 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Explainable AI is Causality in Disguise
Mar 30, 2026The demand for Explainable AI (XAI) has triggered an explosion of methods, producing a landscape so fragmented that we now rely on surveys of surveys. Yet, fundamental challenges persist: conflicting metrics, failed sanity checks, and unresolved debates over robustness and fairness. The only consensus on how to achieve explainability is a lack of one. This has led many to point to the absence of a ground truth for defining ``the'' correct explanation as the main culprit. This position paper posits that the persistent discord in XAI arises not from an absent ground truth but from a ground truth that exists, albeit as an elusive and challenging target: the causal model that governs the relevant system. By reframing XAI queries about data, models, or decisions as causal inquiries, we prove the necessity and sufficiency of causal models for XAI. We contend that without this causal grounding, XAI remains unmoored. Ultimately, we encourage the community to converge around advanced concept and causal discovery to escape this entrenched uncertainty.
Imagining and building wise machines: The centrality of AI metacognition
Nov 04, 2024


Recent advances in artificial intelligence (AI) have produced systems capable of increasingly sophisticated performance on cognitive tasks. However, AI systems still struggle in critical ways: unpredictable and novel environments (robustness), lack of transparency in their reasoning (explainability), challenges in communication and commitment (cooperation), and risks due to potential harmful actions (safety). We argue that these shortcomings stem from one overarching failure: AI systems lack wisdom. Drawing from cognitive and social sciences, we define wisdom as the ability to navigate intractable problems - those that are ambiguous, radically uncertain, novel, chaotic, or computationally explosive - through effective task-level and metacognitive strategies. While AI research has focused on task-level strategies, metacognition - the ability to reflect on and regulate one's thought processes - is underdeveloped in AI systems. In humans, metacognitive strategies such as recognizing the limits of one's knowledge, considering diverse perspectives, and adapting to context are essential for wise decision-making. We propose that integrating metacognitive capabilities into AI systems is crucial for enhancing their robustness, explainability, cooperation, and safety. By focusing on developing wise AI, we suggest an alternative to aligning AI with specific human values - a task fraught with conceptual and practical difficulties. Instead, wise AI systems can thoughtfully navigate complex situations, account for diverse human values, and avoid harmful actions. We discuss potential approaches to building wise AI, including benchmarking metacognitive abilities and training AI systems to employ wise reasoning. Prioritizing metacognition in AI research will lead to systems that act not only intelligently but also wisely in complex, real-world situations.
Prospector Heads: Generalized Feature Attribution for Large Models & Data
Feb 18, 2024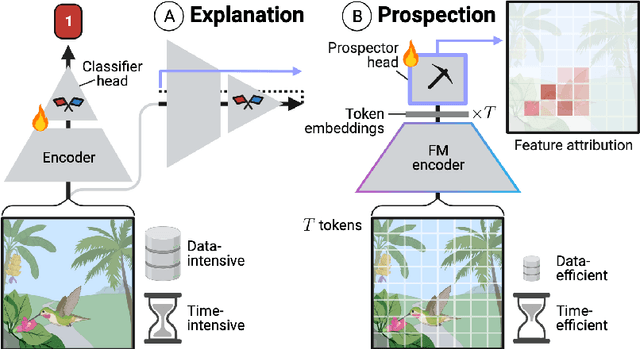
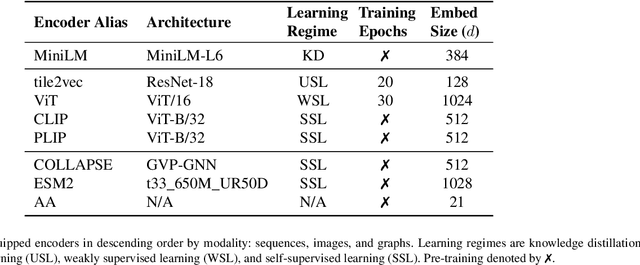
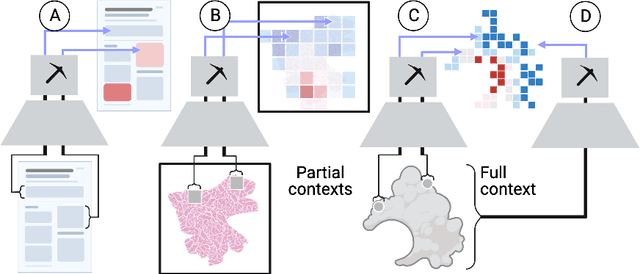

Feature attribution, the ability to localize regions of the input data that are relevant for classification, is an important capability for machine learning models in scientific and biomedical domains. Current methods for feature attribution, which rely on "explaining" the predictions of end-to-end classifiers, suffer from imprecise feature localization and are inadequate for use with small sample sizes and high-dimensional datasets due to computational challenges. We introduce prospector heads, an efficient and interpretable alternative to explanation-based methods for feature attribution that can be applied to any encoder and any data modality. Prospector heads generalize across modalities through experiments on sequences (text), images (pathology), and graphs (protein structures), outperforming baseline attribution methods by up to 49 points in mean localization AUPRC. We also demonstrate how prospector heads enable improved interpretation and discovery of class-specific patterns in the input data. Through their high performance, flexibility, and generalizability, prospectors provide a framework for improving trust and transparency for machine learning models in complex domains.
Causal Adversarial Perturbations for Individual Fairness and Robustness in Heterogeneous Data Spaces
Aug 17, 2023

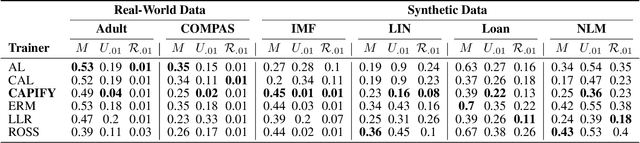
As responsible AI gains importance in machine learning algorithms, properties such as fairness, adversarial robustness, and causality have received considerable attention in recent years. However, despite their individual significance, there remains a critical gap in simultaneously exploring and integrating these properties. In this paper, we propose a novel approach that examines the relationship between individual fairness, adversarial robustness, and structural causal models in heterogeneous data spaces, particularly when dealing with discrete sensitive attributes. We use causal structural models and sensitive attributes to create a fair metric and apply it to measure semantic similarity among individuals. By introducing a novel causal adversarial perturbation and applying adversarial training, we create a new regularizer that combines individual fairness, causality, and robustness in the classifier. Our method is evaluated on both real-world and synthetic datasets, demonstrating its effectiveness in achieving an accurate classifier that simultaneously exhibits fairness, adversarial robustness, and causal awareness.
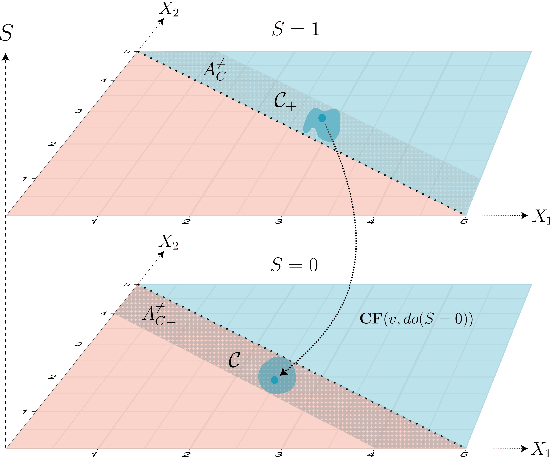
Robustness Implies Fairness in Causal Algorithmic Recourse
Feb 11, 2023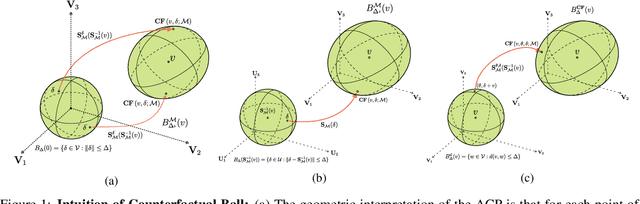


Algorithmic recourse aims to disclose the inner workings of the black-box decision process in situations where decisions have significant consequences, by providing recommendations to empower beneficiaries to achieve a more favorable outcome. To ensure an effective remedy, suggested interventions must not only be low-cost but also robust and fair. This goal is accomplished by providing similar explanations to individuals who are alike. This study explores the concept of individual fairness and adversarial robustness in causal algorithmic recourse and addresses the challenge of achieving both. To resolve the challenges, we propose a new framework for defining adversarially robust recourse. The new setting views the protected feature as a pseudometric and demonstrates that individual fairness is a special case of adversarial robustness. Finally, we introduce the fair robust recourse problem to achieve both desirable properties and show how it can be satisfied both theoretically and empirically.
On the Relationship Between Explanation and Prediction: A Causal View
Dec 20, 2022



Explainability has become a central requirement for the development, deployment, and adoption of machine learning (ML) models and we are yet to understand what explanation methods can and cannot do. Several factors such as data, model prediction, hyperparameters used in training the model, and random initialization can all influence downstream explanations. While previous work empirically hinted that explanations (E) may have little relationship with the prediction (Y), there is a lack of conclusive study to quantify this relationship. Our work borrows tools from causal inference to systematically assay this relationship. More specifically, we measure the relationship between E and Y by measuring the treatment effect when intervening on their causal ancestors (hyperparameters) (inputs to generate saliency-based Es or Ys). We discover that Y's relative direct influence on E follows an odd pattern; the influence is higher in the lowest-performing models than in mid-performing models, and it then decreases in the top-performing models. We believe our work is a promising first step towards providing better guidance for practitioners who can make more informed decisions in utilizing these explanations by knowing what factors are at play and how they relate to their end task.
On the Adversarial Robustness of Causal Algorithmic Recourse
Dec 21, 2021
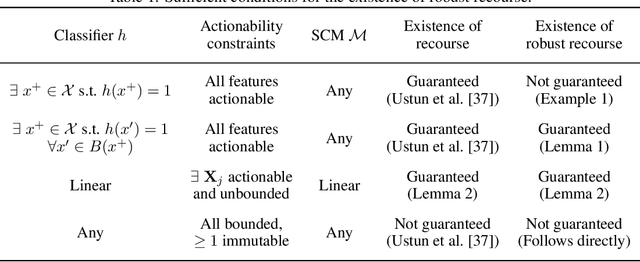
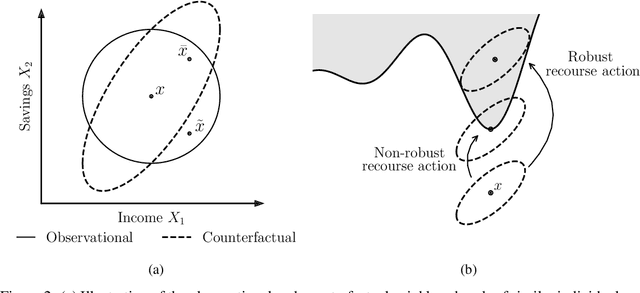
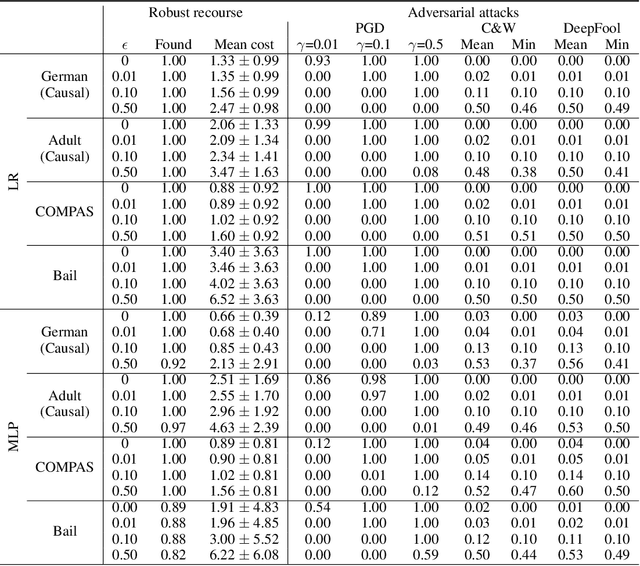
Algorithmic recourse seeks to provide actionable recommendations for individuals to overcome unfavorable outcomes made by automated decision-making systems. Recourse recommendations should ideally be robust to reasonably small uncertainty in the features of the individual seeking recourse. In this work, we formulate the adversarially robust recourse problem and show that recourse methods offering minimally costly recourse fail to be robust. We then present methods for generating adversarially robust recourse in the linear and in the differentiable case. To ensure that recourse is robust, individuals are asked to make more effort than they would have otherwise had to. In order to shift part of the burden of robustness from the decision-subject to the decision-maker, we propose a model regularizer that encourages the additional cost of seeking robust recourse to be low. We show that classifiers trained with our proposed model regularizer, which penalizes relying on unactionable features for prediction, offer potentially less effortful recourse.
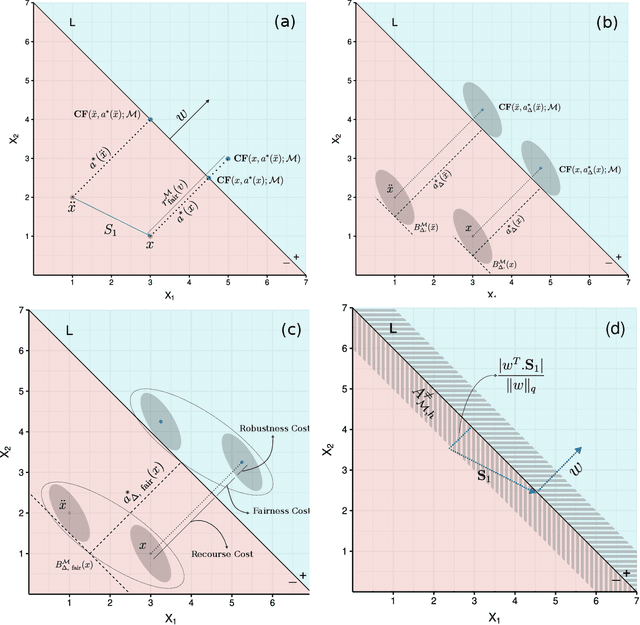
On the Fairness of Causal Algorithmic Recourse
Oct 14, 2020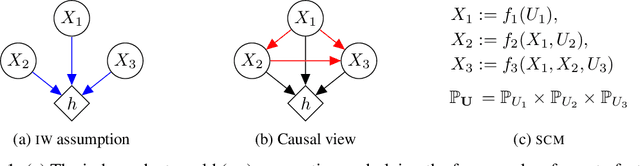
While many recent works have studied the problem of algorithmic fairness from the perspective of predictions, here we investigate the fairness of recourse actions recommended to individuals to recover from an unfavourable classification. To this end, we propose two new fairness criteria at the group and individual level which---unlike prior work on equalising the average distance from the decision boundary across protected groups---are based on a causal framework that explicitly models relationships between input features, thereby allowing to capture downstream effects of recourse actions performed in the physical world. We explore how our criteria relate to others, such as counterfactual fairness, and show that fairness of recourse is complementary to fairness of prediction. We then investigate how to enforce fair recourse in the training of the classifier. Finally, we discuss whether fairness violations in the data generating process revealed by our criteria may be better addressed by societal interventions and structural changes to the system, as opposed to constraints on the classifier.
Scaling Guarantees for Nearest Counterfactual Explanations
Oct 10, 2020
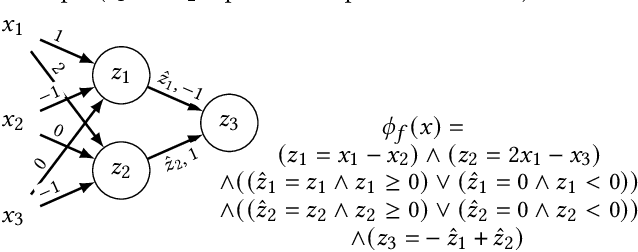
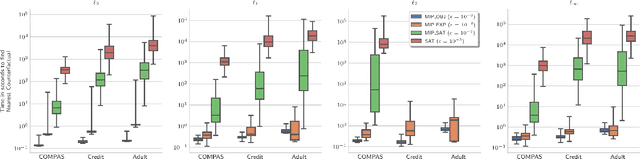
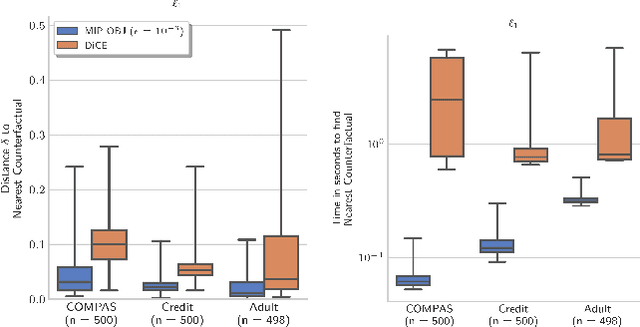
Counterfactual explanations (CFE) are being widely used to explain algorithmic decisions, especially in consequential decision-making contexts (e.g., loan approval or pretrial bail). In this context, CFEs aim to provide individuals affected by an algorithmic decision with the most similar individual (i.e., nearest individual) with a different outcome. However, while an increasing number of works propose algorithms to compute CFEs, such approaches either lack in optimality of distance (i.e., they do not return the nearest individual) and perfect coverage (i.e., they do not provide a CFE for all individuals); or they cannot handle complex models, such as neural networks. In this work, we provide a framework based on Mixed-Integer Programming (MIP) to compute nearest counterfactual explanations with provable guarantees and with runtimes comparable to gradient-based approaches. Our experiments on the Adult, COMPAS, and Credit datasets show that, in contrast with previous methods, our approach allows for efficiently computing diverse CFEs with both distance guarantees and perfect coverage.
A survey of algorithmic recourse: definitions, formulations, solutions, and prospects
Oct 08, 2020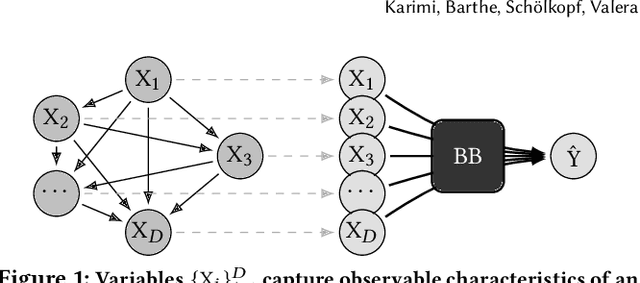
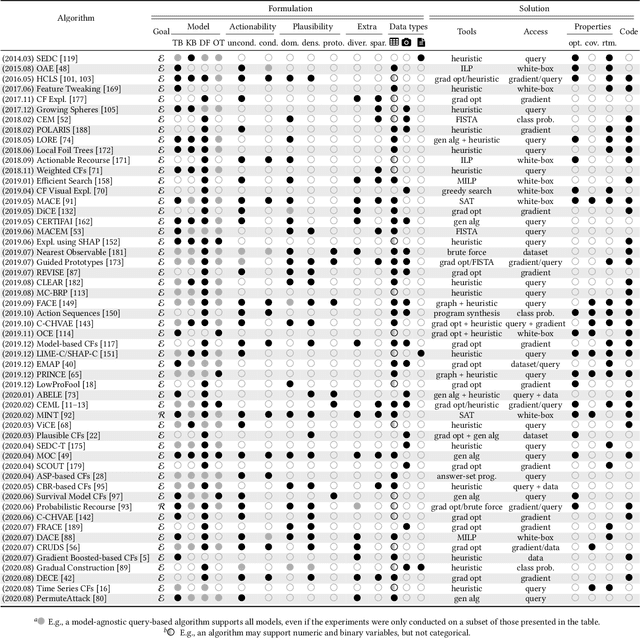
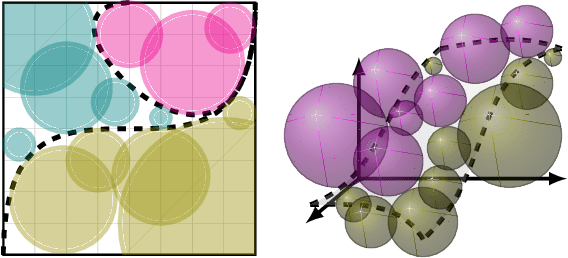
Machine learning is increasingly used to inform decision-making in sensitive situations where decisions have consequential effects on individuals' lives. In these settings, in addition to requiring models to be accurate and robust, socially relevant values such as fairness, privacy, accountability, and explainability play an important role for the adoption and impact of said technologies. In this work, we focus on algorithmic recourse, which is concerned with providing explanations and recommendations to individuals who are unfavourably treated by automated decision-making systems. We first perform an extensive literature review, and align the efforts of many authors by presenting unified definitions, formulations, and solutions to recourse. Then, we provide an overview of the prospective research directions towards which the community may engage, challenging existing assumptions and making explicit connections to other ethical challenges such as security, privacy, and fairness.