 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3rd Workshop on Maritime Computer Vision (MaCVi) 2025: Challenge Results
Jan 17, 2025The 3rd Workshop on Maritime Computer Vision (MaCVi) 2025 addresses maritime computer vision for Unmanned Surface Vehicles (USV) and underwater. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 700 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi25.
Novel View Synthesis with Neural Radiance Fields for Industrial Robot Applications
May 07, 2024Neural Radiance Fields (NeRFs) have become a rapidly growing research field with the potential to revolutionize typical photogrammetric workflows, such as those used for 3D scene reconstruction. As input, NeRFs require multi-view images with corresponding camera poses as well as the interior orientation. In the typical NeRF workflow, the camera poses and the interior orientation are estimated in advance with Structure from Motion (SfM). But the quality of the resulting novel views, which depends on different parameters such as the number and distribution of available images, as well as the accuracy of the related camera poses and interior orientation, is difficult to predict. In addition, SfM is a time-consuming pre-processing step, and its quality strongly depends on the image content. Furthermore, the undefined scaling factor of SfM hinders subsequent steps in which metric information is required. In this paper, we evaluate the potential of NeRFs for industrial robot applications. We propose an alternative to SfM pre-processing: we capture the input images with a calibrated camera that is attached to the end effector of an industrial robot and determine accurate camera poses with metric scale based on the robot kinematics. We then investigate the quality of the novel views by comparing them to ground truth, and by computing an internal quality measure based on ensemble methods. For evaluation purposes, we acquire multiple datasets that pose challenges for reconstruction typical of industrial applications, like reflective objects, poor texture, and fine structures. We show that the robot-based pose determination reaches similar accuracy as SfM in non-demanding cases, while having clear advantages in more challenging scenarios. Finally, we present first results of applying the ensemble method to estimate the quality of the synthetic novel view in the absence of a ground truth.
The 2nd Workshop on Maritime Computer Vision 2024
Nov 23, 2023



The 2nd Workshop on Maritime Computer Vision (MaCVi) 2024 addresses maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicles (USV). Three challenges categories are considered: (i) UAV-based Maritime Object Tracking with Re-identification, (ii) USV-based Maritime Obstacle Segmentation and Detection, (iii) USV-based Maritime Boat Tracking. The USV-based Maritime Obstacle Segmentation and Detection features three sub-challenges, including a new embedded challenge addressing efficicent inference on real-world embedded devices. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 195 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi24.
Beyond single receptive field: A receptive field fusion-and-stratification network for airborne laser scanning point cloud classification
Jul 21, 2022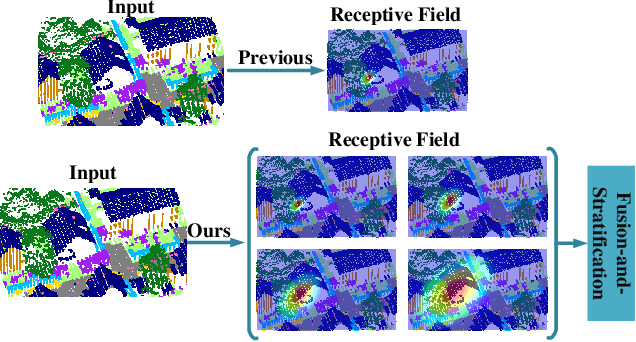

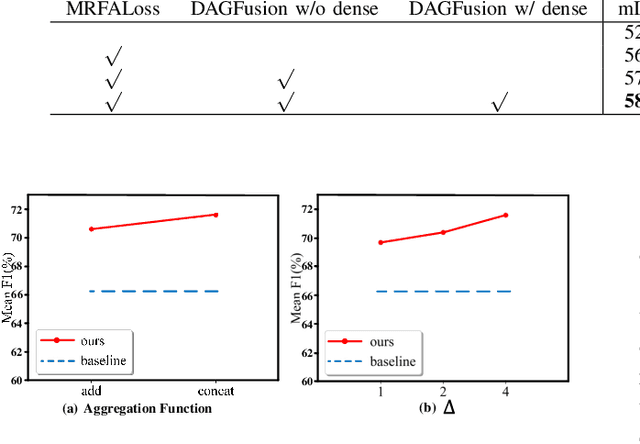
The classification of airborne laser scanning (ALS) point clouds is a critical task of remote sensing and photogrammetry fields. Although recent deep learning-based methods have achieved satisfactory performance, they have ignored the unicity of the receptive field, which makes the ALS point cloud classification remain challenging for the distinguishment of the areas with complex structures and extreme scale variations. In this article, for the objective of configuring multi-receptive field features, we propose a novel receptive field fusion-and-stratification network (RFFS-Net). With a novel dilated graph convolution (DGConv) and its extension annular dilated convolution (ADConv) as basic building blocks, the receptive field fusion process is implemented with the dilated and annular graph fusion (DAGFusion) module, which obtains multi-receptive field feature representation through capturing dilated and annular graphs with various receptive regions. The stratification of the receptive fields with point sets of different resolutions as the calculation bases is performed with Multi-level Decoders nested in RFFS-Net and driven by the multi-level receptive field aggregation loss (MRFALoss) to drive the network to learn in the direction of the supervision labels with different resolutions. With receptive field fusion-and-stratification, RFFS-Net is more adaptable to the classification of regions with complex structures and extreme scale variations in large-scale ALS point clouds. Evaluated on the ISPRS Vaihingen 3D dataset, our RFFS-Net significantly outperforms the baseline approach by 5.3% on mF1 and 5.4% on mIoU, accomplishing an overall accuracy of 82.1%, an mF1 of 71.6%, and an mIoU of 58.2%. Furthermore, experiments on the LASDU dataset and the 2019 IEEE-GRSS Data Fusion Contest dataset show that RFFS-Net achieves a new state-of-the-art classification performance.
FaSS-MVS -- Fast Multi-View Stereo with Surface-Aware Semi-Global Matching from UAV-borne Monocular Imagery
Dec 01, 2021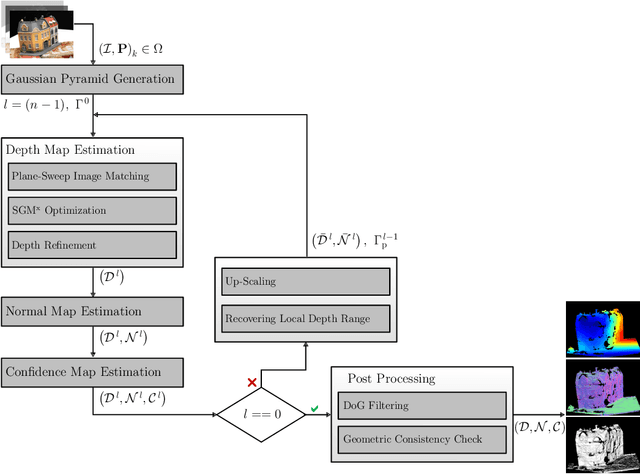

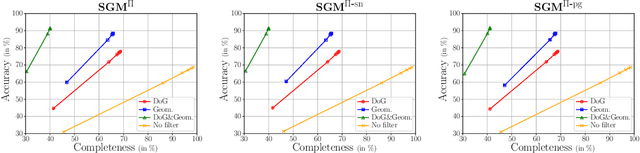
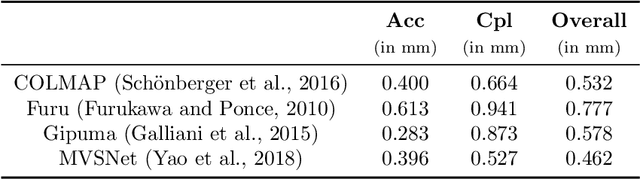
With FaSS-MVS, we present an approach for fast multi-view stereo with surface-aware Semi-Global Matching that allows for rapid depth and normal map estimation from monocular aerial video data captured by UAVs. The data estimated by FaSS-MVS, in turn, facilitates online 3D mapping, meaning that a 3D map of the scene is immediately and incrementally generated while the image data is acquired or being received. FaSS-MVS is comprised of a hierarchical processing scheme in which depth and normal data, as well as corresponding confidence scores, are estimated in a coarse-to-fine manner, allowing to efficiently process large scene depths which are inherent to oblique imagery captured by low-flying UAVs. The actual depth estimation employs a plane-sweep algorithm for dense multi-image matching to produce depth hypotheses from which the actual depth map is extracted by means of a surface-aware semi-global optimization, reducing the fronto-parallel bias of SGM. Given the estimated depth map, the pixel-wise surface normal information is then computed by reprojecting the depth map into a point cloud and calculating the normal vectors within a confined local neighborhood. In a thorough quantitative and ablative study we show that the accuracies of the 3D information calculated by FaSS-MVS is close to that of state-of-the-art approaches for offline multi-view stereo, with the error not even being one magnitude higher than that of COLMAP. At the same time, however, the average run-time of FaSS-MVS to estimate a single depth and normal map is less than 14 % of that of COLMAP, allowing to perform an online and incremental processing of Full-HD imagery at 1-2 Hz.
Pose Normalization of Indoor Mapping Datasets Partially Compliant to the Manhattan World Assumption
Jul 16, 2021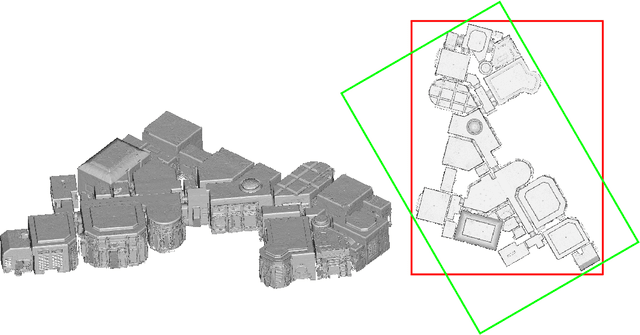
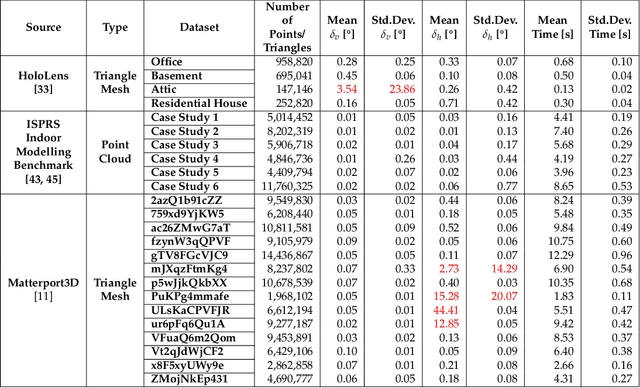
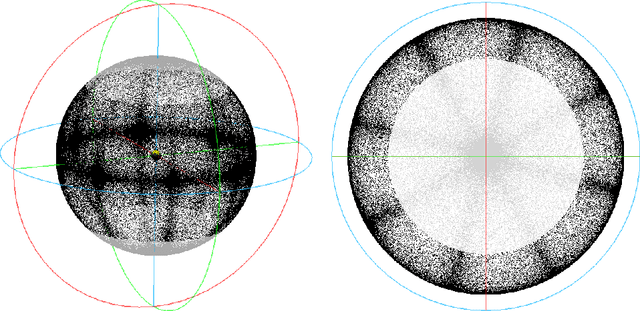
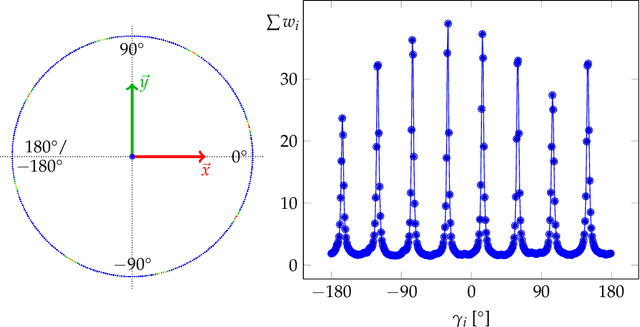
In this paper, we present a novel pose normalization method for indoor mapping point clouds and triangle meshes that is robust against large fractions of the indoor mapping geometries deviating from an ideal Manhattan World structure. In the case of building structures that contain multiple Manhattan World systems, the dominant Manhattan World structure supported by the largest fraction of geometries is determined and used for alignment. In a first step, a vertical alignment orienting a chosen axis to be orthogonal to horizontal floor and ceiling surfaces is conducted. Subsequently, a rotation around the resulting vertical axis is determined that aligns the dataset horizontally with the coordinate axes. The proposed method is evaluated quantitatively against several publicly available indoor mapping datasets. Our implementation of the proposed procedure along with code for reproducing the evaluation will be made available to the public upon acceptance for publication.
ReS2tAC -- UAV-Borne Real-Time SGM Stereo Optimized for Embedded ARM and CUDA Devices
Jun 15, 2021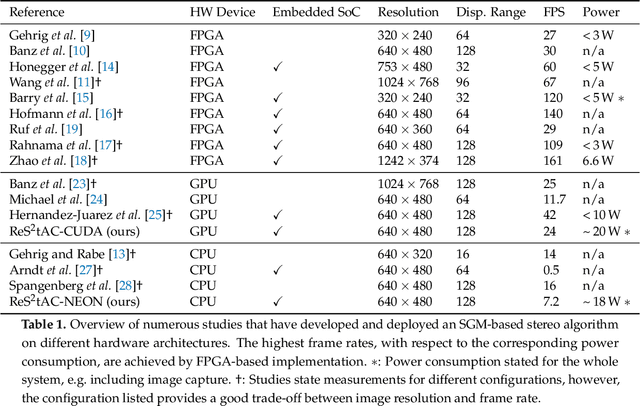



With the emergence of low-cost robotic systems, such as unmanned aerial vehicle, the importance of embedded high-performance image processing has increased. For a long time, FPGAs were the only processing hardware that were capable of high-performance computing, while at the same time preserving a low power consumption, essential for embedded systems. However, the recently increasing availability of embedded GPU-based systems, such as the NVIDIA Jetson series, comprised of an ARM CPU and a NVIDIA Tegra GPU, allows for massively parallel embedded computing on graphics hardware. With this in mind, we propose an approach for real-time embedded stereo processing on ARM and CUDA-enabled devices, which is based on the popular and widely used Semi-Global Matching algorithm. In this, we propose an optimization of the algorithm for embedded CUDA GPUs, by using massively parallel computing, as well as using the NEON intrinsics to optimize the algorithm for vectorized SIMD processing on embedded ARM CPUs. We have evaluated our approach with different configurations on two public stereo benchmark datasets to demonstrate that they can reach an error rate as low as 3.3%. Furthermore, our experiments show that the fastest configuration of our approach reaches up to 46 FPS on VGA image resolution. Finally, in a use-case specific qualitative evaluation, we have evaluated the power consumption of our approach and deployed it on the DJI Manifold 2-G attached to a DJI Matrix 210v2 RTK unmanned aerial vehicle (UAV), demonstrating its suitability for real-time stereo processing onboard a UAV.
Real-time dense 3D Reconstruction from monocular video data captured by low-cost UAVs
Apr 21, 2021

Real-time 3D reconstruction enables fast dense mapping of the environment which benefits numerous applications, such as navigation or live evaluation of an emergency. In contrast to most real-time capable approaches, our approach does not need an explicit depth sensor. Instead, we only rely on a video stream from a camera and its intrinsic calibration. By exploiting the self-motion of the unmanned aerial vehicle (UAV) flying with oblique view around buildings, we estimate both camera trajectory and depth for selected images with enough novel content. To create a 3D model of the scene, we rely on a three-stage processing chain. First, we estimate the rough camera trajectory using a simultaneous localization and mapping (SLAM) algorithm. Once a suitable constellation is found, we estimate depth for local bundles of images using a Multi-View Stereo (MVS) approach and then fuse this depth into a global surfel-based model. For our evaluation, we use 55 video sequences with diverse settings, consisting of both synthetic and real scenes. We evaluate not only the generated reconstruction but also the intermediate products and achieve competitive results both qualitatively and quantitatively. At the same time, our method can keep up with a 30 fps video for a resolution of 768x448 pixels.
FAIR1M: A Benchmark Dataset for Fine-grained Object Recognition in High-Resolution Remote Sensing Imagery
Mar 24, 2021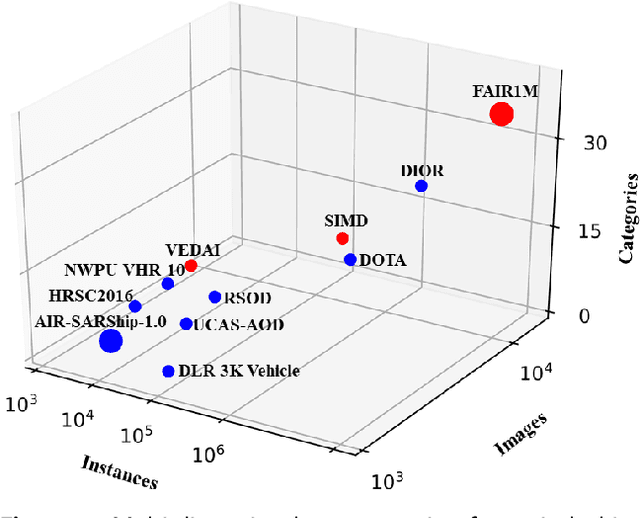
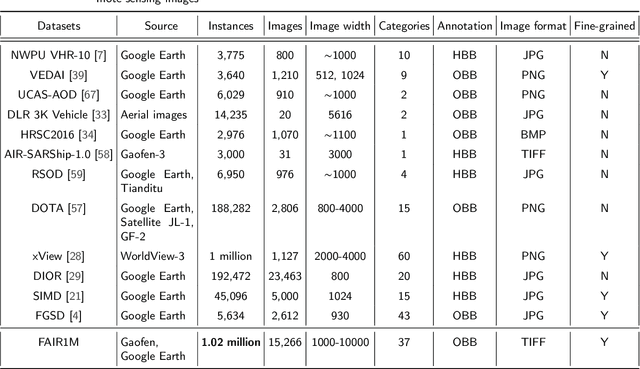
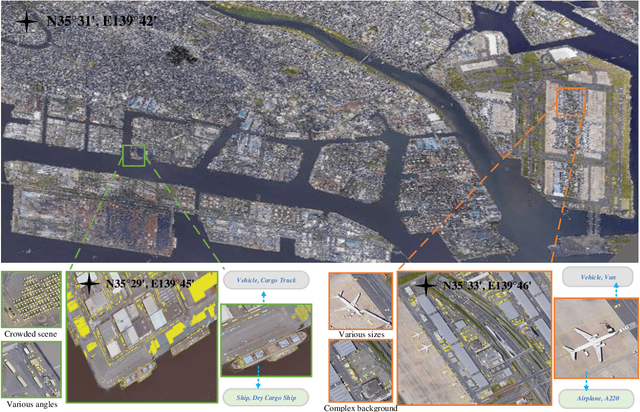
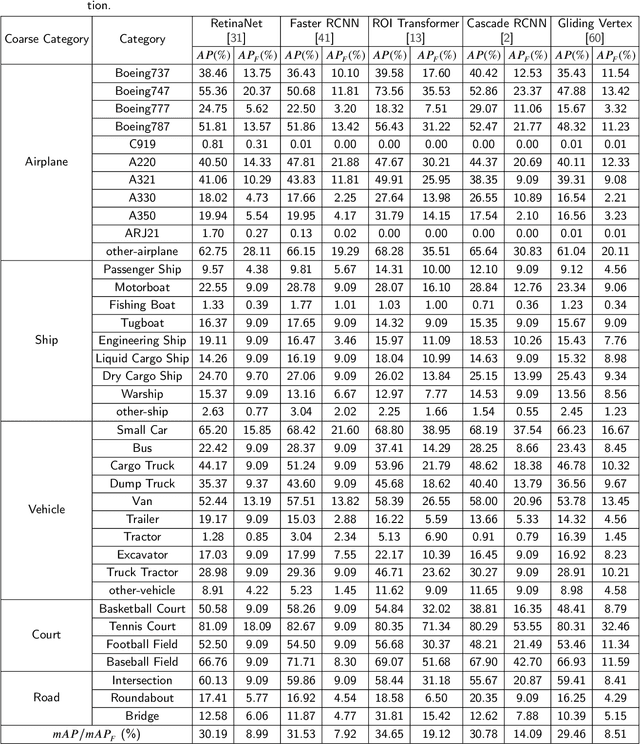
With the rapid development of deep learning, many deep learning-based approaches have made great achievements in object detection task. It is generally known that deep learning is a data-driven method. Data directly impact the performance of object detectors to some extent. Although existing datasets have included common objects in remote sensing images, they still have some limitations in terms of scale, categories, and images. Therefore, there is a strong requirement for establishing a large-scale benchmark on object detection in high-resolution remote sensing images. In this paper, we propose a novel benchmark dataset with more than 1 million instances and more than 15,000 images for Fine-grAined object recognItion in high-Resolution remote sensing imagery which is named as FAIR1M. All objects in the FAIR1M dataset are annotated with respect to 5 categories and 37 sub-categories by oriented bounding boxes. Compared with existing detection datasets dedicated to object detection, the FAIR1M dataset has 4 particular characteristics: (1) it is much larger than other existing object detection datasets both in terms of the quantity of instances and the quantity of images, (2) it provides more rich fine-grained category information for objects in remote sensing images, (3) it contains geographic information such as latitude, longitude and resolution, (4) it provides better image quality owing to a careful data cleaning procedure. To establish a baseline for fine-grained object recognition, we propose a novel evaluation method and benchmark fine-grained object detection tasks and a visual classification task using several State-Of-The-Art (SOTA) deep learning-based models on our FAIR1M dataset. Experimental results strongly indicate that the FAIR1M dataset is closer to practical application and it is considerably more challenging than existing datasets.
Self-Supervised Learning for Monocular Depth Estimation from Aerial Imagery
Aug 17, 2020
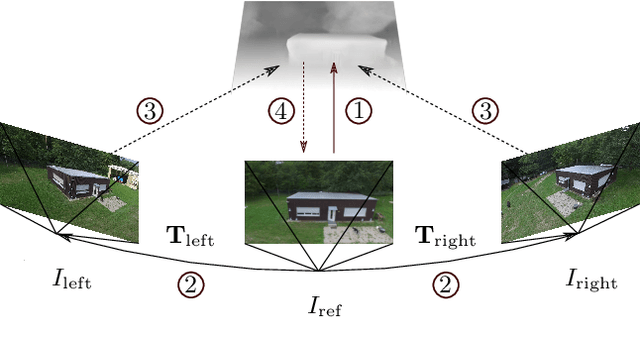

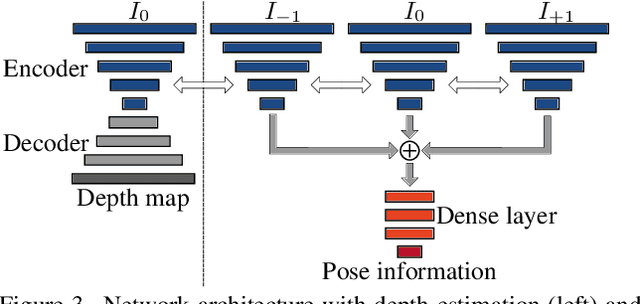
Supervised learning based methods for monocular depth estimation usually require large amounts of extensively annotated training data. In the case of aerial imagery, this ground truth is particularly difficult to acquire. Therefore, in this paper, we present a method for self-supervised learning for monocular depth estimation from aerial imagery that does not require annotated training data. For this, we only use an image sequence from a single moving camera and learn to simultaneously estimate depth and pose information. By sharing the weights between pose and depth estimation, we achieve a relatively small model, which favors real-time application. We evaluate our approach on three diverse datasets and compare the results to conventional methods that estimate depth maps based on multi-view geometry. We achieve an accuracy {\delta}1.25 of up to 93.5 %. In addition, we have paid particular attention to the generalization of a trained model to unknown data and the self-improving capabilities of our approach. We conclude that, even though the results of monocular depth estimation are inferior to those achieved by conventional methods, they are well suited to provide a good initialization for methods that rely on image matching or to provide estimates in regions where image matching fails, e.g. occluded or texture-less regions.