 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Multi-Label Emotion Classification at Scale with Synthetic Data
Apr 14, 2026Emotion classification in multilingual settings remains constrained by the scarcity of annotated data: existing corpora are predominantly English, single-label, and cover few languages. We address this gap by constructing a large-scale synthetic training corpus of over 1M multi-label samples (50k per language) across 23 languages: Arabic, Bengali, Dutch, English, French, German, Hindi, Indonesian, Italian, Japanese, Korean, Mandarin, Polish, Portuguese, Punjabi, Russian, Spanish, Swahili, Tamil, Turkish, Ukrainian, Urdu, and Vietnamese, covering 11 emotion categories using culturally-adapted generation and programmatic quality filtering. We train and compare six multilingual transformer encoders, from DistilBERT (135M parameters) to XLM-R-Large (560M parameters), under identical conditions. On our in-domain test set, XLM-R-Large achieves 0.868 F1-micro and 0.987 AUC-micro. To validate against human-annotated data, we evaluate all models zero-shot on GoEmotions (English) and SemEval-2018 Task 1 E-c (English, Arabic, Spanish). On threshold-free ranking metrics, XLM-R-Large matches or exceeds English-only specialist models, tying on AP-micro (0.636) and LRAP (0.804) while surpassing on AUC-micro (0.810 vs. 0.787), while natively supporting all 23 languages. The best base-sized model is publicly available at https://huggingface.co/tabularisai/multilingual-emotion-classification
Do Chatbot LLMs Talk Too Much? The YapBench Benchmark
Jan 02, 2026Large Language Models (LLMs) such as ChatGPT, Claude, and Gemini increasingly act as general-purpose copilots, yet they often respond with unnecessary length on simple requests, adding redundant explanations, hedging, or boilerplate that increases cognitive load and inflates token-based inference cost. Prior work suggests that preference-based post-training and LLM-judged evaluations can induce systematic length bias, where longer answers are rewarded even at comparable quality. We introduce YapBench, a lightweight benchmark for quantifying user-visible over-generation on brevity-ideal prompts. Each item consists of a single-turn prompt, a curated minimal-sufficient baseline answer, and a category label. Our primary metric, YapScore, measures excess response length beyond the baseline in characters, enabling comparisons across models without relying on any specific tokenizer. We summarize model performance via the YapIndex, a uniformly weighted average of category-level median YapScores. YapBench contains over three hundred English prompts spanning three common brevity-ideal settings: (A) minimal or ambiguous inputs where the ideal behavior is a short clarification, (B) closed-form factual questions with short stable answers, and (C) one-line coding tasks where a single command or snippet suffices. Evaluating 76 assistant LLMs, we observe an order-of-magnitude spread in median excess length and distinct category-specific failure modes, including vacuum-filling on ambiguous inputs and explanation or formatting overhead on one-line technical requests. We release the benchmark and maintain a live leaderboard for tracking verbosity behavior over time.
Interpreting Microbiome Relative Abundance Data Using Symbolic Regression
Oct 18, 2024Understanding the complex interactions within the microbiome is crucial for developing effective diagnostic and therapeutic strategies. Traditional machine learning models often lack interpretability, which is essential for clinical and biological insights. This paper explores the application of symbolic regression (SR) to microbiome relative abundance data, with a focus on colorectal cancer (CRC). SR, known for its high interpretability, is compared against traditional machine learning models, e.g., random forest, gradient boosting decision trees. These models are evaluated based on performance metrics such as F1 score and accuracy. We utilize 71 studies encompassing, from various cohorts, over 10,000 samples across 749 species features. Our results indicate that SR not only competes reasonably well in terms of predictive performance, but also excels in model interpretability. SR provides explicit mathematical expressions that offer insights into the biological relationships within the microbiome, a crucial advantage for clinical and biological interpretation. Our experiments also show that SR can help understand complex models like XGBoost via knowledge distillation. To aid in reproducibility and further research, we have made the code openly available at https://github.com/swag2198/microbiome-symbolic-regression .
Open Artificial Knowledge
Jul 19, 2024The tremendous success of chat-based AI systems like ChatGPT, Claude, and Gemini stems from Large Language Models (LLMs) trained on vast amount of datasets. However, acquiring high-quality, diverse, and ethically sourced training data remains a significant challenge. We introduce the Open Artificial Knowledge (OAK) dataset, a large-scale resource of over 500 million tokens (at the moment of writing) designed to address this issue. OAK leverages an ensemble of state-of-the-art LLMs, including GPT4o, LLaMa3-70B, LLaMa3-8B, Mixtral-8x7B, Gemma-7B, and Gemma-2-9B , to generate high-quality text across diverse domains, guided by Wikipedia's main categories. Our methodology ensures broad knowledge coverage while maintaining coherence and factual accuracy. The OAK dataset aims to foster the development of more capable and aligned language models while addressing critical issues of data scarcity and privacy in LLM training, and it is freely available on www.oakdataset.org.
Relational Local Explanations
Dec 23, 2022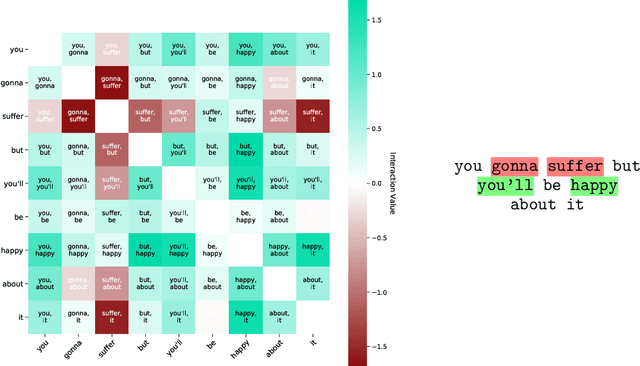

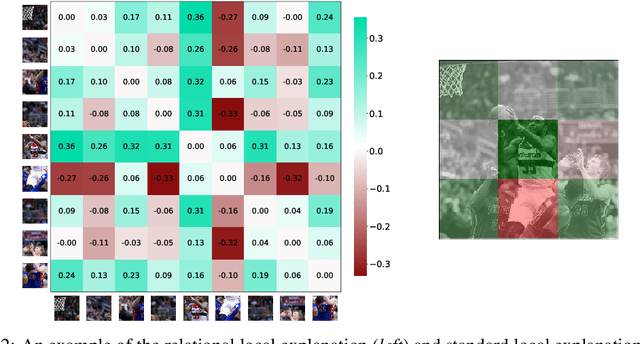
The majority of existing post-hoc explanation approaches for machine learning models produce independent per-variable feature attribution scores, ignoring a critical characteristic, such as the inter-variable relationship between features that naturally occurs in visual and textual data. In response, we develop a novel model-agnostic and permutation-based feature attribution algorithm based on the relational analysis between input variables. As a result, we are able to gain a broader insight into machine learning model decisions and data. This type of local explanation measures the effects of interrelationships between local features, which provides another critical aspect of explanations. Experimental evaluations of our framework using setups involving both image and text data modalities demonstrate its effectiveness and validity.
Language Models are Realistic Tabular Data Generators
Oct 12, 2022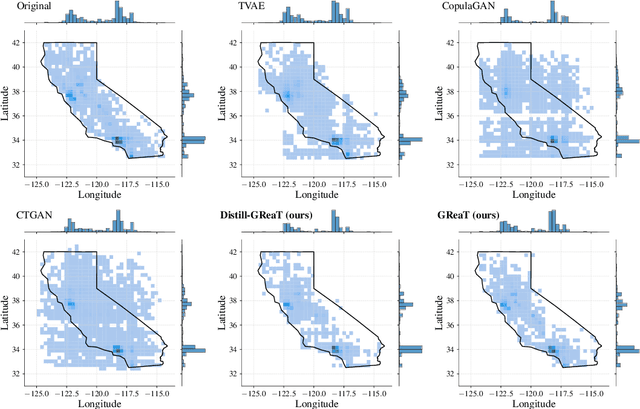
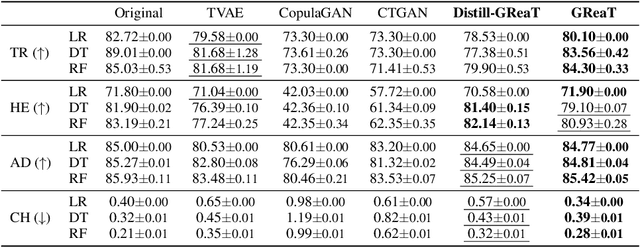
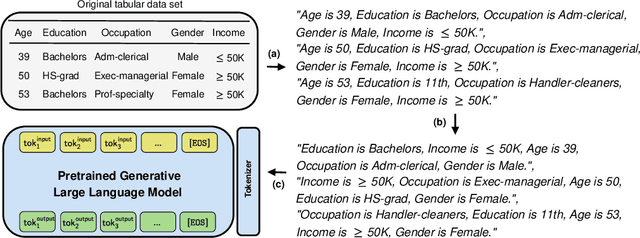
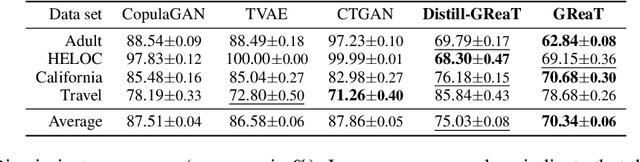
Tabular data is among the oldest and most ubiquitous forms of data. However, the generation of synthetic samples with the original data's characteristics still remains a significant challenge for tabular data. While many generative models from the computer vision domain, such as autoencoders or generative adversarial networks, have been adapted for tabular data generation, less research has been directed towards recent transformer-based large language models (LLMs), which are also generative in nature. To this end, we propose GReaT (Generation of Realistic Tabular data), which exploits an auto-regressive generative LLM to sample synthetic and yet highly realistic tabular data. Furthermore, GReaT can model tabular data distributions by conditioning on any subset of features; the remaining features are sampled without additional overhead. We demonstrate the effectiveness of the proposed approach in a series of experiments that quantify the validity and quality of the produced data samples from multiple angles. We find that GReaT maintains state-of-the-art performance across many real-world data sets with heterogeneous feature types.
BoxShrink: From Bounding Boxes to Segmentation Masks
Aug 05, 2022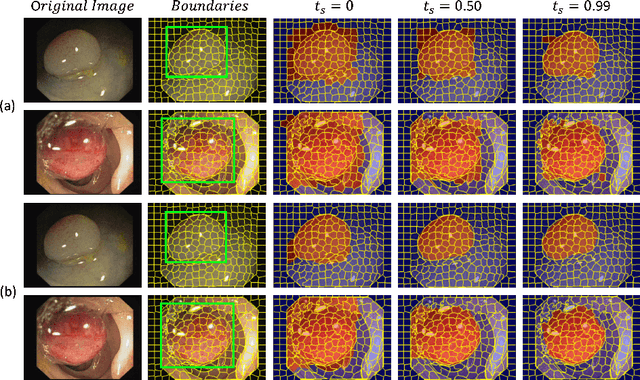
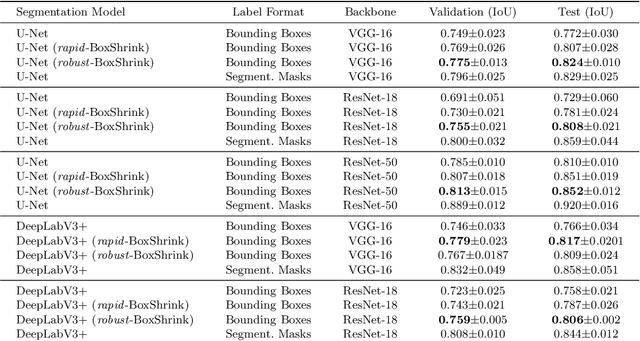
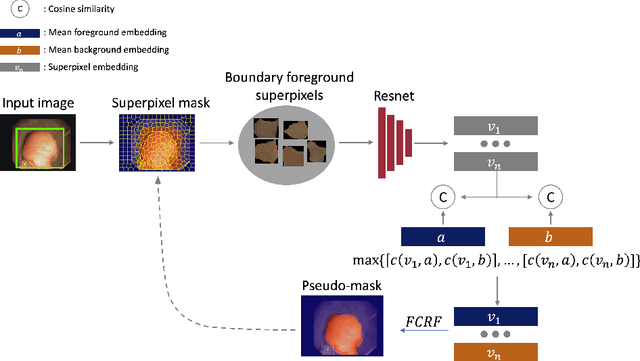
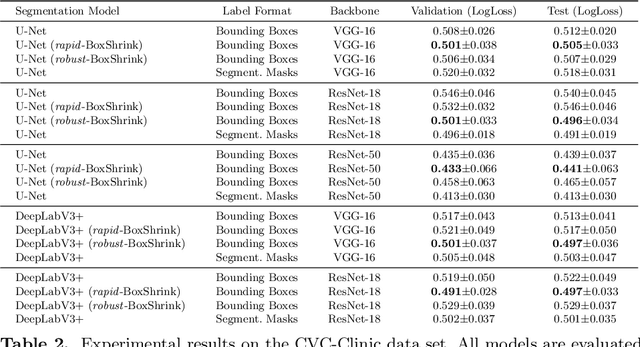
One of the core challenges facing the medical image computing community is fast and efficient data sample labeling. Obtaining fine-grained labels for segmentation is particularly demanding since it is expensive, time-consuming, and requires sophisticated tools. On the contrary, applying bounding boxes is fast and takes significantly less time than fine-grained labeling, but does not produce detailed results. In response, we propose a novel framework for weakly-supervised tasks with the rapid and robust transformation of bounding boxes into segmentation masks without training any machine learning model, coined BoxShrink. The proposed framework comes in two variants - rapid-BoxShrink for fast label transformations, and robust-BoxShrink for more precise label transformations. An average of four percent improvement in IoU is found across several models when being trained using BoxShrink in a weakly-supervised setting, compared to using only bounding box annotations as inputs on a colonoscopy image data set. We open-sourced the code for the proposed framework and published it online.
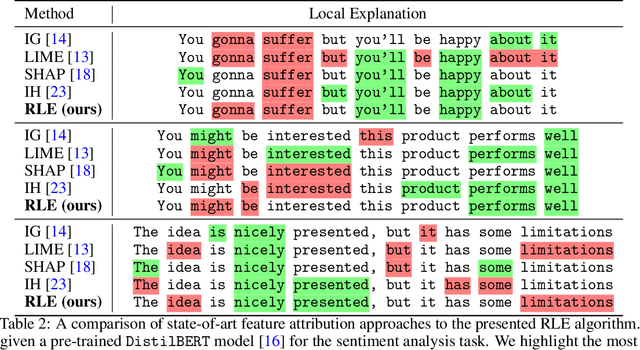
Evaluating Feature Attribution: An Information-Theoretic Perspective
Feb 01, 2022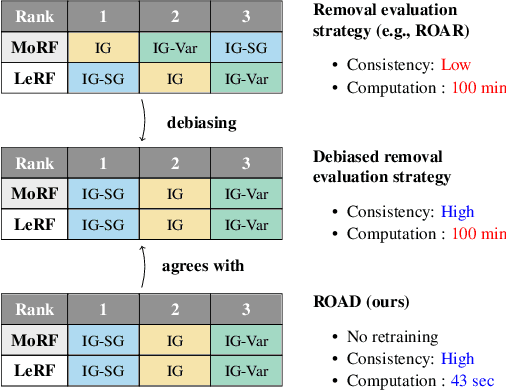

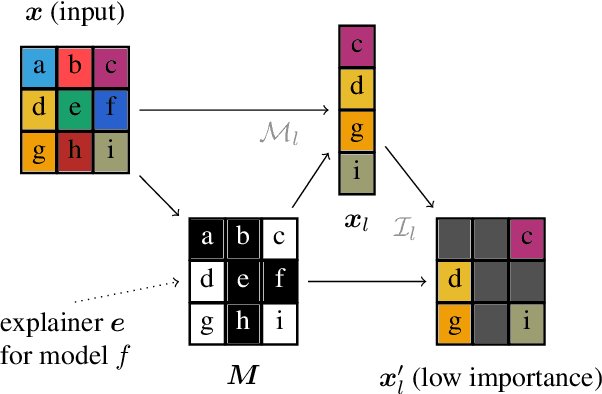
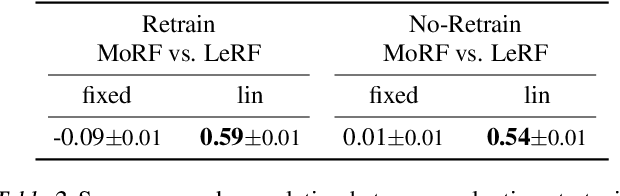
With a variety of local feature attribution methods being proposed in recent years, follow-up work suggested several evaluation strategies. To assess the attribution quality across different attribution techniques, the most popular among these evaluation strategies in the image domain use pixel perturbations. However, recent advances discovered that different evaluation strategies produce conflicting rankings of attribution methods and can be prohibitively expensive to compute. In this work, we present an information-theoretic analysis of evaluation strategies based on pixel perturbations. Our findings reveal that the results output by different evaluation strategies are strongly affected by information leakage through the shape of the removed pixels as opposed to their actual values. Using our theoretical insights, we propose a novel evaluation framework termed Remove and Debias (ROAD) which offers two contributions: First, it mitigates the impact of the confounders, which entails higher consistency among evaluation strategies. Second, ROAD does not require the computationally expensive retraining step and saves up to 99% in computational costs compared to the state-of-the-art. Our source code is available at https://github.com/tleemann/road_evaluation.
A Robust Unsupervised Ensemble of Feature-Based Explanations using Restricted Boltzmann Machines
Nov 14, 2021
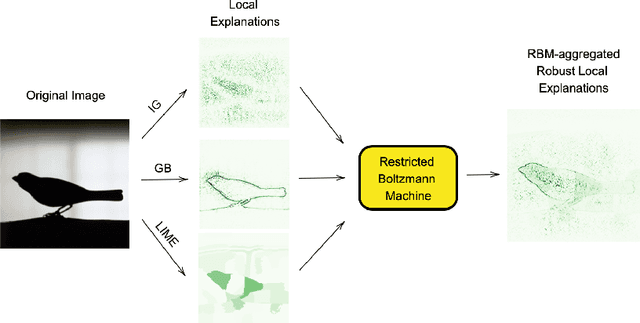
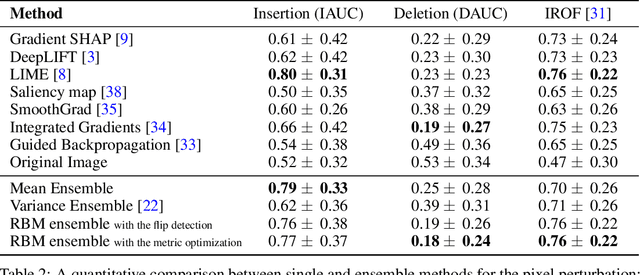

Understanding the results of deep neural networks is an essential step towards wider acceptance of deep learning algorithms. Many approaches address the issue of interpreting artificial neural networks, but often provide divergent explanations. Moreover, different hyperparameters of an explanatory method can lead to conflicting interpretations. In this paper, we propose a technique for aggregating the feature attributions of different explanatory algorithms using Restricted Boltzmann Machines (RBMs) to achieve a more reliable and robust interpretation of deep neural networks. Several challenging experiments on real-world datasets show that the proposed RBM method outperforms popular feature attribution methods and basic ensemble techniques.
Deep Neural Networks and Tabular Data: A Survey
Oct 05, 2021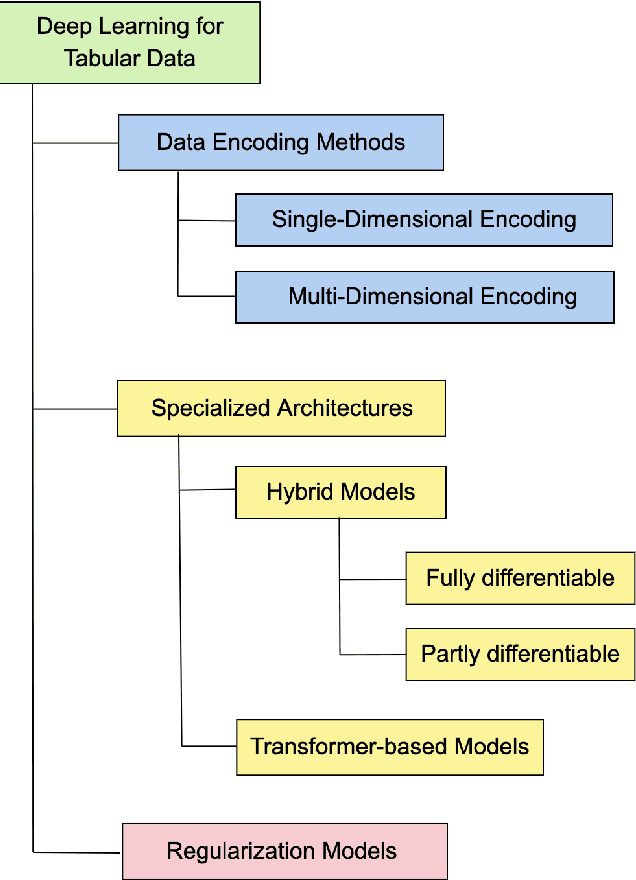
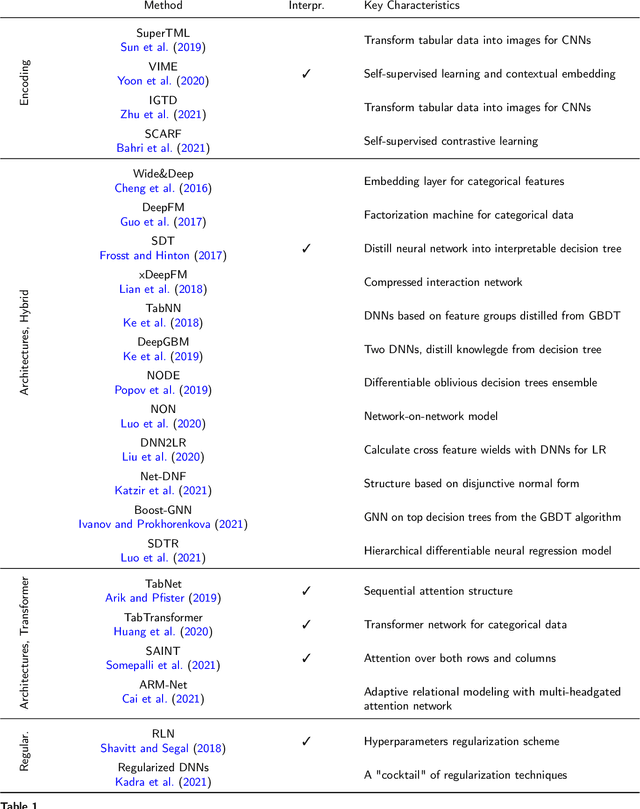
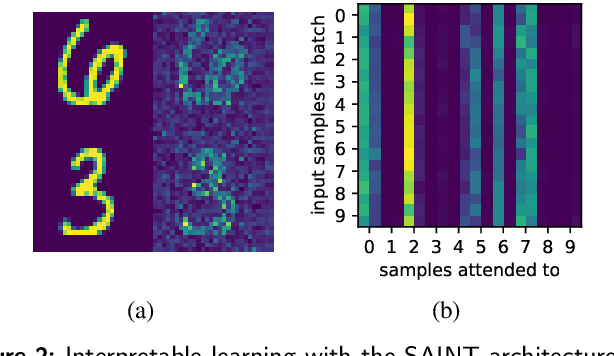
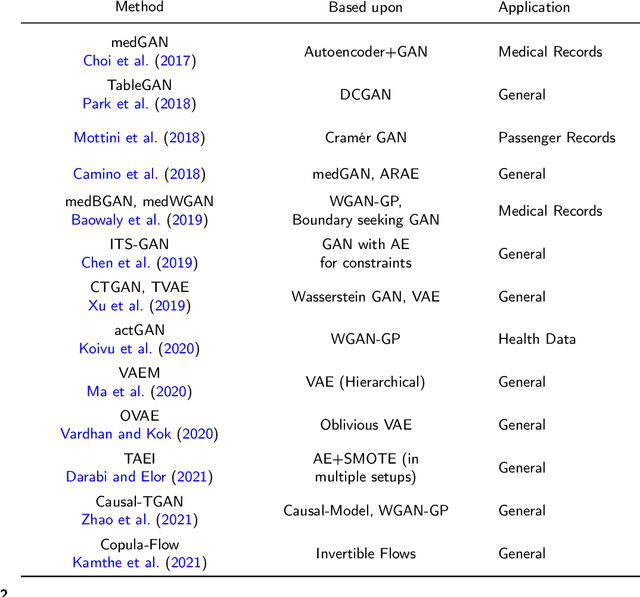
Heterogeneous tabular data are the most commonly used form of data and are essential for numerous critical and computationally demanding applications. On homogeneous data sets, deep neural networks have repeatedly shown excellent performance and have therefore been widely adopted. However, their application to modeling tabular data (inference or generation) remains highly challenging. This work provides an overview of state-of-the-art deep learning methods for tabular data. We start by categorizing them into three groups: data transformations, specialized architectures, and regularization models. We then provide a comprehensive overview of the main approaches in each group. A discussion of deep learning approaches for generating tabular data is complemented by strategies for explaining deep models on tabular data. Our primary contribution is to address the main research streams and existing methodologies in this area, while highlighting relevant challenges and open research questions. To the best of our knowledge, this is the first in-depth look at deep learning approaches for tabular data. This work can serve as a valuable starting point and guide for researchers and practitioners interested in deep learning with tabular data.