 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Microbiome Relative Abundance Data Using Symbolic Regression
Oct 18, 2024Understanding the complex interactions within the microbiome is crucial for developing effective diagnostic and therapeutic strategies. Traditional machine learning models often lack interpretability, which is essential for clinical and biological insights. This paper explores the application of symbolic regression (SR) to microbiome relative abundance data, with a focus on colorectal cancer (CRC). SR, known for its high interpretability, is compared against traditional machine learning models, e.g., random forest, gradient boosting decision trees. These models are evaluated based on performance metrics such as F1 score and accuracy. We utilize 71 studies encompassing, from various cohorts, over 10,000 samples across 749 species features. Our results indicate that SR not only competes reasonably well in terms of predictive performance, but also excels in model interpretability. SR provides explicit mathematical expressions that offer insights into the biological relationships within the microbiome, a crucial advantage for clinical and biological interpretation. Our experiments also show that SR can help understand complex models like XGBoost via knowledge distillation. To aid in reproducibility and further research, we have made the code openly available at https://github.com/swag2198/microbiome-symbolic-regression .
Trust Regions for Explanations via Black-Box Probabilistic Certification
Feb 21, 2024



Given the black box nature of machine learning models, a plethora of explainability methods have been developed to decipher the factors behind individual decisions. In this paper, we introduce a novel problem of black box (probabilistic) explanation certification. We ask the question: Given a black box model with only query access, an explanation for an example and a quality metric (viz. fidelity, stability), can we find the largest hypercube (i.e., $\ell_{\infty}$ ball) centered at the example such that when the explanation is applied to all examples within the hypercube, (with high probability) a quality criterion is met (viz. fidelity greater than some value)? Being able to efficiently find such a \emph{trust region} has multiple benefits: i) insight into model behavior in a \emph{region}, with a \emph{guarantee}; ii) ascertained \emph{stability} of the explanation; iii) \emph{explanation reuse}, which can save time, energy and money by not having to find explanations for every example; and iv) a possible \emph{meta-metric} to compare explanation methods. Our contributions include formalizing this problem, proposing solutions, providing theoretical guarantees for these solutions that are computable, and experimentally showing their efficacy on synthetic and real data.
Interpretable Differencing of Machine Learning Models
Jun 13, 2023Understanding the differences between machine learning (ML) models is of interest in scenarios ranging from choosing amongst a set of competing models, to updating a deployed model with new training data. In these cases, we wish to go beyond differences in overall metrics such as accuracy to identify where in the feature space do the differences occur. We formalize this problem of model differencing as one of predicting a dissimilarity function of two ML models' outputs, subject to the representation of the differences being human-interpretable. Our solution is to learn a Joint Surrogate Tree (JST), which is composed of two conjoined decision tree surrogates for the two models. A JST provides an intuitive representation of differences and places the changes in the context of the models' decision logic. Context is important as it helps users to map differences to an underlying mental model of an AI system. We also propose a refinement procedure to increase the precision of a JST. We demonstrate, through an empirical evaluation, that such contextual differencing is concise and can be achieved with no loss in fidelity over naive approaches.
Automated Testing of AI Models
Oct 07, 2021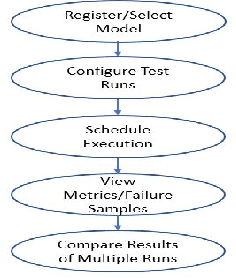
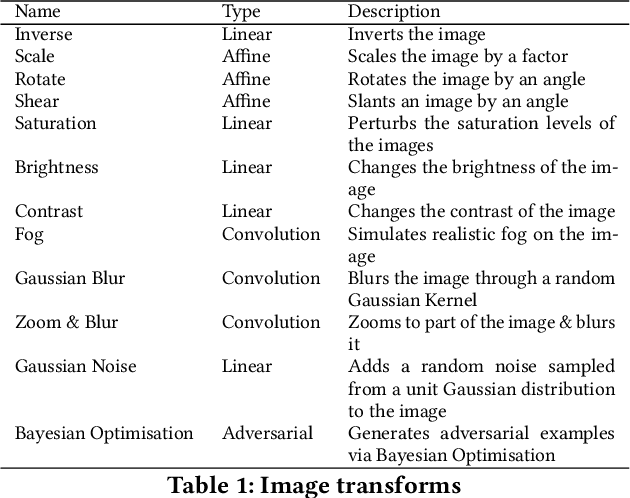
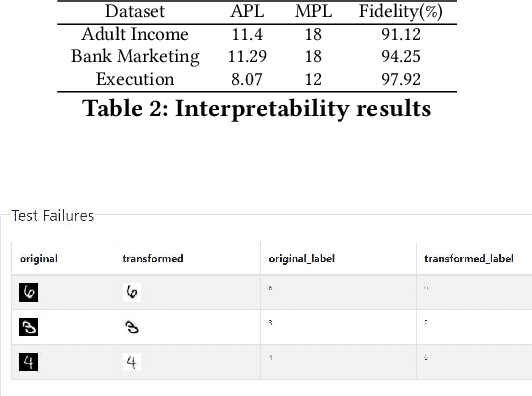
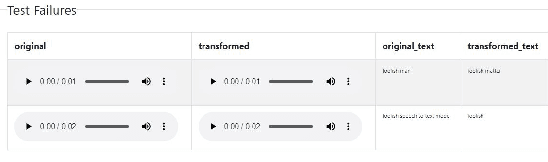
The last decade has seen tremendous progress in AI technology and applications. With such widespread adoption, ensuring the reliability of the AI models is crucial. In past, we took the first step of creating a testing framework called AITEST for metamorphic properties such as fairness, robustness properties for tabular, time-series, and text classification models. In this paper, we extend the capability of the AITEST tool to include the testing techniques for Image and Speech-to-text models along with interpretability testing for tabular models. These novel extensions make AITEST a comprehensive framework for testing AI models.