 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Steerability 360: A Toolkit for Steering Large Language Models
Mar 08, 2026The AI Steerability 360 toolkit is an extensible, open-source Python library for steering LLMs. Steering abstractions are designed around four model control surfaces: input (modification of the prompt), structural (modification of the model's weights or architecture), state (modification of the model's activations and attentions), and output (modification of the decoding or generation process). Steering methods exert control on the model through a common interface, termed a steering pipeline, which additionally allows for the composition of multiple steering methods. Comprehensive evaluation and comparison of steering methods/pipelines is facilitated by use case classes (for defining tasks) and a benchmark class (for performance comparison on a given task). The functionality provided by the toolkit significantly lowers the barrier to developing and comprehensively evaluating steering methods. The toolkit is Hugging Face native and is released under an Apache 2.0 license at https://github.com/IBM/AISteer360.
The Effectiveness of Approximate Regularized Replay for Efficient Supervised Fine-Tuning of Large Language Models
Dec 26, 2025Although parameter-efficient fine-tuning methods, such as LoRA, only modify a small subset of parameters, they can have a significant impact on the model. Our instruction-tuning experiments show that LoRA-based supervised fine-tuning can catastrophically degrade model capabilities, even when trained on very small datasets for relatively few steps. With that said, we demonstrate that while the most straightforward approach (that is likely the most used in practice) fails spectacularly, small tweaks to the training procedure with very little overhead can virtually eliminate the problem. Particularly, in this paper we consider a regularized approximate replay approach which penalizes KL divergence with respect to the initial model and interleaves in data for next token prediction from a different, yet similar, open access corpus to what was used in pre-training. When applied to Qwen instruction-tuned models, we find that this recipe preserves general knowledge in the model without hindering plasticity to new tasks by adding a modest amount of computational overhead.
ICX360: In-Context eXplainability 360 Toolkit
Nov 14, 2025Large Language Models (LLMs) have become ubiquitous in everyday life and are entering higher-stakes applications ranging from summarizing meeting transcripts to answering doctors' questions. As was the case with earlier predictive models, it is crucial that we develop tools for explaining the output of LLMs, be it a summary, list, response to a question, etc. With these needs in mind, we introduce In-Context Explainability 360 (ICX360), an open-source Python toolkit for explaining LLMs with a focus on the user-provided context (or prompts in general) that are fed to the LLMs. ICX360 contains implementations for three recent tools that explain LLMs using both black-box and white-box methods (via perturbations and gradients respectively). The toolkit, available at https://github.com/IBM/ICX360, contains quick-start guidance materials as well as detailed tutorials covering use cases such as retrieval augmented generation, natural language generation, and jailbreaking.
Generate, Evaluate, Iterate: Synthetic Data for Human-in-the-Loop Refinement of LLM Judges
Nov 06, 2025The LLM-as-a-judge paradigm enables flexible, user-defined evaluation, but its effectiveness is often limited by the scarcity of diverse, representative data for refining criteria. We present a tool that integrates synthetic data generation into the LLM-as-a-judge workflow, empowering users to create tailored and challenging test cases with configurable domains, personas, lengths, and desired outcomes, including borderline cases. The tool also supports AI-assisted inline editing of existing test cases. To enhance transparency and interpretability, it reveals the prompts and explanations behind each generation. In a user study (N=24), 83% of participants preferred the tool over manually creating or selecting test cases, as it allowed them to rapidly generate diverse synthetic data without additional workload. The generated synthetic data proved as effective as hand-crafted data for both refining evaluation criteria and aligning with human preferences. These findings highlight synthetic data as a promising alternative, particularly in contexts where efficiency and scalability are critical.
Language Models Coupled with Metacognition Can Outperform Reasoning Models
Aug 25, 2025Large language models (LLMs) excel in speed and adaptability across various reasoning tasks, but they often struggle when strict logic or constraint enforcement is required. In contrast, Large Reasoning Models (LRMs) are specifically designed for complex, step-by-step reasoning, although they come with significant computational costs and slower inference times. To address these trade-offs, we employ and generalize the SOFAI (Slow and Fast AI) cognitive architecture into SOFAI-LM, which coordinates a fast LLM with a slower but more powerful LRM through metacognition. The metacognitive module actively monitors the LLM's performance and provides targeted, iterative feedback with relevant examples. This enables the LLM to progressively refine its solutions without requiring the need for additional model fine-tuning. Extensive experiments on graph coloring and code debugging problems demonstrate that our feedback-driven approach significantly enhances the problem-solving capabilities of the LLM. In many instances, it achieves performance levels that match or even exceed those of standalone LRMs while requiring considerably less time. Additionally, when the LLM and feedback mechanism alone are insufficient, we engage the LRM by providing appropriate information collected during the LLM's feedback loop, tailored to the specific characteristics of the problem domain and leads to improved overall performance. Evaluations on two contrasting domains: graph coloring, requiring globally consistent solutions, and code debugging, demanding localized fixes, demonstrate that SOFAI-LM enables LLMs to match or outperform standalone LRMs in accuracy while maintaining significantly lower inference time.
Localizing Persona Representations in LLMs
May 30, 2025We present a study on how and where personas -- defined by distinct sets of human characteristics, values, and beliefs -- are encoded in the representation space of large language models (LLMs). Using a range of dimension reduction and pattern recognition methods, we first identify the model layers that show the greatest divergence in encoding these representations. We then analyze the activations within a selected layer to examine how specific personas are encoded relative to others, including their shared and distinct embedding spaces. We find that, across multiple pre-trained decoder-only LLMs, the analyzed personas show large differences in representation space only within the final third of the decoder layers. We observe overlapping activations for specific ethical perspectives -- such as moral nihilism and utilitarianism -- suggesting a degree of polysemy. In contrast, political ideologies like conservatism and liberalism appear to be represented in more distinct regions. These findings help to improve our understanding of how LLMs internally represent information and can inform future efforts in refining the modulation of specific human traits in LLM outputs. Warning: This paper includes potentially offensive sample statements.
Granite Guardian
Dec 10, 2024



We introduce the Granite Guardian models, a suite of safeguards designed to provide risk detection for prompts and responses, enabling safe and responsible use in combination with any large language model (LLM). These models offer comprehensive coverage across multiple risk dimensions, including social bias, profanity, violence, sexual content, unethical behavior, jailbreaking, and hallucination-related risks such as context relevance, groundedness, and answer relevance for retrieval-augmented generation (RAG). Trained on a unique dataset combining human annotations from diverse sources and synthetic data, Granite Guardian models address risks typically overlooked by traditional risk detection models, such as jailbreaks and RAG-specific issues. With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space. Released as open-source, Granite Guardian aims to promote responsible AI development across the community. https://github.com/ibm-granite/granite-guardian
Evaluating the Prompt Steerability of Large Language Models
Nov 19, 2024



Building pluralistic AI requires designing models that are able to be shaped to represent a wide range of value systems and cultures. Achieving this requires first being able to evaluate the degree to which a given model is capable of reflecting various personas. To this end, we propose a benchmark for evaluating the steerability of model personas as a function of prompting. Our design is based on a formal definition of prompt steerability, which analyzes the degree to which a model's joint behavioral distribution can be shifted from its baseline behavior. By defining steerability indices and inspecting how these indices change as a function of steering effort, we can estimate the steerability of a model across various persona dimensions and directions. Our benchmark reveals that the steerability of many current models is limited -- due to both a skew in their baseline behavior and an asymmetry in their steerability across many persona dimensions. We release an implementation of our benchmark at https://github.com/IBM/prompt-steering.
Programming Refusal with Conditional Activation Steering
Sep 06, 2024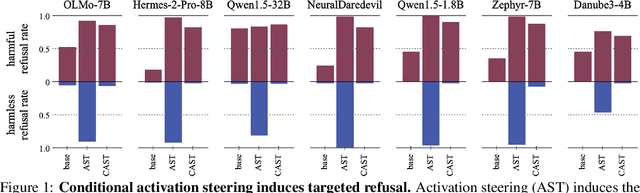



LLMs have shown remarkable capabilities, but precisely controlling their response behavior remains challenging. Existing activation steering methods alter LLM behavior indiscriminately, limiting their practical applicability in settings where selective responses are essential, such as content moderation or domain-specific assistants. In this paper, we propose Conditional Activation Steering (CAST), which analyzes LLM activation patterns during inference to selectively apply or withhold activation steering based on the input context. Our method is based on the observation that different categories of prompts activate distinct patterns in the model's hidden states. Using CAST, one can systematically control LLM behavior with rules like "if input is about hate speech or adult content, then refuse" or "if input is not about legal advice, then refuse." This allows for selective modification of responses to specific content while maintaining normal responses to other content, all without requiring weight optimization. We release an open-source implementation of our framework.
CELL your Model: Contrastive Explanation Methods for Large Language Models
Jun 17, 2024The advent of black-box deep neural network classification models has sparked the need to explain their decisions. However, in the case of generative AI such as large language models (LLMs), there is no class prediction to explain. Rather, one can ask why an LLM output a particular response to a given prompt. In this paper, we answer this question by proposing, to the best of our knowledge, the first contrastive explanation methods requiring simply black-box/query access. Our explanations suggest that an LLM outputs a reply to a given prompt because if the prompt was slightly modified, the LLM would have given a different response that is either less preferable or contradicts the original response. The key insight is that contrastive explanations simply require a distance function that has meaning to the user and not necessarily a real valued representation of a specific response (viz. class label). We offer two algorithms for finding contrastive explanations: i) A myopic algorithm, which although effective in creating contrasts, requires many model calls and ii) A budgeted algorithm, our main algorithmic contribution, which intelligently creates contrasts adhering to a query budget, necessary for longer contexts. We show the efficacy of these methods on diverse natural language tasks such as open-text generation, automated red teaming, and explaining conversational degradation.