 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHellinger Multimodal Variational Autoencoders
Jan 10, 2026Multimodal variational autoencoders (VAEs) are widely used for weakly supervised generative learning with multiple modalities. Predominant methods aggregate unimodal inference distributions using either a product of experts (PoE), a mixture of experts (MoE), or their combinations to approximate the joint posterior. In this work, we revisit multimodal inference through the lens of probabilistic opinion pooling, an optimization-based approach. We start from Hölder pooling with $α=0.5$, which corresponds to the unique symmetric member of the $α\text{-divergence}$ family, and derive a moment-matching approximation, termed Hellinger. We then leverage such an approximation to propose HELVAE, a multimodal VAE that avoids sub-sampling, yielding an efficient yet effective model that: (i) learns more expressive latent representations as additional modalities are observed; and (ii) empirically achieves better trade-offs between generative coherence and quality, outperforming state-of-the-art multimodal VAE models.
Bridging Fairness and Explainability: Can Input-Based Explanations Promote Fairness in Hate Speech Detection?
Sep 26, 2025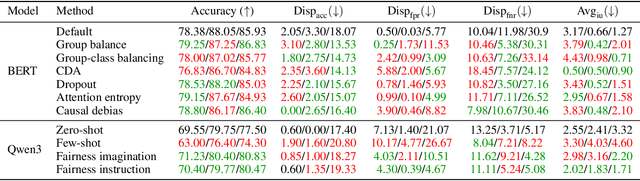
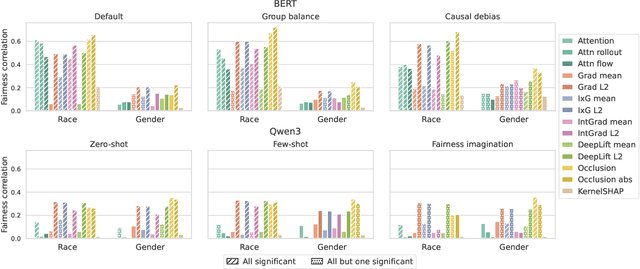
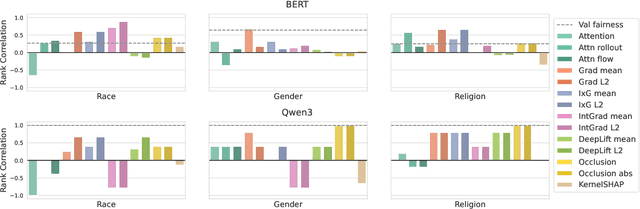

Natural language processing (NLP) models often replicate or amplify social bias from training data, raising concerns about fairness. At the same time, their black-box nature makes it difficult for users to recognize biased predictions and for developers to effectively mitigate them. While some studies suggest that input-based explanations can help detect and mitigate bias, others question their reliability in ensuring fairness. Existing research on explainability in fair NLP has been predominantly qualitative, with limited large-scale quantitative analysis. In this work, we conduct the first systematic study of the relationship between explainability and fairness in hate speech detection, focusing on both encoder- and decoder-only models. We examine three key dimensions: (1) identifying biased predictions, (2) selecting fair models, and (3) mitigating bias during model training. Our findings show that input-based explanations can effectively detect biased predictions and serve as useful supervision for reducing bias during training, but they are unreliable for selecting fair models among candidates.
Accept or Deny? Evaluating LLM Fairness and Performance in Loan Approval across Table-to-Text Serialization Approaches
Aug 29, 2025



Large Language Models (LLMs) are increasingly employed in high-stakes decision-making tasks, such as loan approvals. While their applications expand across domains, LLMs struggle to process tabular data, ensuring fairness and delivering reliable predictions. In this work, we assess the performance and fairness of LLMs on serialized loan approval datasets from three geographically distinct regions: Ghana, Germany, and the United States. Our evaluation focuses on the model's zero-shot and in-context learning (ICL) capabilities. Our results reveal that the choice of serialization (Serialization refers to the process of converting tabular data into text formats suitable for processing by LLMs.) format significantly affects both performance and fairness in LLMs, with certain formats such as GReat and LIFT yielding higher F1 scores but exacerbating fairness disparities. Notably, while ICL improved model performance by 4.9-59.6% relative to zero-shot baselines, its effect on fairness varied considerably across datasets. Our work underscores the importance of effective tabular data representation methods and fairness-aware models to improve the reliability of LLMs in financial decision-making.
Towards Reasonable Concept Bottleneck Models
Jun 05, 2025In this paper, we propose $\textbf{C}$oncept $\textbf{REA}$soning $\textbf{M}$odels (CREAM), a novel family of Concept Bottleneck Models (CBMs) that: (i) explicitly encodes concept-concept (${\texttt{C-C}}$) and concept-task (${\texttt{C$\rightarrow$Y}}$) relationships to enforce a desired model reasoning; and (ii) use a regularized side-channel to achieve competitive task performance, while keeping high concept importance. Specifically, CREAM architecturally embeds (bi)directed concept-concept, and concept to task relationships specified by a human expert, while severing undesired information flows (e.g., to handle mutually exclusive concepts). Moreover, CREAM integrates a black-box side-channel that is regularized to encourage task predictions to be grounded in the relevant concepts, thereby utilizing the side-channel only when necessary to enhance performance. Our experiments show that: (i) CREAM mainly relies on concepts while achieving task performance on par with black-box models; and (ii) the embedded ${\texttt{C-C}}$ and ${\texttt{C$\rightarrow$Y}}$ relationships ease model interventions and mitigate concept leakage.
Per-Domain Generalizing Policies: On Validation Instances and Scaling Behavior
May 01, 2025Recent work has shown that successful per-domain generalizing action policies can be learned. Scaling behavior, from small training instances to large test instances, is the key objective; and the use of validation instances larger than training instances is one key to achieve it. Prior work has used fixed validation sets. Here, we introduce a method generating the validation set dynamically, on the fly, increasing instance size so long as informative and feasible.We also introduce refined methodology for evaluating scaling behavior, generating test instances systematically to guarantee a given confidence in coverage performance for each instance size. In experiments, dynamic validation improves scaling behavior of GNN policies in all 9 domains used.
Hyper-Transforming Latent Diffusion Models
Apr 24, 2025We introduce a novel generative framework for functions by integrating Implicit Neural Representations (INRs) and Transformer-based hypernetworks into latent variable models. Unlike prior approaches that rely on MLP-based hypernetworks with scalability limitations, our method employs a Transformer-based decoder to generate INR parameters from latent variables, addressing both representation capacity and computational efficiency. Our framework extends latent diffusion models (LDMs) to INR generation by replacing standard decoders with a Transformer-based hypernetwork, which can be trained either from scratch or via hyper-transforming-a strategy that fine-tunes only the decoder while freezing the pre-trained latent space. This enables efficient adaptation of existing generative models to INR-based representations without requiring full retraining.
A Causal Framework to Measure and Mitigate Non-binary Treatment Discrimination
Mar 28, 2025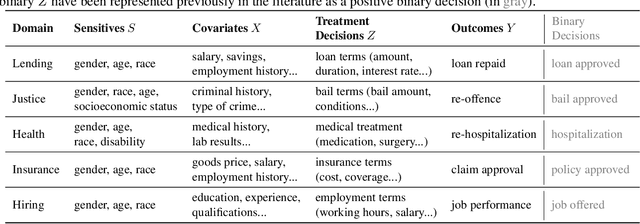
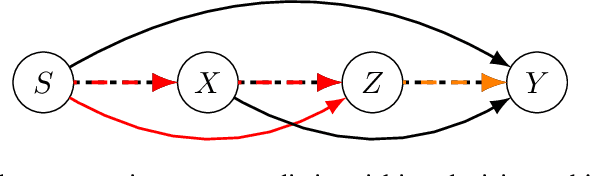

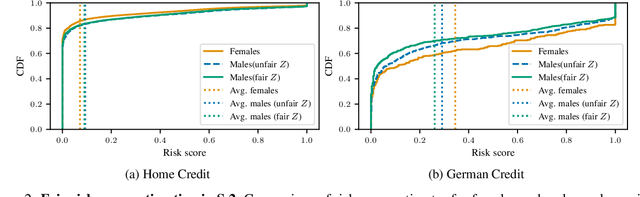
Fairness studies of algorithmic decision-making systems often simplify complex decision processes, such as bail or loan approvals, into binary classification tasks. However, these approaches overlook that such decisions are not inherently binary (e.g., approve or not approve bail or loan); they also involve non-binary treatment decisions (e.g., bail conditions or loan terms) that can influence the downstream outcomes (e.g., loan repayment or reoffending). In this paper, we argue that non-binary treatment decisions are integral to the decision process and controlled by decision-makers and, therefore, should be central to fairness analyses in algorithmic decision-making. We propose a causal framework that extends fairness analyses and explicitly distinguishes between decision-subjects' covariates and the treatment decisions. This specification allows decision-makers to use our framework to (i) measure treatment disparity and its downstream effects in historical data and, using counterfactual reasoning, (ii) mitigate the impact of past unfair treatment decisions when automating decision-making. We use our framework to empirically analyze four widely used loan approval datasets to reveal potential disparity in non-binary treatment decisions and their discriminatory impact on outcomes, highlighting the need to incorporate treatment decisions in fairness assessments. Moreover, by intervening in treatment decisions, we show that our framework effectively mitigates treatment discrimination from historical data to ensure fair risk score estimation and (non-binary) decision-making processes that benefit all stakeholders.
DeCaFlow: A Deconfounding Causal Generative Model
Mar 19, 2025Causal generative models (CGMs) have recently emerged as capable approaches to simulate the causal mechanisms generating our observations, enabling causal inference. Unfortunately, existing approaches either are overly restrictive, assuming the absence of hidden confounders, or lack generality, being tailored to a particular query and graph. In this work, we introduce DeCaFlow, a CGM that accounts for hidden confounders in a single amortized training process using only observational data and the causal graph. Importantly, DeCaFlow can provably identify all causal queries with a valid adjustment set or sufficiently informative proxy variables. Remarkably, for the first time to our knowledge, we show that a confounded counterfactual query is identifiable, and thus solvable by DeCaFlow, as long as its interventional counterpart is as well. Our empirical results on diverse settings (including the Ecoli70 dataset, with 3 independent hidden confounders, tens of observed variables and hundreds of causal queries) show that DeCaFlow outperforms existing approaches, while demonstrating its out-of-the-box flexibility.
COPA: Comparing the Incomparable to Explore the Pareto Front
Mar 18, 2025



In machine learning (ML), it is common to account for multiple objectives when, e.g., selecting a model to deploy. However, it is often unclear how one should compare, aggregate and, ultimately, trade-off these objectives, as they might be measured in different units or scales. For example, when deploying large language models (LLMs), we might not only care about their performance, but also their CO2 consumption. In this work, we investigate how objectives can be sensibly compared and aggregated to navigate their Pareto front. To do so, we propose to make incomparable objectives comparable via their CDFs, approximated by their relative rankings. This allows us to aggregate them while matching user-specific preferences, allowing practitioners to meaningfully navigate and search for models in the Pareto front. We demonstrate the potential impact of our methodology in diverse areas such as LLM selection, domain generalization, and AutoML benchmarking, where classical ways to aggregate and normalize objectives fail.
A Practical Approach to Causal Inference over Time
Oct 14, 2024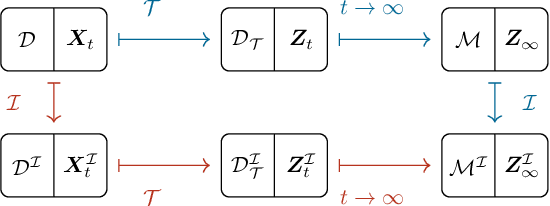
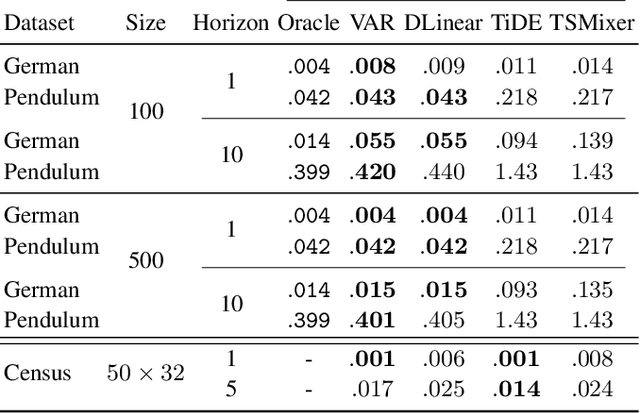
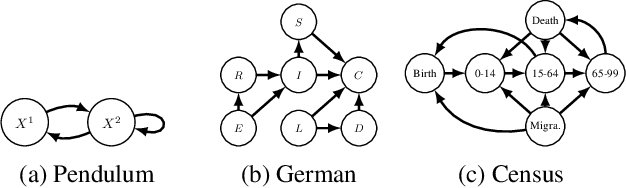
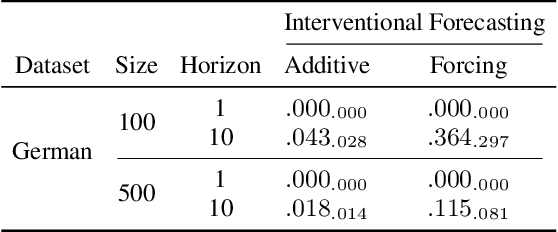
In this paper, we focus on estimating the causal effect of an intervention over time on a dynamical system. To that end, we formally define causal interventions and their effects over time on discrete-time stochastic processes (DSPs). Then, we show under which conditions the equilibrium states of a DSP, both before and after a causal intervention, can be captured by a structural causal model (SCM). With such an equivalence at hand, we provide an explicit mapping from vector autoregressive models (VARs), broadly applied in econometrics, to linear, but potentially cyclic and/or affected by unmeasured confounders, SCMs. The resulting causal VAR framework allows us to perform causal inference over time from observational time series data. Our experiments on synthetic and real-world datasets show that the proposed framework achieves strong performance in terms of observational forecasting while enabling accurate estimation of the causal effect of interventions on dynamical systems. We demonstrate, through a case study, the potential practical questions that can be addressed using the proposed causal VAR framework.