 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Training-Free Corruption Detection for Object Detection Datasets
Jun 09, 2026Annotation errors are widespread in computer vision datasets and can significantly degrade the performance of systems trained on them, particularly in complex tasks such as object detection. Several approaches exist to identify annotation errors, including training-free feature-space methods which provide a fast and interpretable way to analyze annotations. However, the behavior on object detection annotations, which include semantic and spatial information, remains largely unexplored. In this work we analyze the applicability of feature-space-based approaches for detecting annotation errors in object detection datasets. By adapting an existing feature-space method, we show that such approaches reliably expose semantic mislabel, while positional errors remain difficult to detect. We evaluate this behavior across multiple pretrained embedding models, synthetic noise types (symmetric, asymmetric, and positional), and real-world annotation errors using VOC2012 and KITTI. All code and real-world corruptions are publicly available at the following repository: https://github.com/ ChristianSieberichs/BoundingBox\_corruption\_detection
Examining the Impact of Optical Aberrations to Image Classification and Object Detection Models
Apr 25, 2025Deep neural networks (DNNs) have proven to be successful in various computer vision applications such that models even infer in safety-critical situations. Therefore, vision models have to behave in a robust way to disturbances such as noise or blur. While seminal benchmarks exist to evaluate model robustness to diverse corruptions, blur is often approximated in an overly simplistic way to model defocus, while ignoring the different blur kernel shapes that result from optical systems. To study model robustness against realistic optical blur effects, this paper proposes two datasets of blur corruptions, which we denote OpticsBench and LensCorruptions. OpticsBench examines primary aberrations such as coma, defocus, and astigmatism, i.e. aberrations that can be represented by varying a single parameter of Zernike polynomials. To go beyond the principled but synthetic setting of primary aberrations, LensCorruptions samples linear combinations in the vector space spanned by Zernike polynomials, corresponding to 100 real lenses. Evaluations for image classification and object detection on ImageNet and MSCOCO show that for a variety of different pre-trained models, the performance on OpticsBench and LensCorruptions varies significantly, indicating the need to consider realistic image corruptions to evaluate a model's robustness against blur.
Optical aberrations in autonomous driving: Physics-informed parameterized temperature scaling for neural network uncertainty calibration
Dec 18, 2024



'A trustworthy representation of uncertainty is desirable and should be considered as a key feature of any machine learning method' (Huellermeier and Waegeman, 2021). This conclusion of Huellermeier et al. underpins the importance of calibrated uncertainties. Since AI-based algorithms are heavily impacted by dataset shifts, the automotive industry needs to safeguard its system against all possible contingencies. One important but often neglected dataset shift is caused by optical aberrations induced by the windshield. For the verification of the perception system performance, requirements on the AI performance need to be translated into optical metrics by a bijective mapping (Braun, 2023). Given this bijective mapping it is evident that the optical system characteristics add additional information about the magnitude of the dataset shift. As a consequence, we propose to incorporate a physical inductive bias into the neural network calibration architecture to enhance the robustness and the trustworthiness of the AI target application, which we demonstrate by using a semantic segmentation task as an example. By utilizing the Zernike coefficient vector of the optical system as a physical prior we can significantly reduce the mean expected calibration error in case of optical aberrations. As a result, we pave the way for a trustworthy uncertainty representation and for a holistic verification strategy of the perception chain.
BIM-SLAM: Integrating BIM Models in Multi-session SLAM for Lifelong Mapping using 3D LiDAR
Aug 28, 2024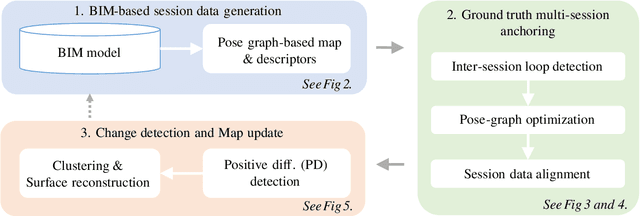

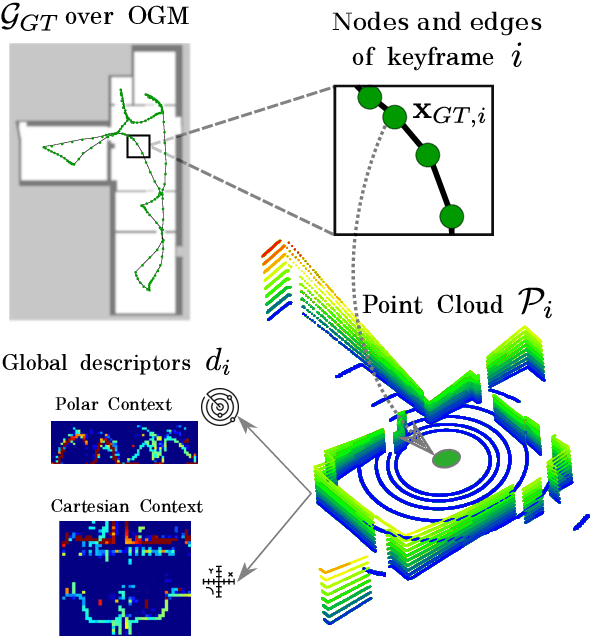
While 3D LiDAR sensor technology is becoming more advanced and cheaper every day, the growth of digitalization in the AEC industry contributes to the fact that 3D building information models (BIM models) are now available for a large part of the built environment. These two facts open the question of how 3D models can support 3D LiDAR long-term SLAM in indoor, GPS-denied environments. This paper proposes a methodology that leverages BIM models to create an updated map of indoor environments with sequential LiDAR measurements. Session data (pose graph-based map and descriptors) are initially generated from BIM models. Then, real-world data is aligned with the session data from the model using multi-session anchoring while minimizing the drift on the real-world data. Finally, the new elements not present in the BIM model are identified, grouped, and reconstructed in a surface representation, allowing a better visualization next to the BIM model. The framework enables the creation of a coherent map aligned with the BIM model that does not require prior knowledge of the initial pose of the robot, and it does not need to be inside the map.
* Conference paper in ISARC 2023
SLAM2REF: Advancing Long-Term Mapping with 3D LiDAR and Reference Map Integration for Precise 6-DoF Trajectory Estimation and Map Extension
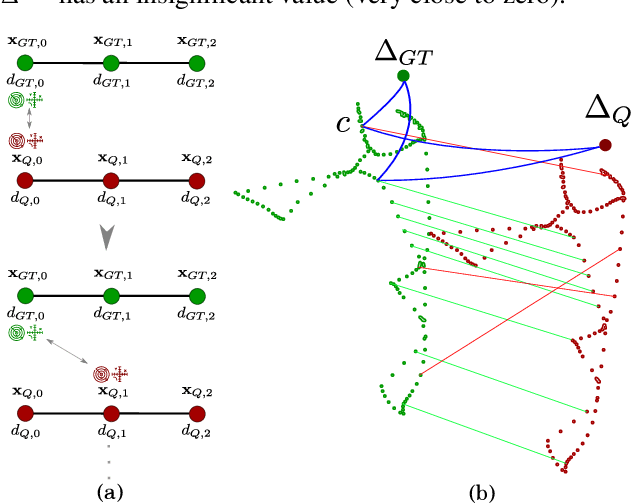
Aug 28, 2024This paper presents a pioneering solution to the task of integrating mobile 3D LiDAR and inertial measurement unit (IMU) data with existing building information models or point clouds, which is crucial for achieving precise long-term localization and mapping in indoor, GPS-denied environments. Our proposed framework, SLAM2REF, introduces a novel approach for automatic alignment and map extension utilizing reference 3D maps. The methodology is supported by a sophisticated multi-session anchoring technique, which integrates novel descriptors and registration methodologies. Real-world experiments reveal the framework's remarkable robustness and accuracy, surpassing current state-of-the-art methods. Our open-source framework's significance lies in its contribution to resilient map data management, enhancing processes across diverse sectors such as construction site monitoring, emergency response, disaster management, and others, where fast-updated digital 3D maps contribute to better decision-making and productivity. Moreover, it offers advancements in localization and mapping research. Link to the repository: https://github.com/MigVega/SLAM2REF, Data: https://doi.org/10.14459/2024mp1743877.
SS-SFR: Synthetic Scenes Spatial Frequency Response on Virtual KITTI and Degraded Automotive Simulations for Object Detection
Jul 22, 2024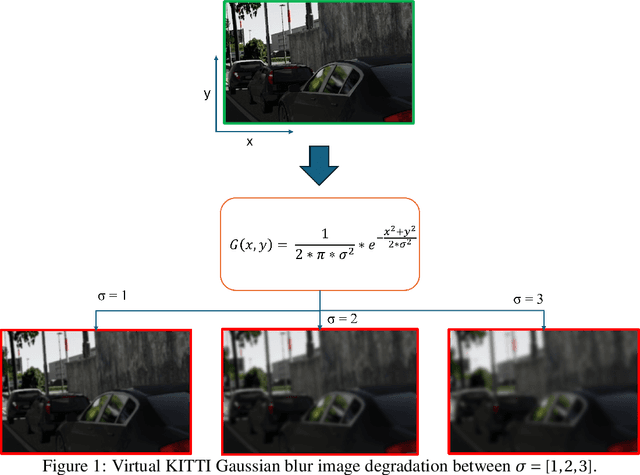

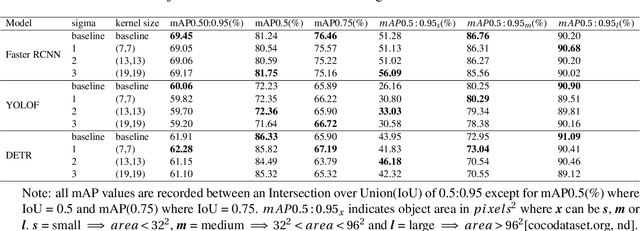
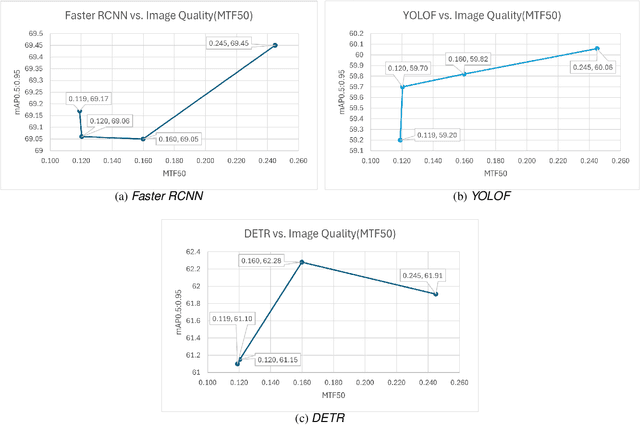
Automotive simulation can potentially compensate for a lack of training data in computer vision applications. However, there has been little to no image quality evaluation of automotive simulation and the impact of optical degradations on simulation is little explored. In this work, we investigate Virtual KITTI and the impact of applying variations of Gaussian blur on image sharpness. Furthermore, we consider object detection, a common computer vision application on three different state-of-the-art models, thus allowing us to characterize the relationship between object detection and sharpness. It was found that while image sharpness (MTF50) degrades from an average of 0.245cy/px to approximately 0.119cy/px; object detection performance stays largely robust within 0.58\%(Faster RCNN), 1.45\%(YOLOF) and 1.93\%(DETR) across all respective held-out test sets.
* 8 pages, 2 figures, 2 tables
Decoupling of neural network calibration measures
Jun 04, 2024



A lot of effort is currently invested in safeguarding autonomous driving systems, which heavily rely on deep neural networks for computer vision. We investigate the coupling of different neural network calibration measures with a special focus on the Area Under the Sparsification Error curve (AUSE) metric. We elaborate on the well-known inconsistency in determining optimal calibration using the Expected Calibration Error (ECE) and we demonstrate similar issues for the AUSE, the Uncertainty Calibration Score (UCS), as well as the Uncertainty Calibration Error (UCE). We conclude that the current methodologies leave a degree of freedom, which prevents a unique model calibration for the homologation of safety-critical functionalities. Furthermore, we propose the AUSE as an indirect measure for the residual uncertainty, which is irreducible for a fixed network architecture and is driven by the stochasticity in the underlying data generation process (aleatoric contribution) as well as the limitation in the hypothesis space (epistemic contribution).
A Point-Based Approach to Efficient LiDAR Multi-Task Perception
Apr 19, 2024Multi-task networks can potentially improve performance and computational efficiency compared to single-task networks, facilitating online deployment. However, current multi-task architectures in point cloud perception combine multiple task-specific point cloud representations, each requiring a separate feature encoder and making the network structures bulky and slow. We propose PAttFormer, an efficient multi-task architecture for joint semantic segmentation and object detection in point clouds that only relies on a point-based representation. The network builds on transformer-based feature encoders using neighborhood attention and grid-pooling and a query-based detection decoder using a novel 3D deformable-attention detection head design. Unlike other LiDAR-based multi-task architectures, our proposed PAttFormer does not require separate feature encoders for multiple task-specific point cloud representations, resulting in a network that is 3x smaller and 1.4x faster while achieving competitive performance on the nuScenes and KITTI benchmarks for autonomous driving perception. Our extensive evaluations show substantial gains from multi-task learning, improving LiDAR semantic segmentation by +1.7% in mIou and 3D object detection by +1.7% in mAP on the nuScenes benchmark compared to the single-task models.
Classification robustness to common optical aberrations
Aug 29, 2023Computer vision using deep neural networks (DNNs) has brought about seminal changes in people's lives. Applications range from automotive, face recognition in the security industry, to industrial process monitoring. In some cases, DNNs infer even in safety-critical situations. Therefore, for practical applications, DNNs have to behave in a robust way to disturbances such as noise, pixelation, or blur. Blur directly impacts the performance of DNNs, which are often approximated as a disk-shaped kernel to model defocus. However, optics suggests that there are different kernel shapes depending on wavelength and location caused by optical aberrations. In practice, as the optical quality of a lens decreases, such aberrations increase. This paper proposes OpticsBench, a benchmark for investigating robustness to realistic, practically relevant optical blur effects. Each corruption represents an optical aberration (coma, astigmatism, spherical, trefoil) derived from Zernike Polynomials. Experiments on ImageNet show that for a variety of different pre-trained DNNs, the performance varies strongly compared to disk-shaped kernels, indicating the necessity of considering realistic image degradations. In addition, we show on ImageNet-100 with OpticsAugment that robustness can be increased by using optical kernels as data augmentation. Compared to a conventionally trained ResNeXt50, training with OpticsAugment achieves an average performance gain of 21.7% points on OpticsBench and 6.8% points on 2D common corruptions.
Occupancy Grid Map to Pose Graph-based Map: Robust BIM-based 2D-LiDAR Localization for Lifelong Indoor Navigation in Changing and Dynamic Environments
Aug 10, 2023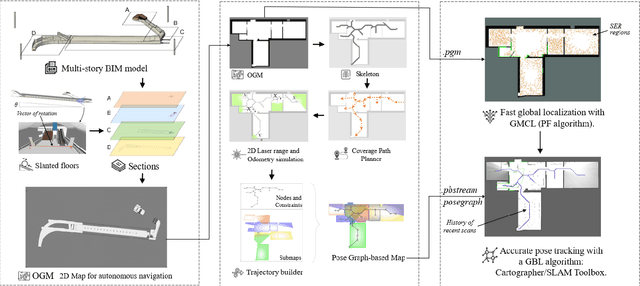


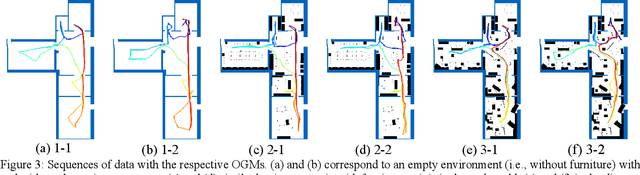
Several studies rely on the de facto standard Adaptive Monte Carlo Localization (AMCL) method to localize a robot in an Occupancy Grid Map (OGM) extracted from a building information model (BIM model). However, most of these studies assume that the BIM model precisely represents the real world, which is rarely true. Discrepancies between the reference BIM model and the real world (Scan-BIM deviations) are not only due to furniture or clutter but also the usual as-planned and as-built deviations that exist with any model created in the design phase. These deviations affect the accuracy of AMCL drastically. This paper proposes an open-source method to generate appropriate Pose Graph-based maps from BIM models for robust 2D-LiDAR localization in changing and dynamic environments. First, 2D OGMs are automatically generated from complex BIM models. These OGMs only represent structural elements allowing indoor autonomous robot navigation. Then, an efficient technique converts these 2D OGMs into Pose Graph-based maps enabling more accurate robot pose tracking. Finally, we leverage the different map representations for accurate, robust localization with a combination of state-of-the-art algorithms. Moreover, we provide a quantitative comparison of various state-of-the-art localization algorithms in three simulated scenarios with varying levels of Scan-BIM deviations and dynamic agents. More precisely, we compare two Particle Filter (PF) algorithms: AMCL and General Monte Carlo Localization (GMCL); and two Graph-based Localization (GBL) methods: Google's Cartographer and SLAM Toolbox, solving the global localization and pose tracking problems. The numerous experiments demonstrate that the proposed method contributes to a robust localization with an as-designed BIM model or a sparse OGM in changing and dynamic environments, outperforming the conventional AMCL in accuracy and robustness.