 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Semi-supervised Segmentation Beyond Accuracy: Reliability and Robustness
Jun 06, 2025Semantic segmentation is critical for scene understanding but demands costly pixel-wise annotations, attracting increasing attention to semi-supervised approaches to leverage abundant unlabeled data. While semi-supervised segmentation is often promoted as a path toward scalable, real-world deployment, it is astonishing that current evaluation protocols exclusively focus on segmentation accuracy, entirely overlooking reliability and robustness. These qualities, which ensure consistent performance under diverse conditions (robustness) and well-calibrated model confidences as well as meaningful uncertainties (reliability), are essential for safety-critical applications like autonomous driving, where models must handle unpredictable environments and avoid sudden failures at all costs. To address this gap, we introduce the Reliable Segmentation Score (RSS), a novel metric that combines predictive accuracy, calibration, and uncertainty quality measures via a harmonic mean. RSS penalizes deficiencies in any of its components, providing an easy and intuitive way of holistically judging segmentation models. Comprehensive evaluations of UniMatchV2 against its predecessor and a supervised baseline show that semi-supervised methods often trade reliability for accuracy. While out-of-domain evaluations demonstrate UniMatchV2's robustness, they further expose persistent reliability shortcomings. We advocate for a shift in evaluation protocols toward more holistic metrics like RSS to better align semi-supervised learning research with real-world deployment needs.
FeatureGS: Eigenvalue-Feature Optimization in 3D Gaussian Splatting for Geometrically Accurate and Artifact-Reduced Reconstruction
Jan 29, 20253D Gaussian Splatting (3DGS) has emerged as a powerful approach for 3D scene reconstruction using 3D Gaussians. However, neither the centers nor surfaces of the Gaussians are accurately aligned to the object surface, complicating their direct use in point cloud and mesh reconstruction. Additionally, 3DGS typically produces floater artifacts, increasing the number of Gaussians and storage requirements. To address these issues, we present FeatureGS, which incorporates an additional geometric loss term based on an eigenvalue-derived 3D shape feature into the optimization process of 3DGS. The goal is to improve geometric accuracy and enhance properties of planar surfaces with reduced structural entropy in local 3D neighborhoods.We present four alternative formulations for the geometric loss term based on 'planarity' of Gaussians, as well as 'planarity', 'omnivariance', and 'eigenentropy' of Gaussian neighborhoods. We provide quantitative and qualitative evaluations on 15 scenes of the DTU benchmark dataset focusing on following key aspects: Geometric accuracy and artifact-reduction, measured by the Chamfer distance, and memory efficiency, evaluated by the total number of Gaussians. Additionally, rendering quality is monitored by Peak Signal-to-Noise Ratio. FeatureGS achieves a 30 % improvement in geometric accuracy, reduces the number of Gaussians by 90 %, and suppresses floater artifacts, while maintaining comparable photometric rendering quality. The geometric loss with 'planarity' from Gaussians provides the highest geometric accuracy, while 'omnivariance' in Gaussian neighborhoods reduces floater artifacts and number of Gaussians the most. This makes FeatureGS a strong method for geometrically accurate, artifact-reduced and memory-efficient 3D scene reconstruction, enabling the direct use of Gaussian centers for geometric representation.
Evaluation of Multi-task Uncertainties in Joint Semantic Segmentation and Monocular Depth Estimation
May 27, 2024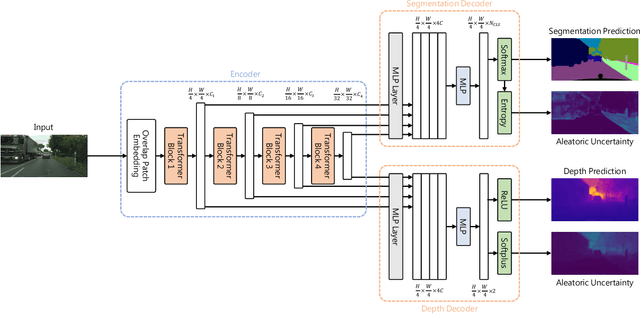
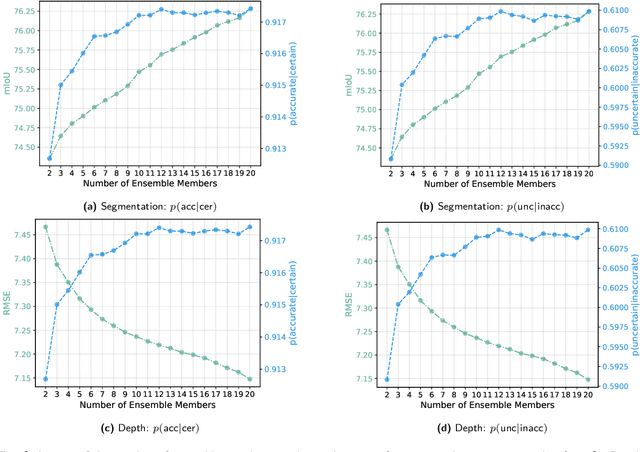
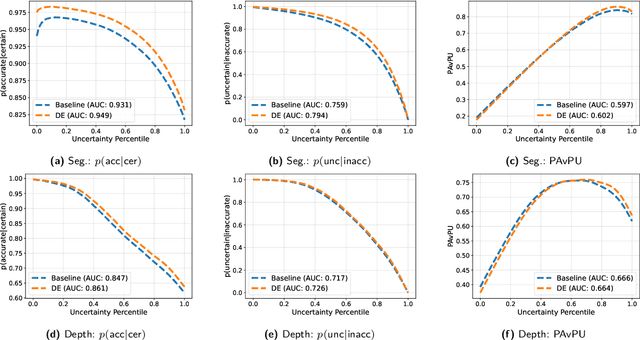
While a number of promising uncertainty quantification methods have been proposed to address the prevailing shortcomings of deep neural networks like overconfidence and lack of explainability, quantifying predictive uncertainties in the context of joint semantic segmentation and monocular depth estimation has not been explored yet. Since many real-world applications are multi-modal in nature and, hence, have the potential to benefit from multi-task learning, this is a substantial gap in current literature. To this end, we conduct a comprehensive series of experiments to study how multi-task learning influences the quality of uncertainty estimates in comparison to solving both tasks separately.
Novel View Synthesis with Neural Radiance Fields for Industrial Robot Applications
May 07, 2024Neural Radiance Fields (NeRFs) have become a rapidly growing research field with the potential to revolutionize typical photogrammetric workflows, such as those used for 3D scene reconstruction. As input, NeRFs require multi-view images with corresponding camera poses as well as the interior orientation. In the typical NeRF workflow, the camera poses and the interior orientation are estimated in advance with Structure from Motion (SfM). But the quality of the resulting novel views, which depends on different parameters such as the number and distribution of available images, as well as the accuracy of the related camera poses and interior orientation, is difficult to predict. In addition, SfM is a time-consuming pre-processing step, and its quality strongly depends on the image content. Furthermore, the undefined scaling factor of SfM hinders subsequent steps in which metric information is required. In this paper, we evaluate the potential of NeRFs for industrial robot applications. We propose an alternative to SfM pre-processing: we capture the input images with a calibrated camera that is attached to the end effector of an industrial robot and determine accurate camera poses with metric scale based on the robot kinematics. We then investigate the quality of the novel views by comparing them to ground truth, and by computing an internal quality measure based on ensemble methods. For evaluation purposes, we acquire multiple datasets that pose challenges for reconstruction typical of industrial applications, like reflective objects, poor texture, and fine structures. We show that the robot-based pose determination reaches similar accuracy as SfM in non-demanding cases, while having clear advantages in more challenging scenarios. Finally, we present first results of applying the ensemble method to estimate the quality of the synthetic novel view in the absence of a ground truth.
HoloGS: Instant Depth-based 3D Gaussian Splatting with Microsoft HoloLens 2
May 03, 2024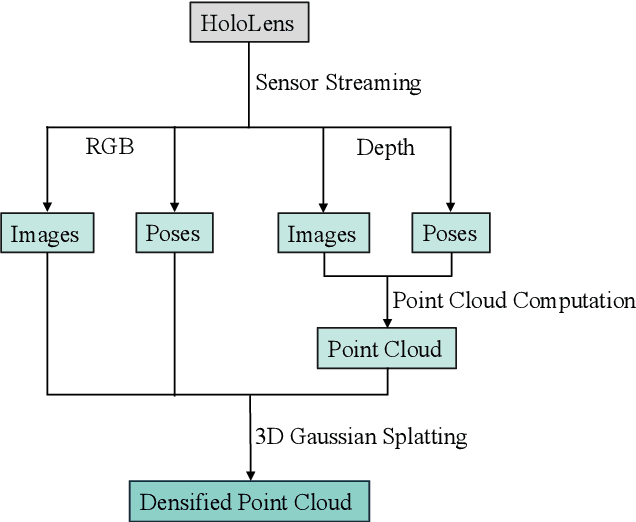


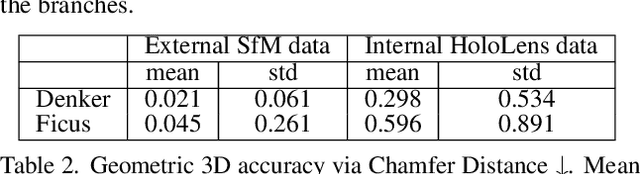
In the fields of photogrammetry, computer vision and computer graphics, the task of neural 3D scene reconstruction has led to the exploration of various techniques. Among these, 3D Gaussian Splatting stands out for its explicit representation of scenes using 3D Gaussians, making it appealing for tasks like 3D point cloud extraction and surface reconstruction. Motivated by its potential, we address the domain of 3D scene reconstruction, aiming to leverage the capabilities of the Microsoft HoloLens 2 for instant 3D Gaussian Splatting. We present HoloGS, a novel workflow utilizing HoloLens sensor data, which bypasses the need for pre-processing steps like Structure from Motion by instantly accessing the required input data i.e. the images, camera poses and the point cloud from depth sensing. We provide comprehensive investigations, including the training process and the rendering quality, assessed through the Peak Signal-to-Noise Ratio, and the geometric 3D accuracy of the densified point cloud from Gaussian centers, measured by Chamfer Distance. We evaluate our approach on two self-captured scenes: An outdoor scene of a cultural heritage statue and an indoor scene of a fine-structured plant. Our results show that the HoloLens data, including RGB images, corresponding camera poses, and depth sensing based point clouds to initialize the Gaussians, are suitable as input for 3D Gaussian Splatting.
Uncertainty Quantification with Deep Ensembles for 6D Object Pose Estimation
Mar 12, 2024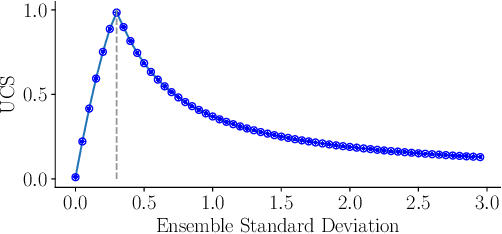
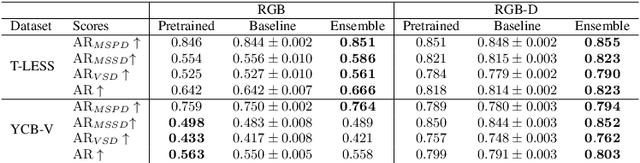
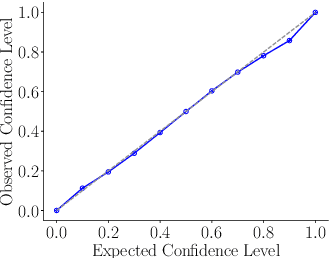
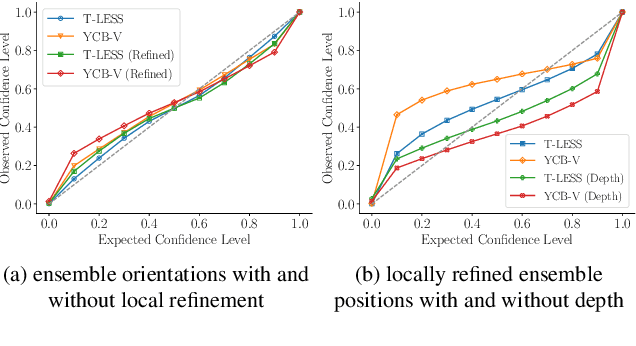
The estimation of 6D object poses is a fundamental task in many computer vision applications. Particularly, in high risk scenarios such as human-robot interaction, industrial inspection, and automation, reliable pose estimates are crucial. In the last years, increasingly accurate and robust deep-learning-based approaches for 6D object pose estimation have been proposed. Many top-performing methods are not end-to-end trainable but consist of multiple stages. In the context of deep uncertainty quantification, deep ensembles are considered as state of the art since they have been proven to produce well-calibrated and robust uncertainty estimates. However, deep ensembles can only be applied to methods that can be trained end-to-end. In this work, we propose a method to quantify the uncertainty of multi-stage 6D object pose estimation approaches with deep ensembles. For the implementation, we choose SurfEmb as representative, since it is one of the top-performing 6D object pose estimation approaches in the BOP Challenge 2022. We apply established metrics and concepts for deep uncertainty quantification to evaluate the results. Furthermore, we propose a novel uncertainty calibration score for regression tasks to quantify the quality of the estimated uncertainty.
Efficient Multi-task Uncertainties for Joint Semantic Segmentation and Monocular Depth Estimation
Feb 16, 2024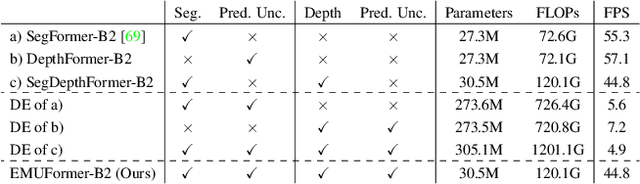
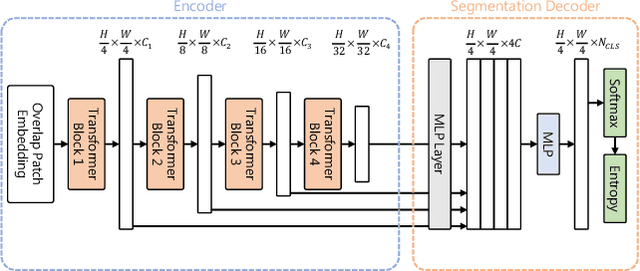
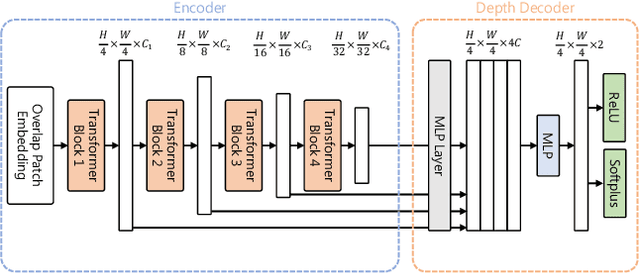
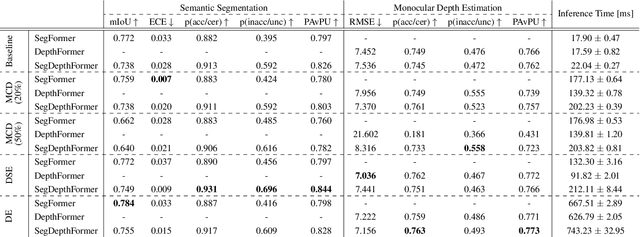
Quantifying the predictive uncertainty emerged as a possible solution to common challenges like overconfidence or lack of explainability and robustness of deep neural networks, albeit one that is often computationally expensive. Many real-world applications are multi-modal in nature and hence benefit from multi-task learning. In autonomous driving, for example, the joint solution of semantic segmentation and monocular depth estimation has proven to be valuable. In this work, we first combine different uncertainty quantification methods with joint semantic segmentation and monocular depth estimation and evaluate how they perform in comparison to each other. Additionally, we reveal the benefits of multi-task learning with regard to the uncertainty quality compared to solving both tasks separately. Based on these insights, we introduce EMUFormer, a novel student-teacher distillation approach for joint semantic segmentation and monocular depth estimation as well as efficient multi-task uncertainty quantification. By implicitly leveraging the predictive uncertainties of the teacher, EMUFormer achieves new state-of-the-art results on Cityscapes and NYUv2 and additionally estimates high-quality predictive uncertainties for both tasks that are comparable or superior to a Deep Ensemble despite being an order of magnitude more efficient.
U-CE: Uncertainty-aware Cross-Entropy for Semantic Segmentation
Jul 19, 2023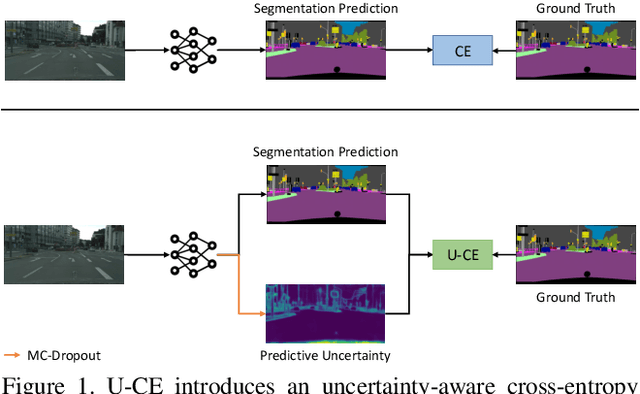

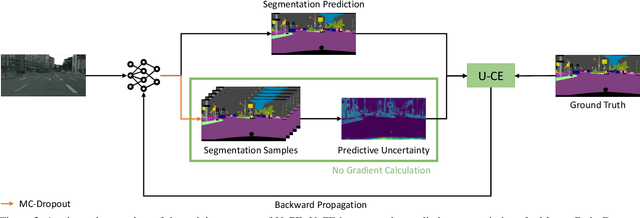
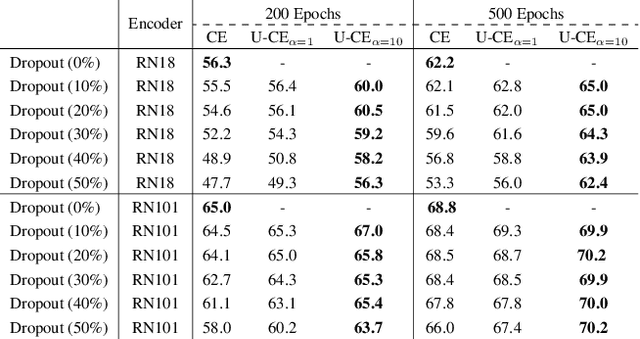
Deep neural networks have shown exceptional performance in various tasks, but their lack of robustness, reliability, and tendency to be overconfident pose challenges for their deployment in safety-critical applications like autonomous driving. In this regard, quantifying the uncertainty inherent to a model's prediction is a promising endeavour to address these shortcomings. In this work, we present a novel Uncertainty-aware Cross-Entropy loss (U-CE) that incorporates dynamic predictive uncertainties into the training process by pixel-wise weighting of the well-known cross-entropy loss (CE). Through extensive experimentation, we demonstrate the superiority of U-CE over regular CE training on two benchmark datasets, Cityscapes and ACDC, using two common backbone architectures, ResNet-18 and ResNet-101. With U-CE, we manage to train models that not only improve their segmentation performance but also provide meaningful uncertainties after training. Consequently, we contribute to the development of more robust and reliable segmentation models, ultimately advancing the state-of-the-art in safety-critical applications and beyond.
Segmentation of Industrial Burner Flames: A Comparative Study from Traditional Image Processing to Machine and Deep Learning
Jun 26, 2023
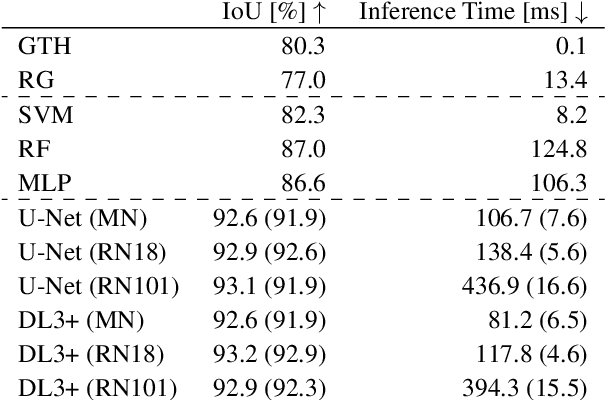
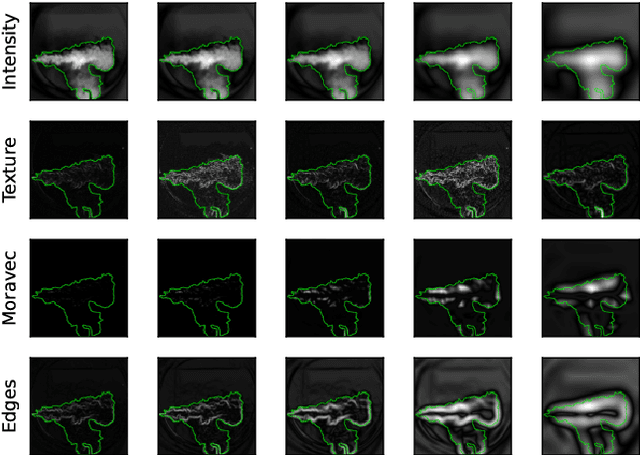
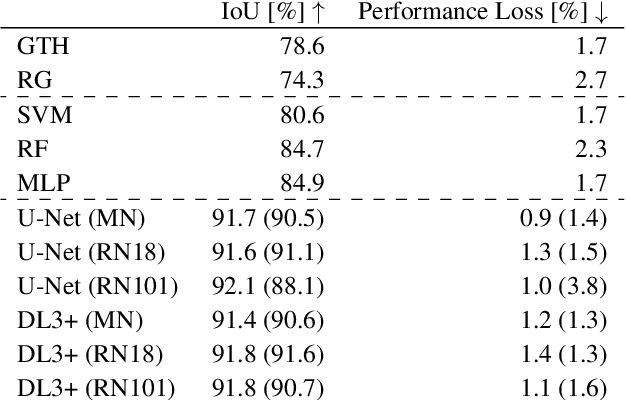
In many industrial processes, such as power generation, chemical production, and waste management, accurately monitoring industrial burner flame characteristics is crucial for safe and efficient operation. A key step involves separating the flames from the background through binary segmentation. Decades of machine vision research have produced a wide range of possible solutions, from traditional image processing to traditional machine learning and modern deep learning methods. In this work, we present a comparative study of multiple segmentation approaches, namely Global Thresholding, Region Growing, Support Vector Machines, Random Forest, Multilayer Perceptron, U-Net, and DeepLabV3+, that are evaluated on a public benchmark dataset of industrial burner flames. We provide helpful insights and guidance for researchers and practitioners aiming to select an appropriate approach for the binary segmentation of industrial burner flames and beyond. For the highest accuracy, deep learning is the leading approach, while for fast and simple solutions, traditional image processing techniques remain a viable option.
DUDES: Deep Uncertainty Distillation using Ensembles for Semantic Segmentation
Mar 17, 2023Deep neural networks lack interpretability and tend to be overconfident, which poses a serious problem in safety-critical applications like autonomous driving, medical imaging, or machine vision tasks with high demands on reliability. Quantifying the predictive uncertainty is a promising endeavour to open up the use of deep neural networks for such applications. Unfortunately, current available methods are computationally expensive. In this work, we present a novel approach for efficient and reliable uncertainty estimation which we call Deep Uncertainty Distillation using Ensembles for Segmentation (DUDES). DUDES applies student-teacher distillation with a Deep Ensemble to accurately approximate predictive uncertainties with a single forward pass while maintaining simplicity and adaptability. Experimentally, DUDES accurately captures predictive uncertainties without sacrificing performance on the segmentation task and indicates impressive capabilities of identifying wrongly classified pixels and out-of-domain samples on the Cityscapes dataset. With DUDES, we manage to simultaneously simplify and outperform previous work on Deep Ensemble-based Uncertainty Distillation.