 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChange Detection for Local Explainability in Evolving Data Streams
Sep 06, 2022
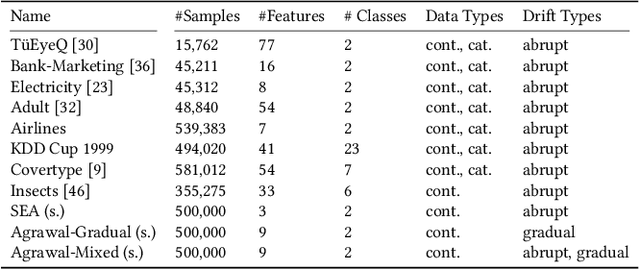
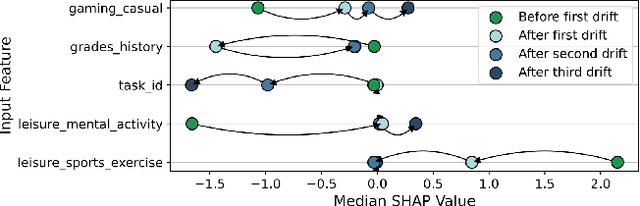

As complex machine learning models are increasingly used in sensitive applications like banking, trading or credit scoring, there is a growing demand for reliable explanation mechanisms. Local feature attribution methods have become a popular technique for post-hoc and model-agnostic explanations. However, attribution methods typically assume a stationary environment in which the predictive model has been trained and remains stable. As a result, it is often unclear how local attributions behave in realistic, constantly evolving settings such as streaming and online applications. In this paper, we discuss the impact of temporal change on local feature attributions. In particular, we show that local attributions can become obsolete each time the predictive model is updated or concept drift alters the data generating distribution. Consequently, local feature attributions in data streams provide high explanatory power only when combined with a mechanism that allows us to detect and respond to local changes over time. To this end, we present CDLEEDS, a flexible and model-agnostic framework for detecting local change and concept drift. CDLEEDS serves as an intuitive extension of attribution-based explanation techniques to identify outdated local attributions and enable more targeted recalculations. In experiments, we also show that the proposed framework can reliably detect both local and global concept drift. Accordingly, our work contributes to a more meaningful and robust explainability in online machine learning.
Standardized Evaluation of Machine Learning Methods for Evolving Data Streams
Apr 28, 2022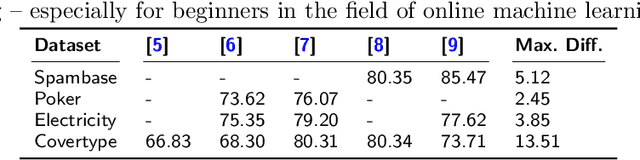
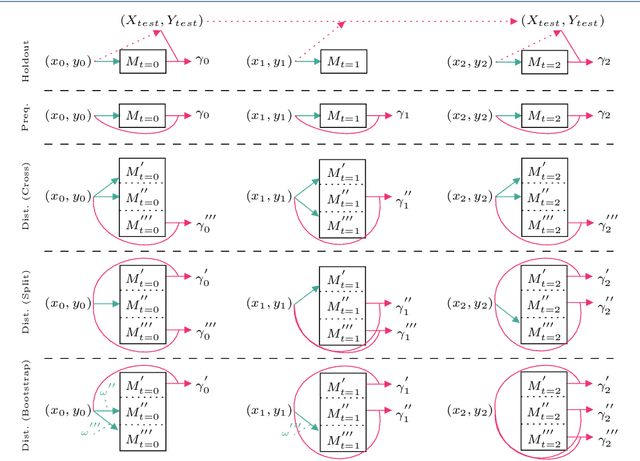
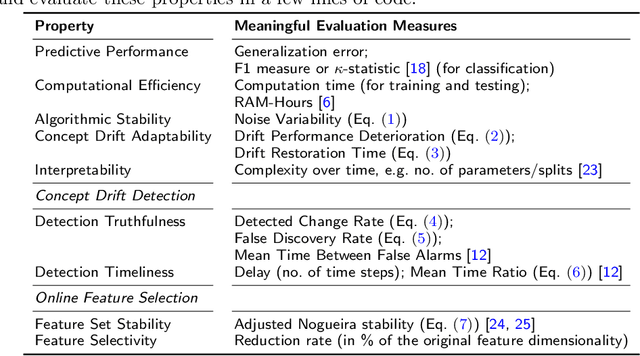
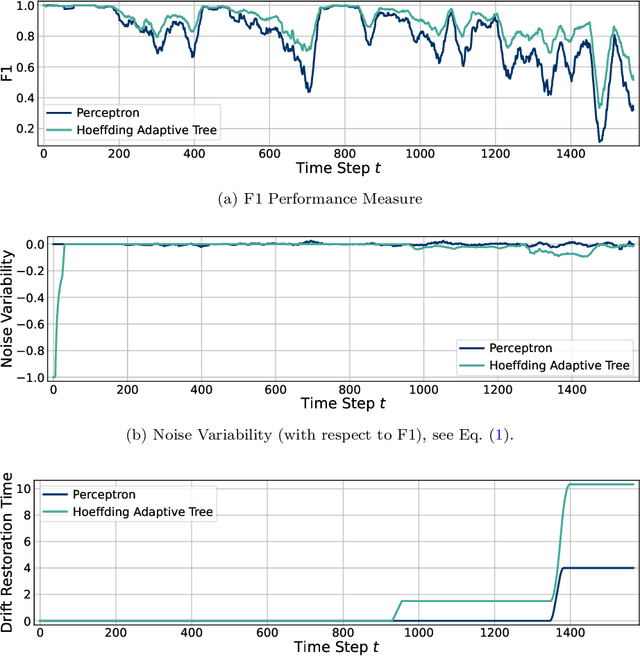
Due to the unspecified and dynamic nature of data streams, online machine learning requires powerful and flexible solutions. However, evaluating online machine learning methods under realistic conditions is difficult. Existing work therefore often draws on different heuristics and simulations that do not necessarily produce meaningful and reliable results. Indeed, in the absence of common evaluation standards, it often remains unclear how online learning methods will perform in practice or in comparison to similar work. In this paper, we propose a comprehensive set of properties for high-quality machine learning in evolving data streams. In particular, we discuss sensible performance measures and evaluation strategies for online predictive modelling, online feature selection and concept drift detection. As one of the first works, we also look at the interpretability of online learning methods. The proposed evaluation standards are provided in a new Python framework called float. Float is completely modular and allows the simultaneous integration of common libraries, such as scikit-multiflow or river, with custom code. Float is open-sourced and can be accessed at https://github.com/haugjo/float. In this sense, we hope that our work will contribute to more standardized, reliable and realistic testing and comparison of online machine learning methods.
Dynamic Model Tree for Interpretable Data Stream Learning
Mar 30, 2022
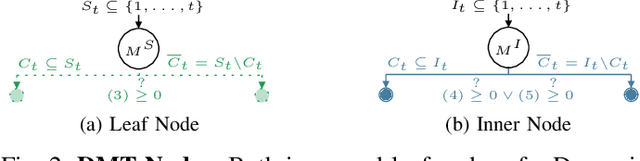


Data streams are ubiquitous in modern business and society. In practice, data streams may evolve over time and cannot be stored indefinitely. Effective and transparent machine learning on data streams is thus often challenging. Hoeffding Trees have emerged as a state-of-the art for online predictive modelling. They are easy to train and provide meaningful convergence guarantees under a stationary process. Yet, at the same time, Hoeffding Trees often require heuristic and costly extensions to adjust to distributional change, which may considerably impair their interpretability. In this work, we revisit Model Trees for machine learning in evolving data streams. Model Trees are able to maintain more flexible and locally robust representations of the active data concept, making them a natural fit for data stream applications. Our novel framework, called Dynamic Model Tree, satisfies desirable consistency and minimality properties. In experiments with synthetic and real-world tabular streaming data sets, we show that the proposed framework can drastically reduce the number of splits required by existing incremental decision trees. At the same time, our framework often outperforms state-of-the-art models in terms of predictive quality -- especially when concept drift is involved. Dynamic Model Trees are thus a powerful online learning framework that contributes to more lightweight and interpretable machine learning in data streams.
Deep Neural Networks and Tabular Data: A Survey
Oct 05, 2021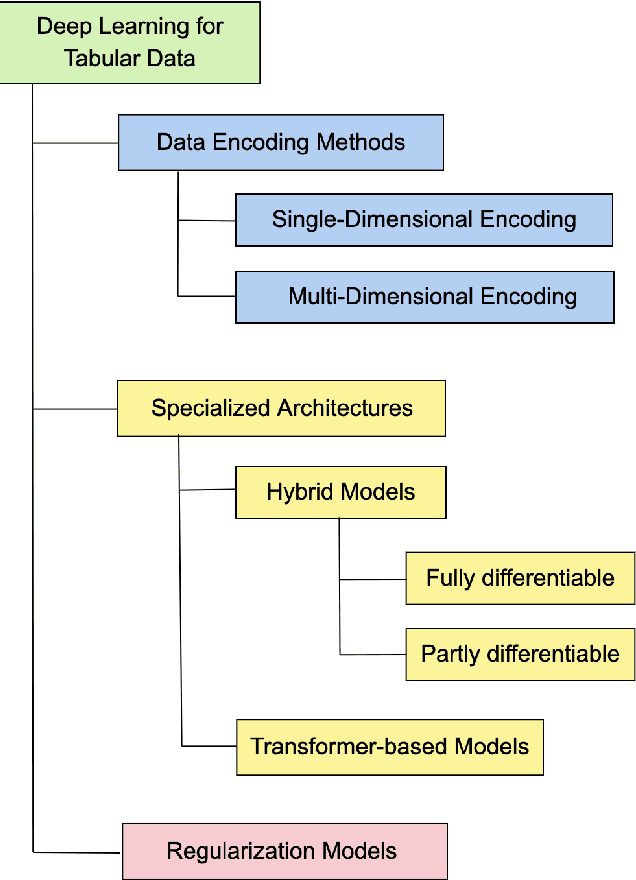
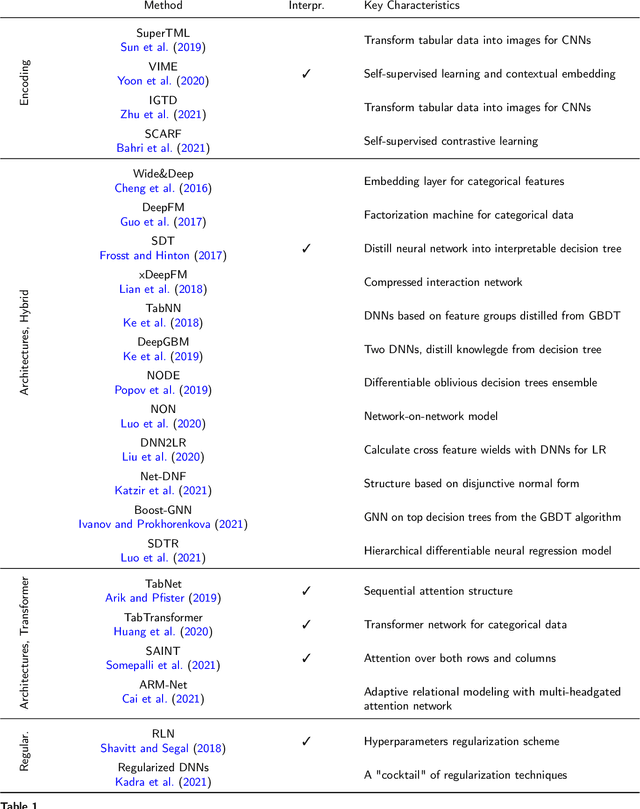
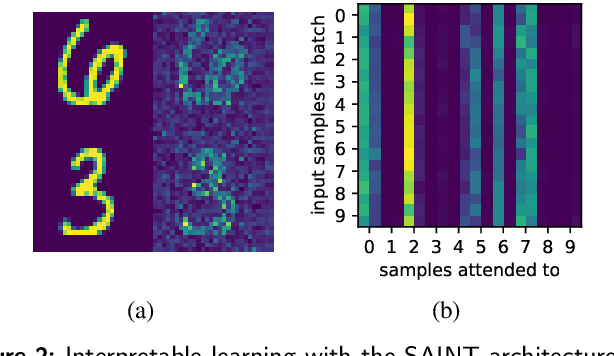
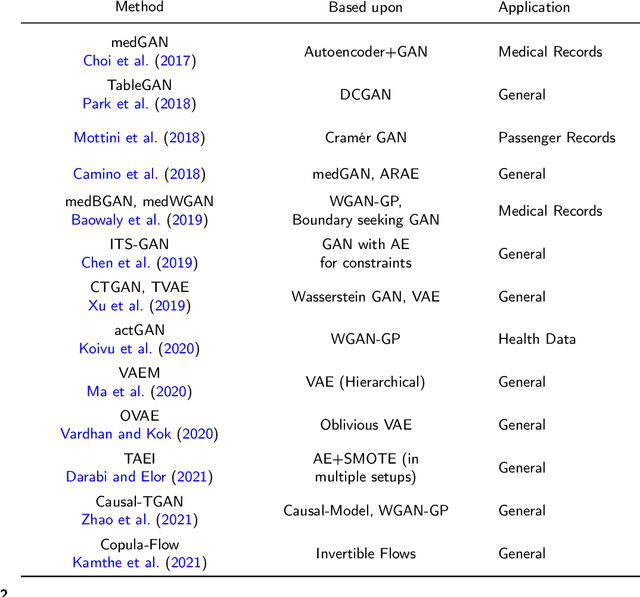
Heterogeneous tabular data are the most commonly used form of data and are essential for numerous critical and computationally demanding applications. On homogeneous data sets, deep neural networks have repeatedly shown excellent performance and have therefore been widely adopted. However, their application to modeling tabular data (inference or generation) remains highly challenging. This work provides an overview of state-of-the-art deep learning methods for tabular data. We start by categorizing them into three groups: data transformations, specialized architectures, and regularization models. We then provide a comprehensive overview of the main approaches in each group. A discussion of deep learning approaches for generating tabular data is complemented by strategies for explaining deep models on tabular data. Our primary contribution is to address the main research streams and existing methodologies in this area, while highlighting relevant challenges and open research questions. To the best of our knowledge, this is the first in-depth look at deep learning approaches for tabular data. This work can serve as a valuable starting point and guide for researchers and practitioners interested in deep learning with tabular data.
On Baselines for Local Feature Attributions
Jan 04, 2021



High-performing predictive models, such as neural nets, usually operate as black boxes, which raises serious concerns about their interpretability. Local feature attribution methods help to explain black box models and are therefore a powerful tool for assessing the reliability and fairness of predictions. To this end, most attribution models compare the importance of input features with a reference value, often called baseline. Recent studies show that the baseline can heavily impact the quality of feature attributions. Yet, we frequently find simplistic baselines, such as the zero vector, in practice. In this paper, we show empirically that baselines can significantly alter the discriminative power of feature attributions. We conduct our analysis on tabular data sets, thus complementing recent works on image data. Besides, we propose a new taxonomy of baseline methods. Our experimental study illustrates the sensitivity of popular attribution models to the baseline, thus laying the foundation for a more in-depth discussion on sensible baseline methods for tabular data.
Learning Parameter Distributions to Detect Concept Drift in Data Streams
Oct 19, 2020
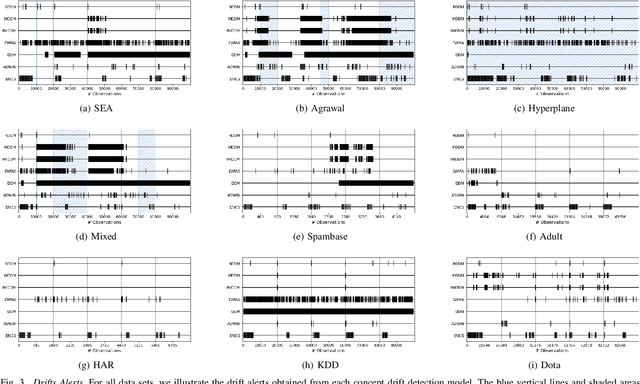
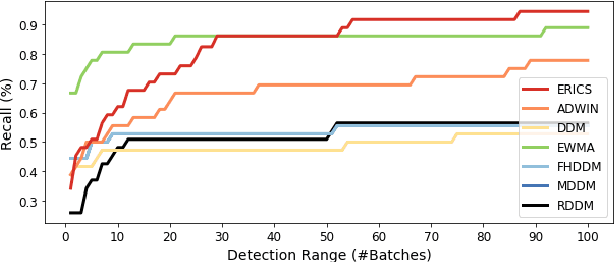
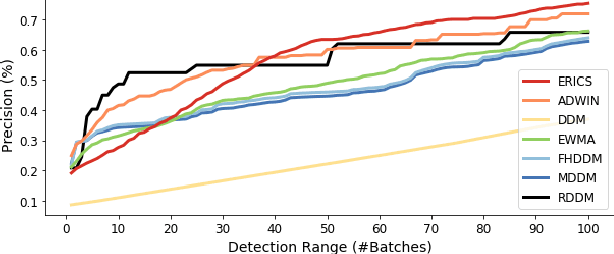
Data distributions in streaming environments are usually not stationary. In order to maintain a high predictive quality at all times, online learning models need to adapt to distributional changes, which are known as concept drift. The timely and robust identification of concept drift can be difficult, as we never have access to the true distribution of streaming data. In this work, we propose a novel framework for the detection of real concept drift, called ERICS. By treating the parameters of a predictive model as random variables, we show that concept drift corresponds to a change in the distribution of optimal parameters. To this end, we adopt common measures from information theory. The proposed framework is completely model-agnostic. By choosing an appropriate base model, ERICS is also capable to detect concept drift at the input level, which is a significant advantage over existing approaches. An evaluation on several synthetic and real-world data sets suggests that the proposed framework identifies concept drift more effectively and precisely than various existing works.
Leveraging Model Inherent Variable Importance for Stable Online Feature Selection
Jun 18, 2020


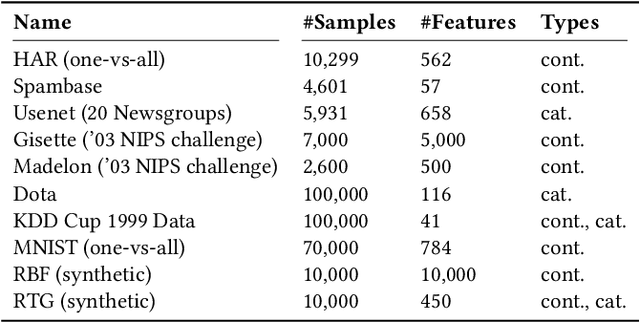
Feature selection can be a crucial factor in obtaining robust and accurate predictions. Online feature selection models, however, operate under considerable restrictions; they need to efficiently extract salient input features based on a bounded set of observations, while enabling robust and accurate predictions. In this work, we introduce FIRES, a novel framework for online feature selection. The proposed feature weighting mechanism leverages the importance information inherent in the parameters of a predictive model. By treating model parameters as random variables, we can penalize features with high uncertainty and thus generate more stable feature sets. Our framework is generic in that it leaves the choice of the underlying model to the user. Strikingly, experiments suggest that the model complexity has only a minor effect on the discriminative power and stability of the selected feature sets. In fact, using a simple linear model, FIRES obtains feature sets that compete with state-of-the-art methods, while dramatically reducing computation time. In addition, experiments show that the proposed framework is clearly superior in terms of feature selection stability.
Towards User Empowerment
Oct 21, 2019

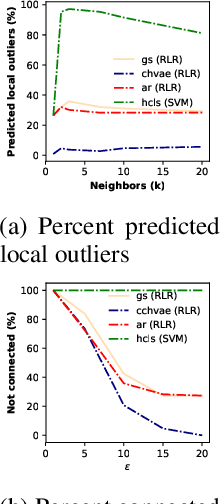
Counterfactual explanations can be obtained by identifying the smallest change made to a feature vector to qualitatively influence a prediction; for example, from 'loan rejected' to 'awarded' or from 'high risk of cardiovascular disease' to 'low risk'. Previous approaches often emphasized that counterfactuals should be easily interpretable to humans, motivating sparse solutions with few changes to the feature vectors. However, these approaches would not ensure that the produced counterfactuals be proximate (i.e., not local outliers) and connected to regions with substantial data density (i.e., close to correctly classified observations), two requirements known as counterfactual faithfulness. These requirements are fundamental when making suggestions to individuals that are indeed attainable. Our contribution is twofold. On one hand, we suggest to complement the catalogue of counterfactual quality measures [1] using a criterion to quantify the degree of difficulty for a certain counterfactual suggestion. On the other hand, drawing ideas from the manifold learning literature, we develop a framework that generates attainable counterfactuals. We suggest the counterfactual conditional heterogeneous variational autoencoder (C-CHVAE) to identify attainable counterfactuals that lie within regions of high data density.