it away from behaviors that have recently failed. We evaluate our method on simulated and real-world environments that contain a diverse suite of scenarios. We find that Bellman-Guided Retrials increases the average absolute success rates of base policies by more than 20% in simulation and 50% in real-world experiments, demonstrating a promising framework for instilling existing trained policies with explicit trial and error capabilities. For evaluation videos and other documentation, go to https://sites.google.com/view/to-err-robotic/home
Self-Supervised Alignment with Mutual Information: Learning to Follow Principles without Preference Labels
Apr 22, 2024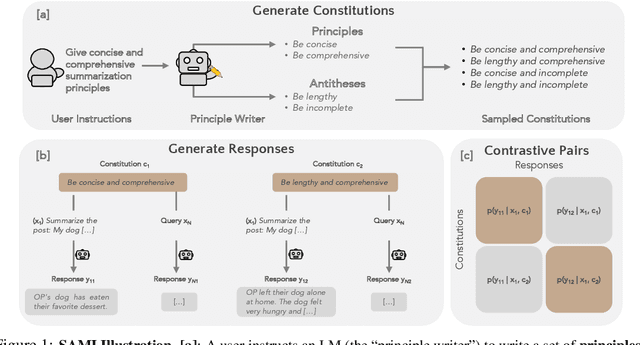
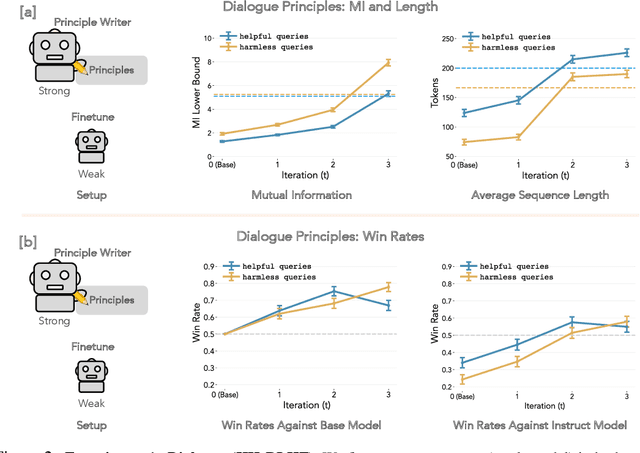

When prompting a language model (LM), users frequently expect the model to adhere to a set of behavioral principles across diverse tasks, such as producing insightful content while avoiding harmful or biased language. Instilling such principles into a model can be resource-intensive and technically challenging, generally requiring human preference labels or examples. We introduce SAMI, a method for teaching a pretrained LM to follow behavioral principles that does not require any preference labels or demonstrations. SAMI is an iterative algorithm that finetunes a pretrained LM to increase the conditional mutual information between constitutions and self-generated responses given queries from a datasest. On single-turn dialogue and summarization, a SAMI-trained mistral-7b outperforms the initial pretrained model, with win rates between 66% and 77%. Strikingly, it also surpasses an instruction-finetuned baseline (mistral-7b-instruct) with win rates between 55% and 57% on single-turn dialogue. SAMI requires a "principle writer" model; to avoid dependence on stronger models, we further evaluate aligning a strong pretrained model (mixtral-8x7b) using constitutions written by a weak instruction-finetuned model (mistral-7b-instruct). The SAMI-trained mixtral-8x7b outperforms both the initial model and the instruction-finetuned model, achieving a 65% win rate on summarization. Our results indicate that a pretrained LM can learn to follow constitutions without using preference labels, demonstrations, or human oversight.
Procedural Dilemma Generation for Evaluating Moral Reasoning in Humans and Language Models
Apr 17, 2024



As AI systems like language models are increasingly integrated into decision-making processes affecting people's lives, it's critical to ensure that these systems have sound moral reasoning. To test whether they do, we need to develop systematic evaluations. We provide a framework that uses a language model to translate causal graphs that capture key aspects of moral dilemmas into prompt templates. With this framework, we procedurally generated a large and diverse set of moral dilemmas -- the OffTheRails benchmark -- consisting of 50 scenarios and 400 unique test items. We collected moral permissibility and intention judgments from human participants for a subset of our items and compared these judgments to those from two language models (GPT-4 and Claude-2) across eight conditions. We find that moral dilemmas in which the harm is a necessary means (as compared to a side effect) resulted in lower permissibility and higher intention ratings for both participants and language models. The same pattern was observed for evitable versus inevitable harmful outcomes. However, there was no clear effect of whether the harm resulted from an agent's action versus from having omitted to act. We discuss limitations of our prompt generation pipeline and opportunities for improving scenarios to increase the strength of experimental effects.
STaR-GATE: Teaching Language Models to Ask Clarifying Questions
Mar 29, 2024When prompting language models to complete a task, users often leave important aspects unsaid. While asking questions could resolve this ambiguity (GATE; Li et al., 2023), models often struggle to ask good questions. We explore a language model's ability to self-improve (STaR; Zelikman et al., 2022) by rewarding the model for generating useful questions-a simple method we dub STaR-GATE. We generate a synthetic dataset of 25,500 unique persona-task prompts to simulate conversations between a pretrained language model-the Questioner-and a Roleplayer whose preferences are unknown to the Questioner. By asking questions, the Questioner elicits preferences from the Roleplayer. The Questioner is iteratively finetuned on questions that increase the probability of high-quality responses to the task, which are generated by an Oracle with access to the Roleplayer's latent preferences. After two iterations of self-improvement, the Questioner asks better questions, allowing it to generate responses that are preferred over responses from the initial model on 72% of tasks. Our results indicate that teaching a language model to ask better questions leads to better personalized responses.
MoCa: Measuring Human-Language Model Alignment on Causal and Moral Judgment Tasks
Oct 31, 2023



Human commonsense understanding of the physical and social world is organized around intuitive theories. These theories support making causal and moral judgments. When something bad happens, we naturally ask: who did what, and why? A rich literature in cognitive science has studied people's causal and moral intuitions. This work has revealed a number of factors that systematically influence people's judgments, such as the violation of norms and whether the harm is avoidable or inevitable. We collected a dataset of stories from 24 cognitive science papers and developed a system to annotate each story with the factors they investigated. Using this dataset, we test whether large language models (LLMs) make causal and moral judgments about text-based scenarios that align with those of human participants. On the aggregate level, alignment has improved with more recent LLMs. However, using statistical analyses, we find that LLMs weigh the different factors quite differently from human participants. These results show how curated, challenge datasets combined with insights from cognitive science can help us go beyond comparisons based merely on aggregate metrics: we uncover LLMs implicit tendencies and show to what extent these align with human intuitions.