 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Multi-task Uncertainties in Joint Semantic Segmentation and Monocular Depth Estimation
May 27, 2024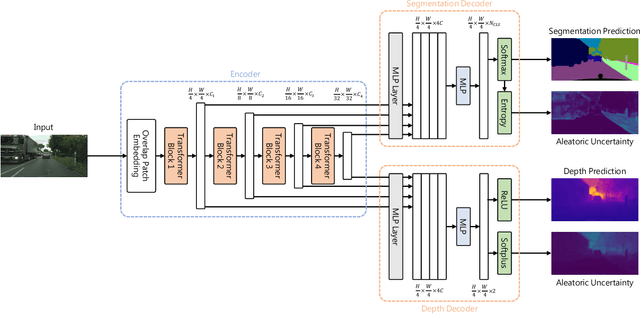
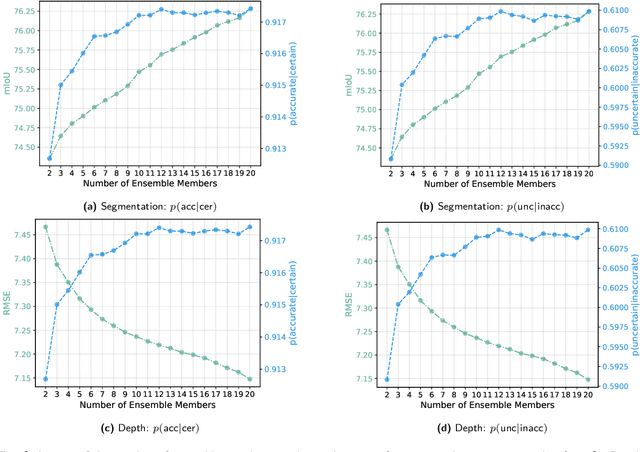
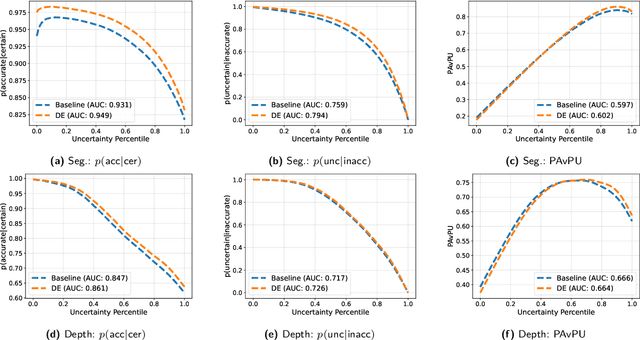
While a number of promising uncertainty quantification methods have been proposed to address the prevailing shortcomings of deep neural networks like overconfidence and lack of explainability, quantifying predictive uncertainties in the context of joint semantic segmentation and monocular depth estimation has not been explored yet. Since many real-world applications are multi-modal in nature and, hence, have the potential to benefit from multi-task learning, this is a substantial gap in current literature. To this end, we conduct a comprehensive series of experiments to study how multi-task learning influences the quality of uncertainty estimates in comparison to solving both tasks separately.
HoloGS: Instant Depth-based 3D Gaussian Splatting with Microsoft HoloLens 2
May 03, 2024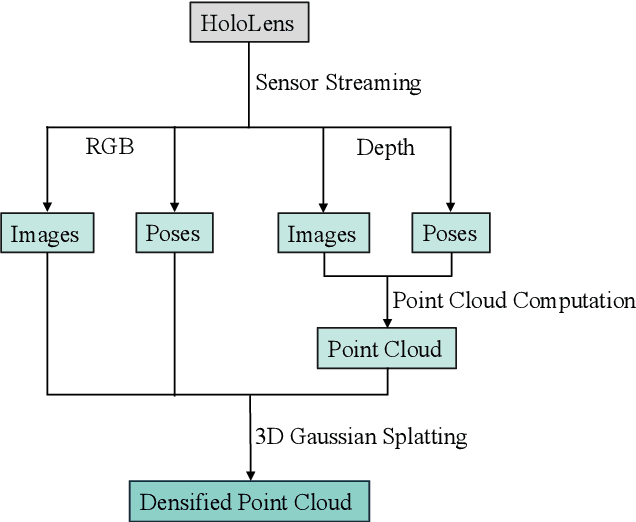


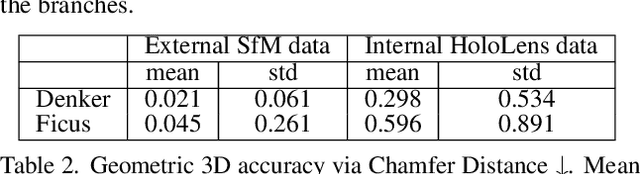
In the fields of photogrammetry, computer vision and computer graphics, the task of neural 3D scene reconstruction has led to the exploration of various techniques. Among these, 3D Gaussian Splatting stands out for its explicit representation of scenes using 3D Gaussians, making it appealing for tasks like 3D point cloud extraction and surface reconstruction. Motivated by its potential, we address the domain of 3D scene reconstruction, aiming to leverage the capabilities of the Microsoft HoloLens 2 for instant 3D Gaussian Splatting. We present HoloGS, a novel workflow utilizing HoloLens sensor data, which bypasses the need for pre-processing steps like Structure from Motion by instantly accessing the required input data i.e. the images, camera poses and the point cloud from depth sensing. We provide comprehensive investigations, including the training process and the rendering quality, assessed through the Peak Signal-to-Noise Ratio, and the geometric 3D accuracy of the densified point cloud from Gaussian centers, measured by Chamfer Distance. We evaluate our approach on two self-captured scenes: An outdoor scene of a cultural heritage statue and an indoor scene of a fine-structured plant. Our results show that the HoloLens data, including RGB images, corresponding camera poses, and depth sensing based point clouds to initialize the Gaussians, are suitable as input for 3D Gaussian Splatting.
Efficient Multi-task Uncertainties for Joint Semantic Segmentation and Monocular Depth Estimation
Feb 16, 2024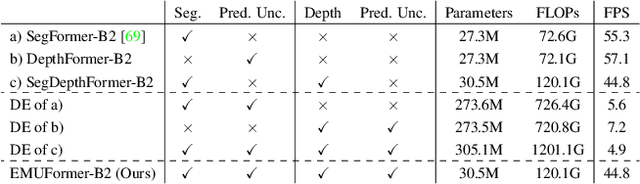
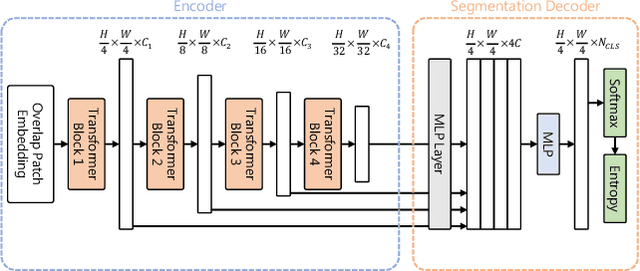
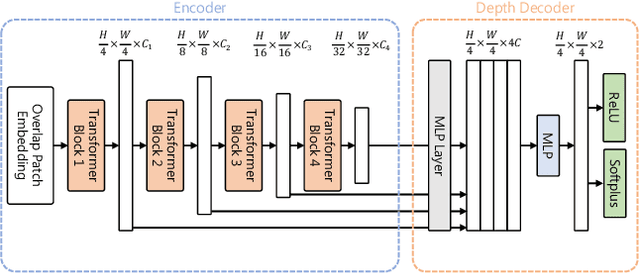
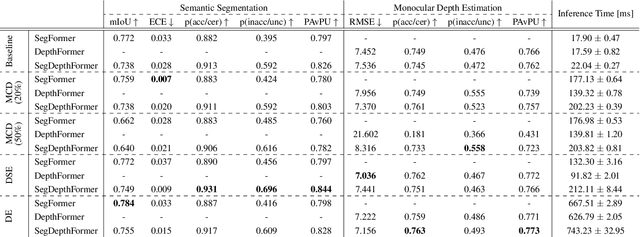
Quantifying the predictive uncertainty emerged as a possible solution to common challenges like overconfidence or lack of explainability and robustness of deep neural networks, albeit one that is often computationally expensive. Many real-world applications are multi-modal in nature and hence benefit from multi-task learning. In autonomous driving, for example, the joint solution of semantic segmentation and monocular depth estimation has proven to be valuable. In this work, we first combine different uncertainty quantification methods with joint semantic segmentation and monocular depth estimation and evaluate how they perform in comparison to each other. Additionally, we reveal the benefits of multi-task learning with regard to the uncertainty quality compared to solving both tasks separately. Based on these insights, we introduce EMUFormer, a novel student-teacher distillation approach for joint semantic segmentation and monocular depth estimation as well as efficient multi-task uncertainty quantification. By implicitly leveraging the predictive uncertainties of the teacher, EMUFormer achieves new state-of-the-art results on Cityscapes and NYUv2 and additionally estimates high-quality predictive uncertainties for both tasks that are comparable or superior to a Deep Ensemble despite being an order of magnitude more efficient.