 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Camera-to-Robot Calibration Method for Vision-Based Floor Measurements
Mar 16, 2026A novel hand-eye calibration method for ground-observing mobile robots is proposed. While cameras on mobile robots are com- mon, they are rarely used for ground-observing measurement tasks. Laser trackers are increasingly used in robotics for precise localization. A referencing plate is designed to combine the two measurement modalities of laser-tracker 3D metrology and camera- based 2D imaging. It incorporates reflector nests for pose acquisition using a laser tracker and a camera calibration target that is observed by the robot-mounted camera. The procedure comprises estimating the plate pose, the plate-camera pose, and the robot pose, followed by computing the robot-camera transformation. Experiments indicate sub-millimeter repeatability.
Evaluation of Visual Place Recognition Methods for Image Pair Retrieval in 3D Vision and Robotics
Mar 14, 2026Visual Place Recognition (VPR) is a core component in computer vision, typically formulated as an image retrieval task for localization, mapping, and navigation. In this work, we instead study VPR as an image pair retrieval front-end for registration pipelines, where the goal is to find top-matching image pairs between two disjoint image sets for downstream tasks such as scene registration, SLAM, and Structure-from-Motion. We comparatively evaluate state-of-the-art VPR families - NetVLAD-style baselines, classification-based global descriptors (CosPlace, EigenPlaces), feature-mixing (MixVPR), and foundation-model-driven methods (AnyLoc, SALAD, MegaLoc) - on three challenging datasets: object-centric outdoor scenes (Tanks and Temples), indoor RGB-D scans (ScanNet-GS), and autonomous-driving sequences (KITTI). We show that modern global descriptor approaches are increasingly suitable as off-the-shelf image pair retrieval modules in challenging scenarios including perceptual aliasing and incomplete sequences, while exhibiting clear, domain-dependent strengths and weaknesses that are critical when choosing VPR components for robust mapping and registration.
Rethinking Semi-supervised Segmentation Beyond Accuracy: Reliability and Robustness
Jun 06, 2025Semantic segmentation is critical for scene understanding but demands costly pixel-wise annotations, attracting increasing attention to semi-supervised approaches to leverage abundant unlabeled data. While semi-supervised segmentation is often promoted as a path toward scalable, real-world deployment, it is astonishing that current evaluation protocols exclusively focus on segmentation accuracy, entirely overlooking reliability and robustness. These qualities, which ensure consistent performance under diverse conditions (robustness) and well-calibrated model confidences as well as meaningful uncertainties (reliability), are essential for safety-critical applications like autonomous driving, where models must handle unpredictable environments and avoid sudden failures at all costs. To address this gap, we introduce the Reliable Segmentation Score (RSS), a novel metric that combines predictive accuracy, calibration, and uncertainty quality measures via a harmonic mean. RSS penalizes deficiencies in any of its components, providing an easy and intuitive way of holistically judging segmentation models. Comprehensive evaluations of UniMatchV2 against its predecessor and a supervised baseline show that semi-supervised methods often trade reliability for accuracy. While out-of-domain evaluations demonstrate UniMatchV2's robustness, they further expose persistent reliability shortcomings. We advocate for a shift in evaluation protocols toward more holistic metrics like RSS to better align semi-supervised learning research with real-world deployment needs.
A Critical Synthesis of Uncertainty Quantification and Foundation Models in Monocular Depth Estimation
Jan 14, 2025
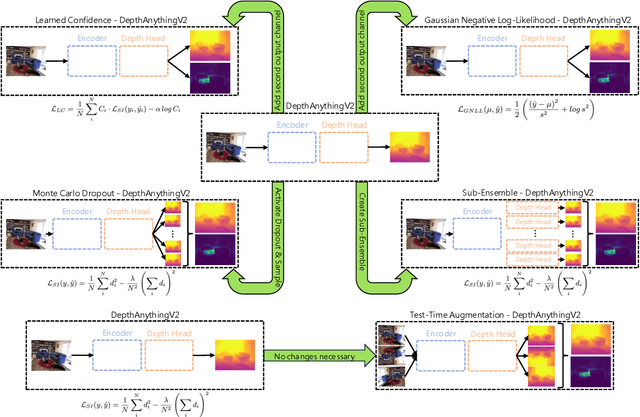
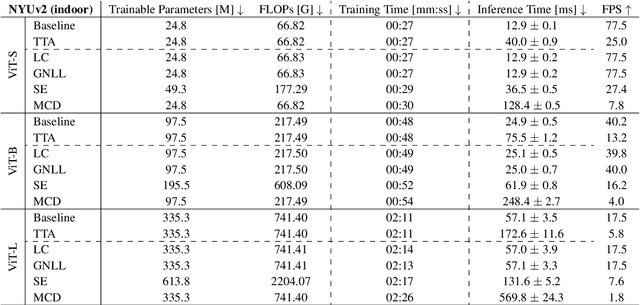
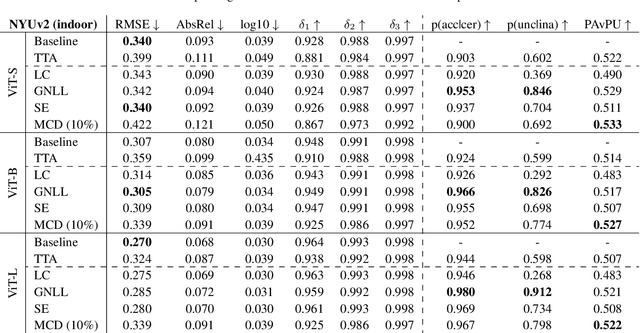
While recent foundation models have enabled significant breakthroughs in monocular depth estimation, a clear path towards safe and reliable deployment in the real-world remains elusive. Metric depth estimation, which involves predicting absolute distances, poses particular challenges, as even the most advanced foundation models remain prone to critical errors. Since quantifying the uncertainty has emerged as a promising endeavor to address these limitations and enable trustworthy deployment, we fuse five different uncertainty quantification methods with the current state-of-the-art DepthAnythingV2 foundation model. To cover a wide range of metric depth domains, we evaluate their performance on four diverse datasets. Our findings identify fine-tuning with the Gaussian Negative Log-Likelihood Loss (GNLL) as a particularly promising approach, offering reliable uncertainty estimates while maintaining predictive performance and computational efficiency on par with the baseline, encompassing both training and inference time. By fusing uncertainty quantification and foundation models within the context of monocular depth estimation, this paper lays a critical foundation for future research aimed at improving not only model performance but also its explainability. Extending this critical synthesis of uncertainty quantification and foundation models into other crucial tasks, such as semantic segmentation and pose estimation, presents exciting opportunities for safer and more reliable machine vision systems.
Optical aberrations in autonomous driving: Physics-informed parameterized temperature scaling for neural network uncertainty calibration
Dec 18, 2024



'A trustworthy representation of uncertainty is desirable and should be considered as a key feature of any machine learning method' (Huellermeier and Waegeman, 2021). This conclusion of Huellermeier et al. underpins the importance of calibrated uncertainties. Since AI-based algorithms are heavily impacted by dataset shifts, the automotive industry needs to safeguard its system against all possible contingencies. One important but often neglected dataset shift is caused by optical aberrations induced by the windshield. For the verification of the perception system performance, requirements on the AI performance need to be translated into optical metrics by a bijective mapping (Braun, 2023). Given this bijective mapping it is evident that the optical system characteristics add additional information about the magnitude of the dataset shift. As a consequence, we propose to incorporate a physical inductive bias into the neural network calibration architecture to enhance the robustness and the trustworthiness of the AI target application, which we demonstrate by using a semantic segmentation task as an example. By utilizing the Zernike coefficient vector of the optical system as a physical prior we can significantly reduce the mean expected calibration error in case of optical aberrations. As a result, we pave the way for a trustworthy uncertainty representation and for a holistic verification strategy of the perception chain.
Decoupling of neural network calibration measures
Jun 04, 2024



A lot of effort is currently invested in safeguarding autonomous driving systems, which heavily rely on deep neural networks for computer vision. We investigate the coupling of different neural network calibration measures with a special focus on the Area Under the Sparsification Error curve (AUSE) metric. We elaborate on the well-known inconsistency in determining optimal calibration using the Expected Calibration Error (ECE) and we demonstrate similar issues for the AUSE, the Uncertainty Calibration Score (UCS), as well as the Uncertainty Calibration Error (UCE). We conclude that the current methodologies leave a degree of freedom, which prevents a unique model calibration for the homologation of safety-critical functionalities. Furthermore, we propose the AUSE as an indirect measure for the residual uncertainty, which is irreducible for a fixed network architecture and is driven by the stochasticity in the underlying data generation process (aleatoric contribution) as well as the limitation in the hypothesis space (epistemic contribution).
Evaluation of Multi-task Uncertainties in Joint Semantic Segmentation and Monocular Depth Estimation
May 27, 2024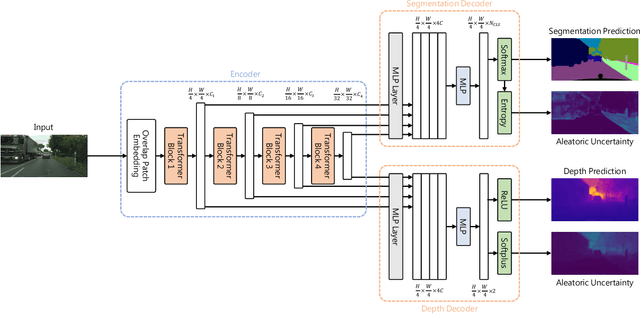
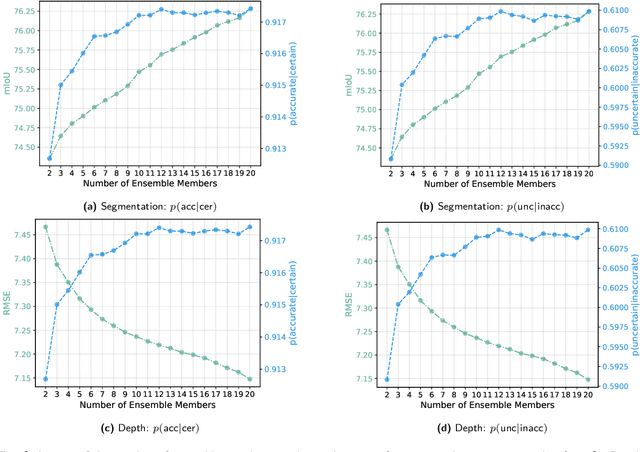
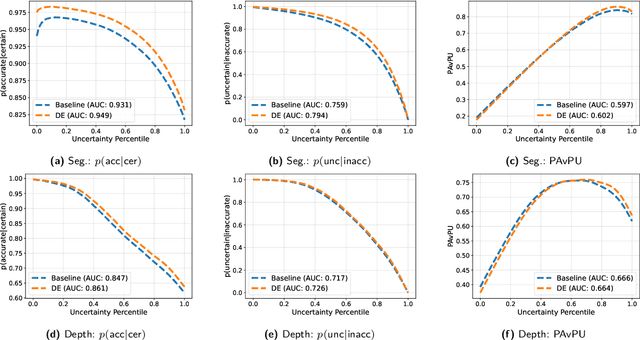
While a number of promising uncertainty quantification methods have been proposed to address the prevailing shortcomings of deep neural networks like overconfidence and lack of explainability, quantifying predictive uncertainties in the context of joint semantic segmentation and monocular depth estimation has not been explored yet. Since many real-world applications are multi-modal in nature and, hence, have the potential to benefit from multi-task learning, this is a substantial gap in current literature. To this end, we conduct a comprehensive series of experiments to study how multi-task learning influences the quality of uncertainty estimates in comparison to solving both tasks separately.
Novel View Synthesis with Neural Radiance Fields for Industrial Robot Applications
May 07, 2024Neural Radiance Fields (NeRFs) have become a rapidly growing research field with the potential to revolutionize typical photogrammetric workflows, such as those used for 3D scene reconstruction. As input, NeRFs require multi-view images with corresponding camera poses as well as the interior orientation. In the typical NeRF workflow, the camera poses and the interior orientation are estimated in advance with Structure from Motion (SfM). But the quality of the resulting novel views, which depends on different parameters such as the number and distribution of available images, as well as the accuracy of the related camera poses and interior orientation, is difficult to predict. In addition, SfM is a time-consuming pre-processing step, and its quality strongly depends on the image content. Furthermore, the undefined scaling factor of SfM hinders subsequent steps in which metric information is required. In this paper, we evaluate the potential of NeRFs for industrial robot applications. We propose an alternative to SfM pre-processing: we capture the input images with a calibrated camera that is attached to the end effector of an industrial robot and determine accurate camera poses with metric scale based on the robot kinematics. We then investigate the quality of the novel views by comparing them to ground truth, and by computing an internal quality measure based on ensemble methods. For evaluation purposes, we acquire multiple datasets that pose challenges for reconstruction typical of industrial applications, like reflective objects, poor texture, and fine structures. We show that the robot-based pose determination reaches similar accuracy as SfM in non-demanding cases, while having clear advantages in more challenging scenarios. Finally, we present first results of applying the ensemble method to estimate the quality of the synthetic novel view in the absence of a ground truth.
Uncertainty Quantification with Deep Ensembles for 6D Object Pose Estimation
Mar 12, 2024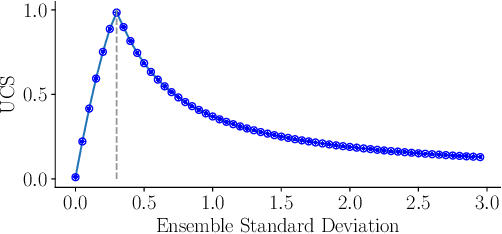
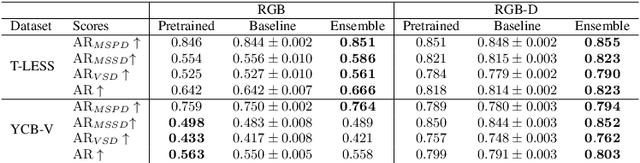
The estimation of 6D object poses is a fundamental task in many computer vision applications. Particularly, in high risk scenarios such as human-robot interaction, industrial inspection, and automation, reliable pose estimates are crucial. In the last years, increasingly accurate and robust deep-learning-based approaches for 6D object pose estimation have been proposed. Many top-performing methods are not end-to-end trainable but consist of multiple stages. In the context of deep uncertainty quantification, deep ensembles are considered as state of the art since they have been proven to produce well-calibrated and robust uncertainty estimates. However, deep ensembles can only be applied to methods that can be trained end-to-end. In this work, we propose a method to quantify the uncertainty of multi-stage 6D object pose estimation approaches with deep ensembles. For the implementation, we choose SurfEmb as representative, since it is one of the top-performing 6D object pose estimation approaches in the BOP Challenge 2022. We apply established metrics and concepts for deep uncertainty quantification to evaluate the results. Furthermore, we propose a novel uncertainty calibration score for regression tasks to quantify the quality of the estimated uncertainty.
Efficient Multi-task Uncertainties for Joint Semantic Segmentation and Monocular Depth Estimation
Feb 16, 2024
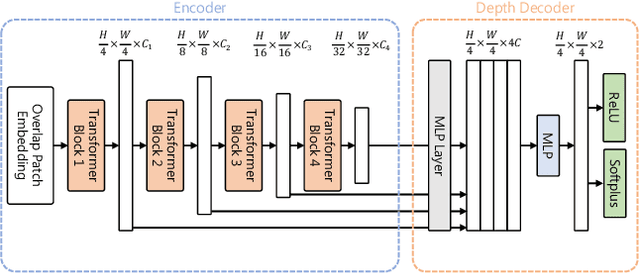
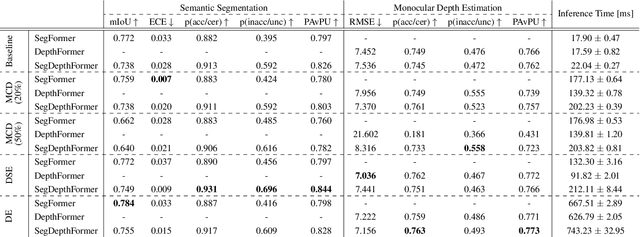
Quantifying the predictive uncertainty emerged as a possible solution to common challenges like overconfidence or lack of explainability and robustness of deep neural networks, albeit one that is often computationally expensive. Many real-world applications are multi-modal in nature and hence benefit from multi-task learning. In autonomous driving, for example, the joint solution of semantic segmentation and monocular depth estimation has proven to be valuable. In this work, we first combine different uncertainty quantification methods with joint semantic segmentation and monocular depth estimation and evaluate how they perform in comparison to each other. Additionally, we reveal the benefits of multi-task learning with regard to the uncertainty quality compared to solving both tasks separately. Based on these insights, we introduce EMUFormer, a novel student-teacher distillation approach for joint semantic segmentation and monocular depth estimation as well as efficient multi-task uncertainty quantification. By implicitly leveraging the predictive uncertainties of the teacher, EMUFormer achieves new state-of-the-art results on Cityscapes and NYUv2 and additionally estimates high-quality predictive uncertainties for both tasks that are comparable or superior to a Deep Ensemble despite being an order of magnitude more efficient.