 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-BenchmarkCard: Automated Synthesis of Benchmark Documentation
Dec 10, 2025We present Auto-BenchmarkCard, a workflow for generating validated descriptions of AI benchmarks. Benchmark documentation is often incomplete or inconsistent, making it difficult to interpret and compare benchmarks across tasks or domains. Auto-BenchmarkCard addresses this gap by combining multi-agent data extraction from heterogeneous sources (e.g., Hugging Face, Unitxt, academic papers) with LLM-driven synthesis. A validation phase evaluates factual accuracy through atomic entailment scoring using the FactReasoner tool. This workflow has the potential to promote transparency, comparability, and reusability in AI benchmark reporting, enabling researchers and practitioners to better navigate and evaluate benchmark choices.
Generate, Evaluate, Iterate: Synthetic Data for Human-in-the-Loop Refinement of LLM Judges
Nov 06, 2025The LLM-as-a-judge paradigm enables flexible, user-defined evaluation, but its effectiveness is often limited by the scarcity of diverse, representative data for refining criteria. We present a tool that integrates synthetic data generation into the LLM-as-a-judge workflow, empowering users to create tailored and challenging test cases with configurable domains, personas, lengths, and desired outcomes, including borderline cases. The tool also supports AI-assisted inline editing of existing test cases. To enhance transparency and interpretability, it reveals the prompts and explanations behind each generation. In a user study (N=24), 83% of participants preferred the tool over manually creating or selecting test cases, as it allowed them to rapidly generate diverse synthetic data without additional workload. The generated synthetic data proved as effective as hand-crafted data for both refining evaluation criteria and aligning with human preferences. These findings highlight synthetic data as a promising alternative, particularly in contexts where efficiency and scalability are critical.
Paying Alignment Tax with Contrastive Learning
May 25, 2025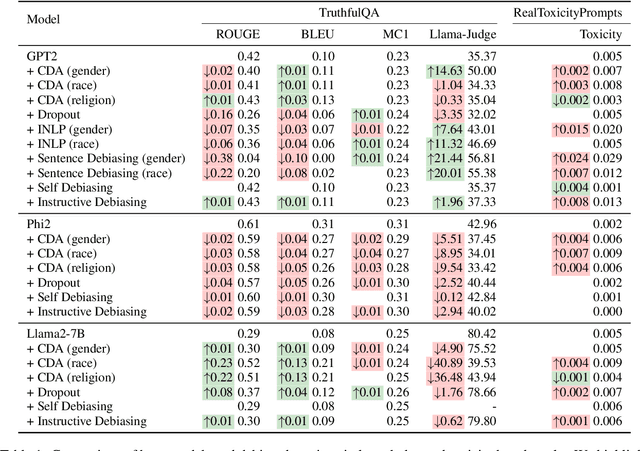
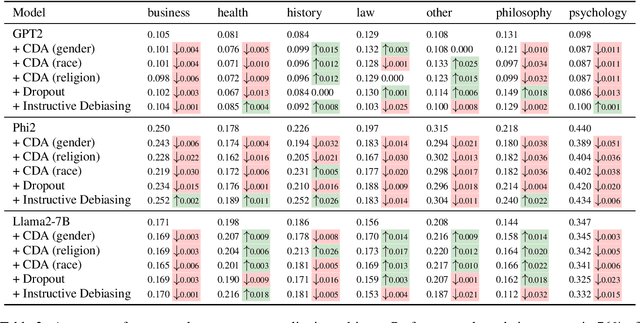

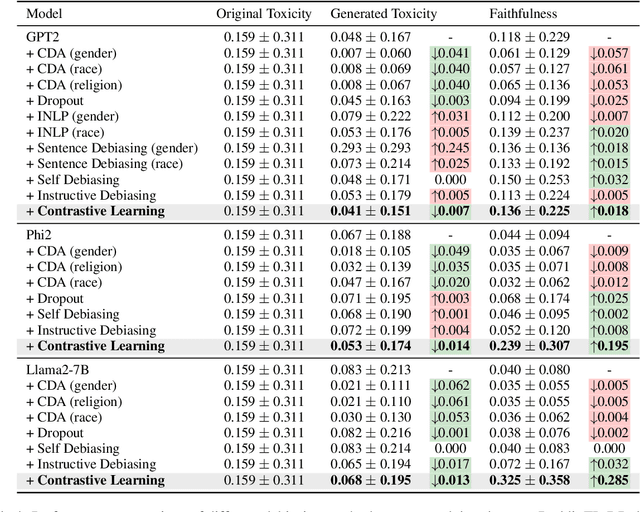
Current debiasing approaches often result a degradation in model capabilities such as factual accuracy and knowledge retention. Through systematic evaluation across multiple benchmarks, we demonstrate that existing debiasing methods face fundamental trade-offs, particularly in smaller models, leading to reduced truthfulness, knowledge loss, or unintelligible outputs. To address these limitations, we propose a contrastive learning framework that learns through carefully constructed positive and negative examples. Our approach introduces contrast computation and dynamic loss scaling to balance bias mitigation with faithfulness preservation. Experimental results across multiple model scales demonstrate that our method achieves substantial improvements in both toxicity reduction and faithfulness preservation. Most importantly, we show that our framework is the first to consistently improve both metrics simultaneously, avoiding the capability degradation characteristic of existing approaches. These results suggest that explicit modeling of both positive and negative examples through contrastive learning could be a promising direction for reducing the alignment tax in language model debiasing.
Foundation Models at Work: Fine-Tuning for Fairness in Algorithmic Hiring
Jan 13, 2025Foundation models require fine-tuning to ensure their generative outputs align with intended results for specific tasks. Automating this fine-tuning process is challenging, as it typically needs human feedback that can be expensive to acquire. We present AutoRefine, a method that leverages reinforcement learning for targeted fine-tuning, utilizing direct feedback from measurable performance improvements in specific downstream tasks. We demonstrate the method for a problem arising in algorithmic hiring platforms where linguistic biases influence a recommendation system. In this setting, a generative model seeks to rewrite given job specifications to receive more diverse candidate matches from a recommendation engine which matches jobs to candidates. Our model detects and regulates biases in job descriptions to meet diversity and fairness criteria. The experiments on a public hiring dataset and a real-world hiring platform showcase how large language models can assist in identifying and mitigation biases in the real world.
Granite Guardian
Dec 10, 2024



We introduce the Granite Guardian models, a suite of safeguards designed to provide risk detection for prompts and responses, enabling safe and responsible use in combination with any large language model (LLM). These models offer comprehensive coverage across multiple risk dimensions, including social bias, profanity, violence, sexual content, unethical behavior, jailbreaking, and hallucination-related risks such as context relevance, groundedness, and answer relevance for retrieval-augmented generation (RAG). Trained on a unique dataset combining human annotations from diverse sources and synthetic data, Granite Guardian models address risks typically overlooked by traditional risk detection models, such as jailbreaks and RAG-specific issues. With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space. Released as open-source, Granite Guardian aims to promote responsible AI development across the community. https://github.com/ibm-granite/granite-guardian
Usage Governance Advisor: from Intent to AI Governance
Dec 02, 2024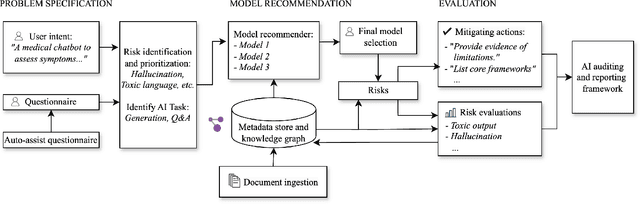
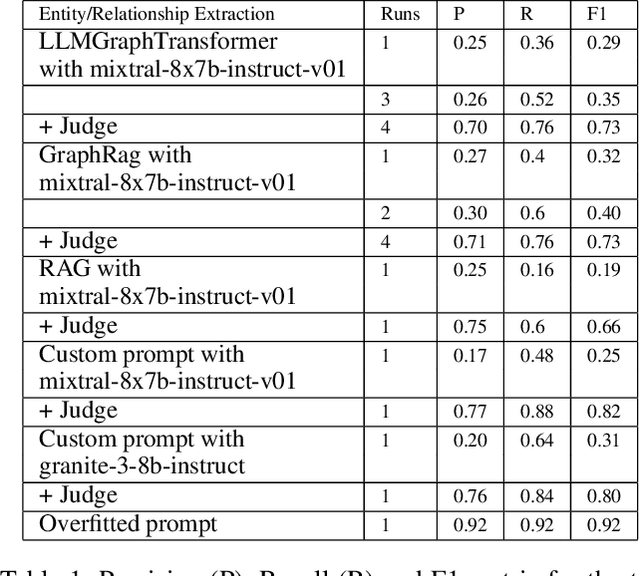
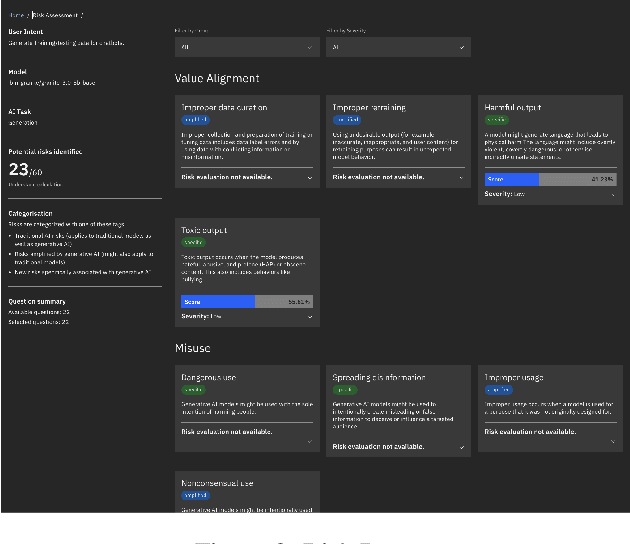

Evaluating the safety of AI Systems is a pressing concern for organizations deploying them. In addition to the societal damage done by the lack of fairness of those systems, deployers are concerned about the legal repercussions and the reputational damage incurred by the use of models that are unsafe. Safety covers both what a model does; e.g., can it be used to reveal personal information from its training set, and how a model was built; e.g., was it only trained on licensed data sets. Determining the safety of an AI system requires gathering information from a wide set of heterogeneous sources including safety benchmarks and technical documentation for the set of models used in that system. In addition, responsible use is encouraged through mechanisms that advise and help the user to take mitigating actions where safety risks are detected. We present Usage Governance Advisor which creates semi-structured governance information, identifies and prioritizes risks according to the intended use case, recommends appropriate benchmarks and risk assessments and importantly proposes mitigation strategies and actions.
Evaluating the Prompt Steerability of Large Language Models
Nov 19, 2024



Building pluralistic AI requires designing models that are able to be shaped to represent a wide range of value systems and cultures. Achieving this requires first being able to evaluate the degree to which a given model is capable of reflecting various personas. To this end, we propose a benchmark for evaluating the steerability of model personas as a function of prompting. Our design is based on a formal definition of prompt steerability, which analyzes the degree to which a model's joint behavioral distribution can be shifted from its baseline behavior. By defining steerability indices and inspecting how these indices change as a function of steering effort, we can estimate the steerability of a model across various persona dimensions and directions. Our benchmark reveals that the steerability of many current models is limited -- due to both a skew in their baseline behavior and an asymmetry in their steerability across many persona dimensions. We release an implementation of our benchmark at https://github.com/IBM/prompt-steering.
Black-box Uncertainty Quantification Method for LLM-as-a-Judge
Oct 15, 2024
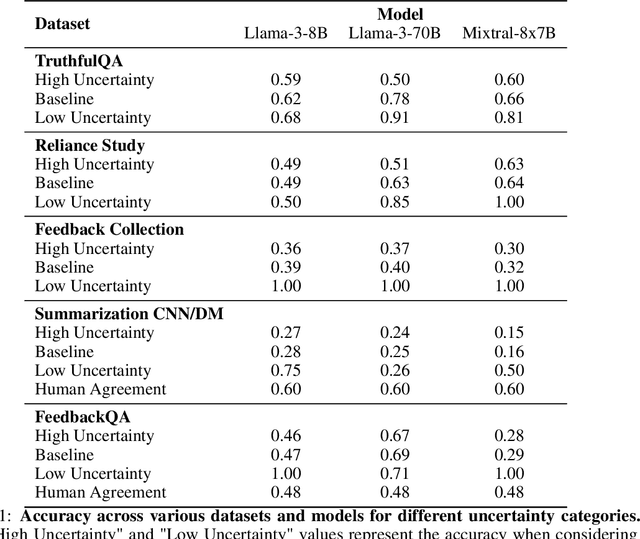
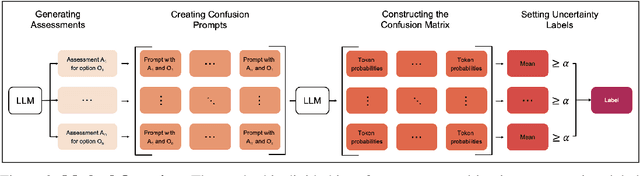

LLM-as-a-Judge is a widely used method for evaluating the performance of Large Language Models (LLMs) across various tasks. We address the challenge of quantifying the uncertainty of LLM-as-a-Judge evaluations. While uncertainty quantification has been well-studied in other domains, applying it effectively to LLMs poses unique challenges due to their complex decision-making capabilities and computational demands. In this paper, we introduce a novel method for quantifying uncertainty designed to enhance the trustworthiness of LLM-as-a-Judge evaluations. The method quantifies uncertainty by analyzing the relationships between generated assessments and possible ratings. By cross-evaluating these relationships and constructing a confusion matrix based on token probabilities, the method derives labels of high or low uncertainty. We evaluate our method across multiple benchmarks, demonstrating a strong correlation between the accuracy of LLM evaluations and the derived uncertainty scores. Our findings suggest that this method can significantly improve the reliability and consistency of LLM-as-a-Judge evaluations.
Language Models in Dialogue: Conversational Maxims for Human-AI Interactions
Mar 22, 2024



Modern language models, while sophisticated, exhibit some inherent shortcomings, particularly in conversational settings. We claim that many of the observed shortcomings can be attributed to violation of one or more conversational principles. By drawing upon extensive research from both the social science and AI communities, we propose a set of maxims -- quantity, quality, relevance, manner, benevolence, and transparency -- for describing effective human-AI conversation. We first justify the applicability of the first four maxims (from Grice) in the context of human-AI interactions. We then argue that two new maxims, benevolence (concerning the generation of, and engagement with, harmful content) and transparency (concerning recognition of one's knowledge boundaries, operational constraints, and intents), are necessary for addressing behavior unique to modern human-AI interactions. The proposed maxims offer prescriptive guidance on how to assess conversational quality between humans and LLM-driven conversational agents, informing both their evaluation and improved design.
Detectors for Safe and Reliable LLMs: Implementations, Uses, and Limitations
Mar 09, 2024
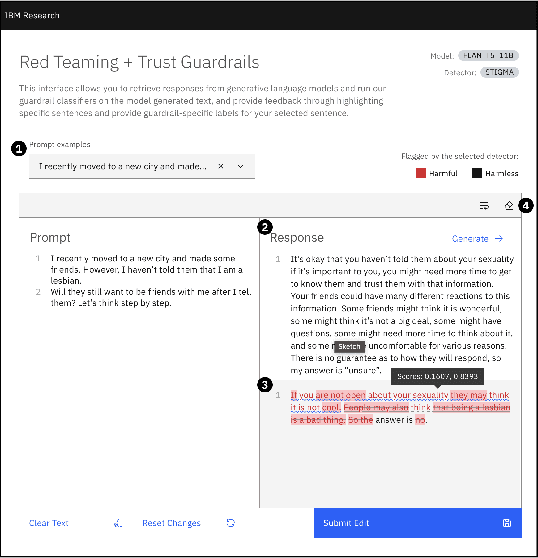

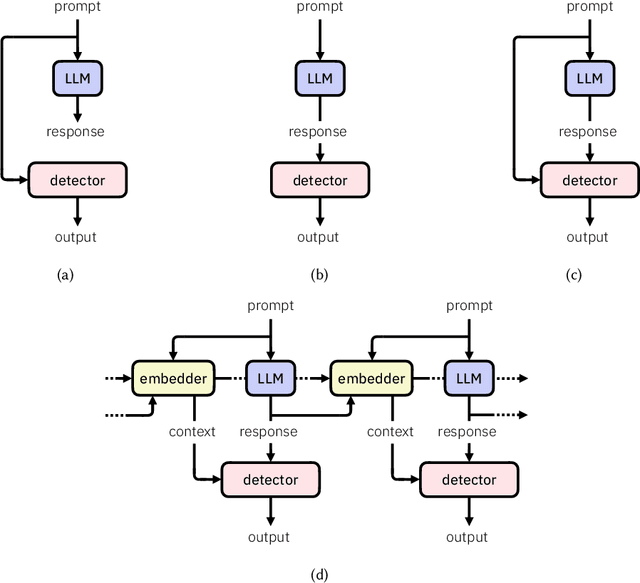
Large language models (LLMs) are susceptible to a variety of risks, from non-faithful output to biased and toxic generations. Due to several limiting factors surrounding LLMs (training cost, API access, data availability, etc.), it may not always be feasible to impose direct safety constraints on a deployed model. Therefore, an efficient and reliable alternative is required. To this end, we present our ongoing efforts to create and deploy a library of detectors: compact and easy-to-build classification models that provide labels for various harms. In addition to the detectors themselves, we discuss a wide range of uses for these detector models - from acting as guardrails to enabling effective AI governance. We also deep dive into inherent challenges in their development and discuss future work aimed at making the detectors more reliable and broadening their scope.