 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval with Multiple Query Vectors through Anomalous Pattern Detection
May 03, 2026A classical vector retrieval problem typically considers a \emph{single} query embedding vector as input and retrieves the most similar embedding vectors from a vector database. However, complex reasoning and retrieval tasks frequently require \emph{multiple query vectors}, rather than a single one. In this work, we propose a retrieval method that considers multiple query vectors simultaneously and retrieves the most relevant vectors from the database using concepts from anomalous pattern detection. Specifically, our approach leverages a set of query vectors $Q$ (with $|Q|\geq 1$), and identifies the subset of vector dimensions within $Q$ that standout (anomalous) from the rest of dimensions. Next, we scan the vector database to retrieve the set of vectors that are also anomalous across the previously identified vector dimensions and return them as our retrieved set of vectors. We validate our approach on two image datasets, a text dataset, and a tabular dataset. Overall, we observe that, across most datasets, larger query sets lead to improved retrieval performance. The improvement is most pronounced when increasing the query sets from 1 to 8, while the gains become smaller beyond that.
Localizing Persona Representations in LLMs
May 30, 2025We present a study on how and where personas -- defined by distinct sets of human characteristics, values, and beliefs -- are encoded in the representation space of large language models (LLMs). Using a range of dimension reduction and pattern recognition methods, we first identify the model layers that show the greatest divergence in encoding these representations. We then analyze the activations within a selected layer to examine how specific personas are encoded relative to others, including their shared and distinct embedding spaces. We find that, across multiple pre-trained decoder-only LLMs, the analyzed personas show large differences in representation space only within the final third of the decoder layers. We observe overlapping activations for specific ethical perspectives -- such as moral nihilism and utilitarianism -- suggesting a degree of polysemy. In contrast, political ideologies like conservatism and liberalism appear to be represented in more distinct regions. These findings help to improve our understanding of how LLMs internally represent information and can inform future efforts in refining the modulation of specific human traits in LLM outputs. Warning: This paper includes potentially offensive sample statements.
Robustness and Cybersecurity in the EU Artificial Intelligence Act
Feb 22, 2025The EU Artificial Intelligence Act (AIA) establishes different legal principles for different types of AI systems. While prior work has sought to clarify some of these principles, little attention has been paid to robustness and cybersecurity. This paper aims to fill this gap. We identify legal challenges and shortcomings in provisions related to robustness and cybersecurity for high-risk AI systems (Art. 15 AIA) and general-purpose AI models (Art. 55 AIA). We show that robustness and cybersecurity demand resilience against performance disruptions. Furthermore, we assess potential challenges in implementing these provisions in light of recent advancements in the machine learning (ML) literature. Our analysis informs efforts to develop harmonized standards, guidelines by the European Commission, as well as benchmarks and measurement methodologies under Art. 15(2) AIA. With this, we seek to bridge the gap between legal terminology and ML research, fostering a better alignment between research and implementation efforts.
Weakly Supervised Detection of Hallucinations in LLM Activations
Dec 05, 2023



We propose an auditing method to identify whether a large language model (LLM) encodes patterns such as hallucinations in its internal states, which may propagate to downstream tasks. We introduce a weakly supervised auditing technique using a subset scanning approach to detect anomalous patterns in LLM activations from pre-trained models. Importantly, our method does not need knowledge of the type of patterns a-priori. Instead, it relies on a reference dataset devoid of anomalies during testing. Further, our approach enables the identification of pivotal nodes responsible for encoding these patterns, which may offer crucial insights for fine-tuning specific sub-networks for bias mitigation. We introduce two new scanning methods to handle LLM activations for anomalous sentences that may deviate from the expected distribution in either direction. Our results confirm prior findings of BERT's limited internal capacity for encoding hallucinations, while OPT appears capable of encoding hallucination information internally. Importantly, our scanning approach, without prior exposure to false statements, performs comparably to a fully supervised out-of-distribution classifier.
Designing Long-term Group Fair Policies in Dynamical Systems
Nov 21, 2023Neglecting the effect that decisions have on individuals (and thus, on the underlying data distribution) when designing algorithmic decision-making policies may increase inequalities and unfairness in the long term - even if fairness considerations were taken in the policy design process. In this paper, we propose a novel framework for achieving long-term group fairness in dynamical systems, in which current decisions may affect an individual's features in the next step, and thus, future decisions. Specifically, our framework allows us to identify a time-independent policy that converges, if deployed, to the targeted fair stationary state of the system in the long term, independently of the initial data distribution. We model the system dynamics with a time-homogeneous Markov chain and optimize the policy leveraging the Markov chain convergence theorem to ensure unique convergence. We provide examples of different targeted fair states of the system, encompassing a range of long-term goals for society and policymakers. Furthermore, we show how our approach facilitates the evaluation of different long-term targets by examining their impact on the group-conditional population distribution in the long term and how it evolves until convergence.
Don't Throw it Away! The Utility of Unlabeled Data in Fair Decision Making
May 11, 2022
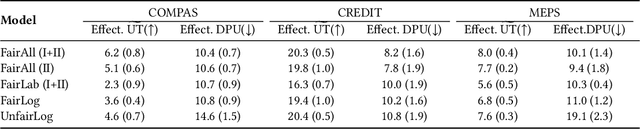
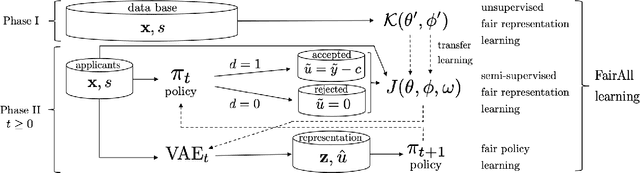

Decision making algorithms, in practice, are often trained on data that exhibits a variety of biases. Decision-makers often aim to take decisions based on some ground-truth target that is assumed or expected to be unbiased, i.e., equally distributed across socially salient groups. In many practical settings, the ground-truth cannot be directly observed, and instead, we have to rely on a biased proxy measure of the ground-truth, i.e., biased labels, in the data. In addition, data is often selectively labeled, i.e., even the biased labels are only observed for a small fraction of the data that received a positive decision. To overcome label and selection biases, recent work proposes to learn stochastic, exploring decision policies via i) online training of new policies at each time-step and ii) enforcing fairness as a constraint on performance. However, the existing approach uses only labeled data, disregarding a large amount of unlabeled data, and thereby suffers from high instability and variance in the learned decision policies at different times. In this paper, we propose a novel method based on a variational autoencoder for practical fair decision-making. Our method learns an unbiased data representation leveraging both labeled and unlabeled data and uses the representations to learn a policy in an online process. Using synthetic data, we empirically validate that our method converges to the optimal (fair) policy according to the ground-truth with low variance. In real-world experiments, we further show that our training approach not only offers a more stable learning process but also yields policies with higher fairness as well as utility than previous approaches.
VACA: Design of Variational Graph Autoencoders for Interventional and Counterfactual Queries
Oct 27, 2021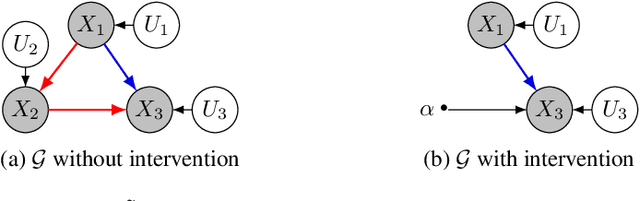
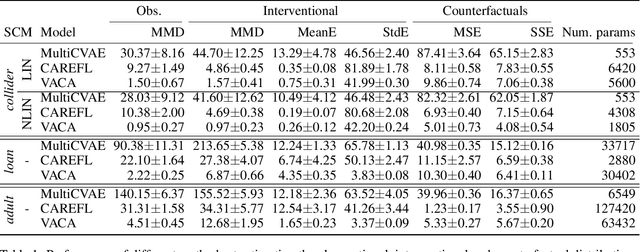
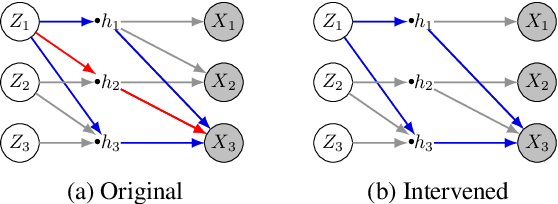

In this paper, we introduce VACA, a novel class of variational graph autoencoders for causal inference in the absence of hidden confounders, when only observational data and the causal graph are available. Without making any parametric assumptions, VACA mimics the necessary properties of a Structural Causal Model (SCM) to provide a flexible and practical framework for approximating interventions (do-operator) and abduction-action-prediction steps. As a result, and as shown by our empirical results, VACA accurately approximates the interventional and counterfactual distributions on diverse SCMs. Finally, we apply VACA to evaluate counterfactual fairness in fair classification problems, as well as to learn fair classifiers without compromising performance.