 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViRefSAM: Visual Reference-Guided Segment Anything Model for Remote Sensing Segmentation
Jul 03, 2025The Segment Anything Model (SAM), with its prompt-driven paradigm, exhibits strong generalization in generic segmentation tasks. However, applying SAM to remote sensing (RS) images still faces two major challenges. First, manually constructing precise prompts for each image (e.g., points or boxes) is labor-intensive and inefficient, especially in RS scenarios with dense small objects or spatially fragmented distributions. Second, SAM lacks domain adaptability, as it is pre-trained primarily on natural images and struggles to capture RS-specific semantics and spatial characteristics, especially when segmenting novel or unseen classes. To address these issues, inspired by few-shot learning, we propose ViRefSAM, a novel framework that guides SAM utilizing only a few annotated reference images that contain class-specific objects. Without requiring manual prompts, ViRefSAM enables automatic segmentation of class-consistent objects across RS images. Specifically, ViRefSAM introduces two key components while keeping SAM's original architecture intact: (1) a Visual Contextual Prompt Encoder that extracts class-specific semantic clues from reference images and generates object-aware prompts via contextual interaction with target images; and (2) a Dynamic Target Alignment Adapter, integrated into SAM's image encoder, which mitigates the domain gap by injecting class-specific semantics into target image features, enabling SAM to dynamically focus on task-relevant regions. Extensive experiments on three few-shot segmentation benchmarks, including iSAID-5$^i$, LoveDA-2$^i$, and COCO-20$^i$, demonstrate that ViRefSAM enables accurate and automatic segmentation of unseen classes by leveraging only a few reference images and consistently outperforms existing few-shot segmentation methods across diverse datasets.
RingMoE: Mixture-of-Modality-Experts Multi-Modal Foundation Models for Universal Remote Sensing Image Interpretation
Apr 04, 2025The rapid advancement of foundation models has revolutionized visual representation learning in a self-supervised manner. However, their application in remote sensing (RS) remains constrained by a fundamental gap: existing models predominantly handle single or limited modalities, overlooking the inherently multi-modal nature of RS observations. Optical, synthetic aperture radar (SAR), and multi-spectral data offer complementary insights that significantly reduce the inherent ambiguity and uncertainty in single-source analysis. To bridge this gap, we introduce RingMoE, a unified multi-modal RS foundation model with 14.7 billion parameters, pre-trained on 400 million multi-modal RS images from nine satellites. RingMoE incorporates three key innovations: (1) A hierarchical Mixture-of-Experts (MoE) architecture comprising modal-specialized, collaborative, and shared experts, effectively modeling intra-modal knowledge while capturing cross-modal dependencies to mitigate conflicts between modal representations; (2) Physics-informed self-supervised learning, explicitly embedding sensor-specific radiometric characteristics into the pre-training objectives; (3) Dynamic expert pruning, enabling adaptive model compression from 14.7B to 1B parameters while maintaining performance, facilitating efficient deployment in Earth observation applications. Evaluated across 23 benchmarks spanning six key RS tasks (i.e., classification, detection, segmentation, tracking, change detection, and depth estimation), RingMoE outperforms existing foundation models and sets new SOTAs, demonstrating remarkable adaptability from single-modal to multi-modal scenarios. Beyond theoretical progress, it has been deployed and trialed in multiple sectors, including emergency response, land management, marine sciences, and urban planning.
AgMTR: Agent Mining Transformer for Few-shot Segmentation in Remote Sensing
Sep 26, 2024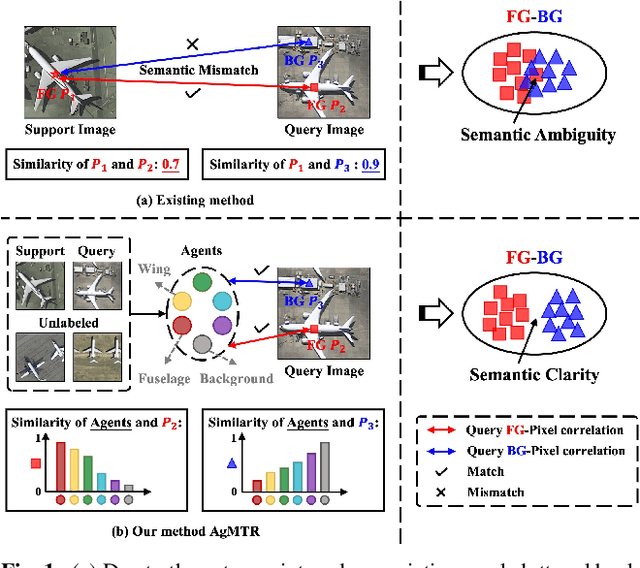
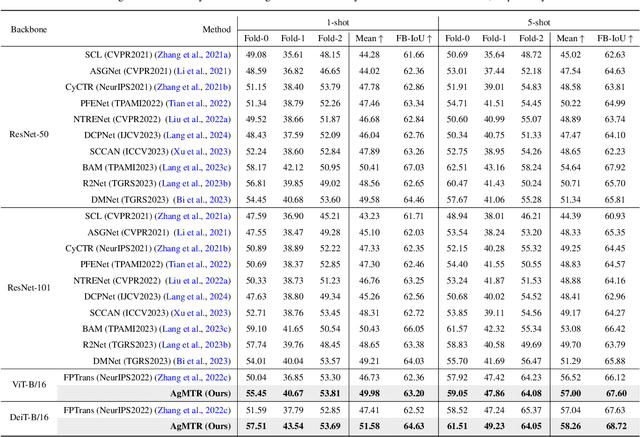
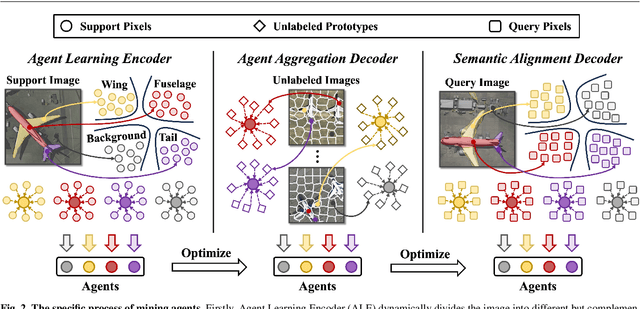
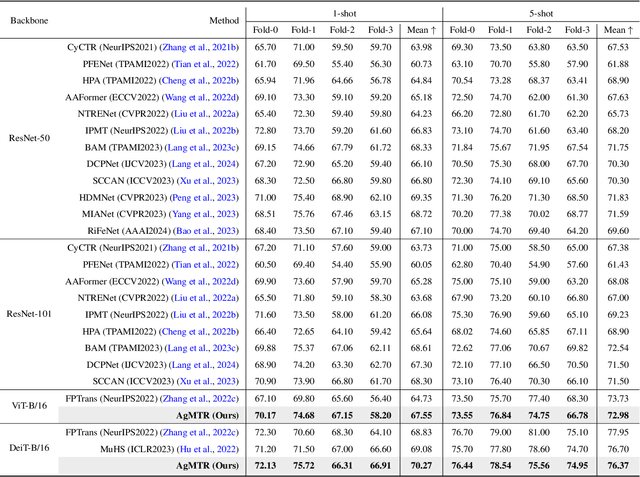
Few-shot Segmentation (FSS) aims to segment the interested objects in the query image with just a handful of labeled samples (i.e., support images). Previous schemes would leverage the similarity between support-query pixel pairs to construct the pixel-level semantic correlation. However, in remote sensing scenarios with extreme intra-class variations and cluttered backgrounds, such pixel-level correlations may produce tremendous mismatches, resulting in semantic ambiguity between the query foreground (FG) and background (BG) pixels. To tackle this problem, we propose a novel Agent Mining Transformer (AgMTR), which adaptively mines a set of local-aware agents to construct agent-level semantic correlation. Compared with pixel-level semantics, the given agents are equipped with local-contextual information and possess a broader receptive field. At this point, different query pixels can selectively aggregate the fine-grained local semantics of different agents, thereby enhancing the semantic clarity between query FG and BG pixels. Concretely, the Agent Learning Encoder (ALE) is first proposed to erect the optimal transport plan that arranges different agents to aggregate support semantics under different local regions. Then, for further optimizing the agents, the Agent Aggregation Decoder (AAD) and the Semantic Alignment Decoder (SAD) are constructed to break through the limited support set for mining valuable class-specific semantics from unlabeled data sources and the query image itself, respectively. Extensive experiments on the remote sensing benchmark iSAID indicate that the proposed method achieves state-of-the-art performance. Surprisingly, our method remains quite competitive when extended to more common natural scenarios, i.e., PASCAL-5i and COCO-20i.
Prompt-and-Transfer: Dynamic Class-aware Enhancement for Few-shot Segmentation
Sep 16, 2024For more efficient generalization to unseen domains (classes), most Few-shot Segmentation (FSS) would directly exploit pre-trained encoders and only fine-tune the decoder, especially in the current era of large models. However, such fixed feature encoders tend to be class-agnostic, inevitably activating objects that are irrelevant to the target class. In contrast, humans can effortlessly focus on specific objects in the line of sight. This paper mimics the visual perception pattern of human beings and proposes a novel and powerful prompt-driven scheme, called ``Prompt and Transfer" (PAT), which constructs a dynamic class-aware prompting paradigm to tune the encoder for focusing on the interested object (target class) in the current task. Three key points are elaborated to enhance the prompting: 1) Cross-modal linguistic information is introduced to initialize prompts for each task. 2) Semantic Prompt Transfer (SPT) that precisely transfers the class-specific semantics within the images to prompts. 3) Part Mask Generator (PMG) that works in conjunction with SPT to adaptively generate different but complementary part prompts for different individuals. Surprisingly, PAT achieves competitive performance on 4 different tasks including standard FSS, Cross-domain FSS (e.g., CV, medical, and remote sensing domains), Weak-label FSS, and Zero-shot Segmentation, setting new state-of-the-arts on 11 benchmarks.
TAFormer: A Unified Target-Aware Transformer for Video and Motion Joint Prediction in Aerial Scenes
Mar 27, 2024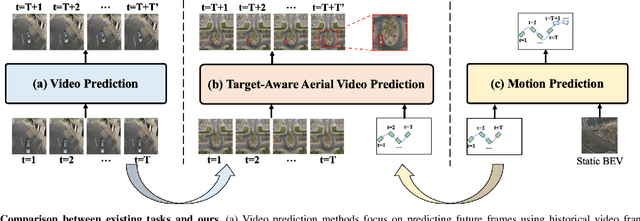
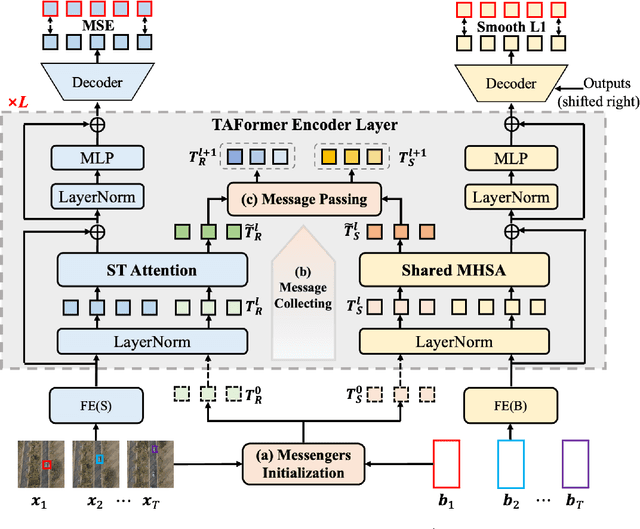
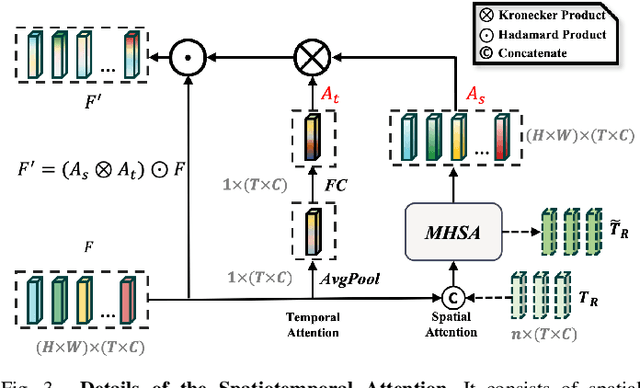
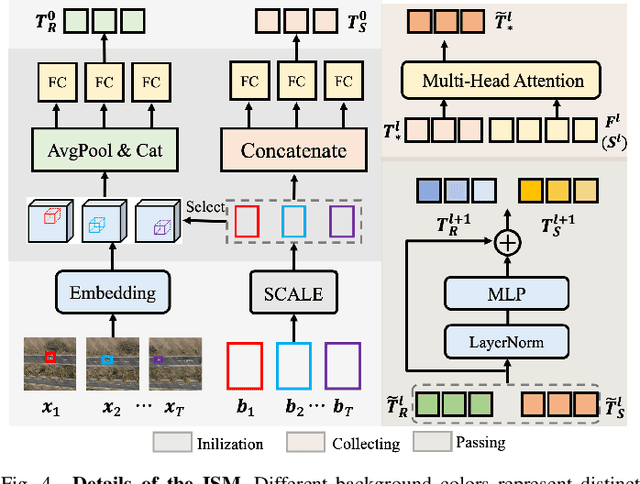
As drone technology advances, using unmanned aerial vehicles for aerial surveys has become the dominant trend in modern low-altitude remote sensing. The surge in aerial video data necessitates accurate prediction for future scenarios and motion states of the interested target, particularly in applications like traffic management and disaster response. Existing video prediction methods focus solely on predicting future scenes (video frames), suffering from the neglect of explicitly modeling target's motion states, which is crucial for aerial video interpretation. To address this issue, we introduce a novel task called Target-Aware Aerial Video Prediction, aiming to simultaneously predict future scenes and motion states of the target. Further, we design a model specifically for this task, named TAFormer, which provides a unified modeling approach for both video and target motion states. Specifically, we introduce Spatiotemporal Attention (STA), which decouples the learning of video dynamics into spatial static attention and temporal dynamic attention, effectively modeling the scene appearance and motion. Additionally, we design an Information Sharing Mechanism (ISM), which elegantly unifies the modeling of video and target motion by facilitating information interaction through two sets of messenger tokens. Moreover, to alleviate the difficulty of distinguishing targets in blurry predictions, we introduce Target-Sensitive Gaussian Loss (TSGL), enhancing the model's sensitivity to both target's position and content. Extensive experiments on UAV123VP and VisDroneVP (derived from single-object tracking datasets) demonstrate the exceptional performance of TAFormer in target-aware video prediction, showcasing its adaptability to the additional requirements of aerial video interpretation for target awareness.
Self-guided Few-shot Semantic Segmentation for Remote Sensing Imagery Based on Large Vision Models
Nov 22, 2023

The Segment Anything Model (SAM) exhibits remarkable versatility and zero-shot learning abilities, owing largely to its extensive training data (SA-1B). Recognizing SAM's dependency on manual guidance given its category-agnostic nature, we identified unexplored potential within few-shot semantic segmentation tasks for remote sensing imagery. This research introduces a structured framework designed for the automation of few-shot semantic segmentation. It utilizes the SAM model and facilitates a more efficient generation of semantically discernible segmentation outcomes. Central to our methodology is a novel automatic prompt learning approach, leveraging prior guided masks to produce coarse pixel-wise prompts for SAM. Extensive experiments on the DLRSD datasets underline the superiority of our approach, outperforming other available few-shot methodologies.
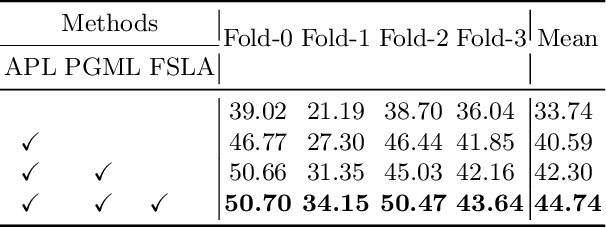
Not Just Learning from Others but Relying on Yourself: A New Perspective on Few-Shot Segmentation in Remote Sensing
Oct 19, 2023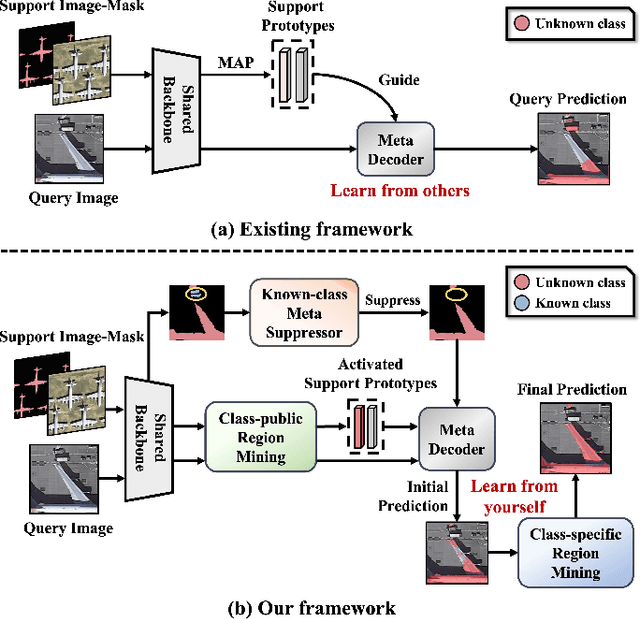


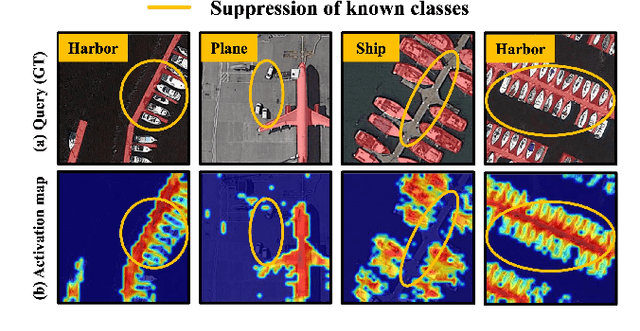
Few-shot segmentation (FSS) is proposed to segment unknown class targets with just a few annotated samples. Most current FSS methods follow the paradigm of mining the semantics from the support images to guide the query image segmentation. However, such a pattern of `learning from others' struggles to handle the extreme intra-class variation, preventing FSS from being directly generalized to remote sensing scenes. To bridge the gap of intra-class variance, we develop a Dual-Mining network named DMNet for cross-image mining and self-mining, meaning that it no longer focuses solely on support images but pays more attention to the query image itself. Specifically, we propose a Class-public Region Mining (CPRM) module to effectively suppress irrelevant feature pollution by capturing the common semantics between the support-query image pair. The Class-specific Region Mining (CSRM) module is then proposed to continuously mine the class-specific semantics of the query image itself in a `filtering' and `purifying' manner. In addition, to prevent the co-existence of multiple classes in remote sensing scenes from exacerbating the collapse of FSS generalization, we also propose a new Known-class Meta Suppressor (KMS) module to suppress the activation of known-class objects in the sample. Extensive experiments on the iSAID and LoveDA remote sensing datasets have demonstrated that our method sets the state-of-the-art with a minimum number of model parameters. Significantly, our model with the backbone of Resnet-50 achieves the mIoU of 49.58% and 51.34% on iSAID under 1-shot and 5-shot settings, outperforming the state-of-the-art method by 1.8% and 1.12%, respectively. The code is publicly available at https://github.com/HanboBizl/DMNet.
HeightFormer: A Multilevel Interaction and Image-adaptive Classification-regression Network for Monocular Height Estimation with Aerial Images
Oct 12, 2023



Height estimation has long been a pivotal topic within measurement and remote sensing disciplines, proving critical for endeavours such as 3D urban modelling, MR and autonomous driving. Traditional methods utilise stereo matching or multisensor fusion, both well-established techniques that typically necessitate multiple images from varying perspectives and adjunct sensors like SAR, leading to substantial deployment costs. Single image height estimation has emerged as an attractive alternative, boasting a larger data source variety and simpler deployment. However, current methods suffer from limitations such as fixed receptive fields, a lack of global information interaction, leading to noticeable instance-level height deviations. The inherent complexity of height prediction can result in a blurry estimation of object edge depth when using mainstream regression methods based on fixed height division. This paper presents a comprehensive solution for monocular height estimation in remote sensing, termed HeightFormer, combining multilevel interactions and image-adaptive classification-regression. It features the Multilevel Interaction Backbone (MIB) and Image-adaptive Classification-regression Height Generator (ICG). MIB supplements the fixed sample grid in CNN of the conventional backbone network with tokens of different interaction ranges. It is complemented by a pixel-, patch-, and feature map-level hierarchical interaction mechanism, designed to relay spatial geometry information across different scales and introducing a global receptive field to enhance the quality of instance-level height estimation. The ICG dynamically generates height partition for each image and reframes the traditional regression task, using a refinement from coarse to fine classification-regression that significantly mitigates the innate ill-posedness issue and drastically improves edge sharpness.
Rethinking the Open-Loop Evaluation of End-to-End Autonomous Driving in nuScenes
May 17, 2023



Modern autonomous driving systems are typically divided into three main tasks: perception, prediction, and planning. The planning task involves predicting the trajectory of the ego vehicle based on inputs from both internal intention and the external environment, and manipulating the vehicle accordingly. Most existing works evaluate their performance on the nuScenes dataset using the L2 error and collision rate between the predicted trajectories and the ground truth. In this paper, we reevaluate these existing evaluation metrics and explore whether they accurately measure the superiority of different methods. Specifically, we design an MLP-based method that takes raw sensor data (e.g., past trajectory, velocity, etc.) as input and directly outputs the future trajectory of the ego vehicle, without using any perception or prediction information such as camera images or LiDAR. Surprisingly, such a simple method achieves state-of-the-art end-to-end planning performance on the nuScenes dataset, reducing the average L2 error by about 30%. We further conduct in-depth analysis and provide new insights into the factors that are critical for the success of the planning task on nuScenes dataset. Our observation also indicates that we need to rethink the current open-loop evaluation scheme of end-to-end autonomous driving in nuScenes. Codes are available at https://github.com/E2E-AD/AD-MLP.
OGMN: Occlusion-guided Multi-task Network for Object Detection in UAV Images
Apr 24, 2023



Occlusion between objects is one of the overlooked challenges for object detection in UAV images. Due to the variable altitude and angle of UAVs, occlusion in UAV images happens more frequently than that in natural scenes. Compared to occlusion in natural scene images, occlusion in UAV images happens with feature confusion problem and local aggregation characteristic. And we found that extracting or localizing occlusion between objects is beneficial for the detector to address this challenge. According to this finding, the occlusion localization task is introduced, which together with the object detection task constitutes our occlusion-guided multi-task network (OGMN). The OGMN contains the localization of occlusion and two occlusion-guided multi-task interactions. In detail, an occlusion estimation module (OEM) is proposed to precisely localize occlusion. Then the OGMN utilizes the occlusion localization results to implement occlusion-guided detection with two multi-task interactions. One interaction for the guide is between two task decoders to address the feature confusion problem, and an occlusion decoupling head (ODH) is proposed to replace the general detection head. Another interaction for guide is designed in the detection process according to local aggregation characteristic, and a two-phase progressive refinement process (TPP) is proposed to optimize the detection process. Extensive experiments demonstrate the effectiveness of our OGMN on the Visdrone and UAVDT datasets. In particular, our OGMN achieves 35.0% mAP on the Visdrone dataset and outperforms the baseline by 5.3%. And our OGMN provides a new insight for accurate occlusion localization and achieves competitive detection performance.