 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Sentence Embedding Model through Ranking Sentences Generation with Large Language Models
Feb 19, 2025Sentence embedding is essential for many NLP tasks, with contrastive learning methods achieving strong performance using annotated datasets like NLI. Yet, the reliance on manual labels limits scalability. Recent studies leverage large language models (LLMs) to generate sentence pairs, reducing annotation dependency. However, they overlook ranking information crucial for fine-grained semantic distinctions. To tackle this challenge, we propose a method for controlling the generation direction of LLMs in the latent space. Unlike unconstrained generation, the controlled approach ensures meaningful semantic divergence. Then, we refine exist sentence embedding model by integrating ranking information and semantic information. Experiments on multiple benchmarks demonstrate that our method achieves new SOTA performance with a modest cost in ranking sentence synthesis.
PerPO: Perceptual Preference Optimization via Discriminative Rewarding
Feb 05, 2025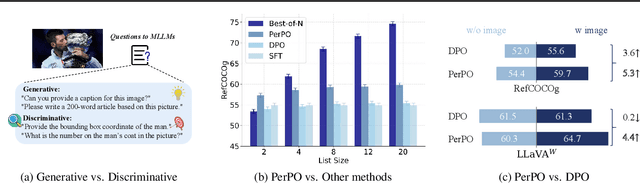
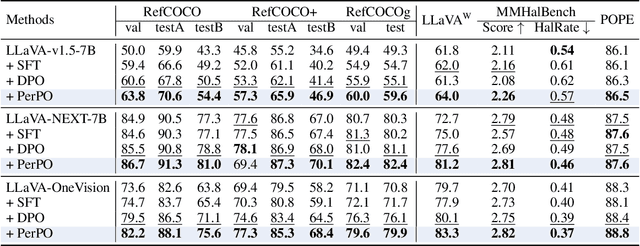
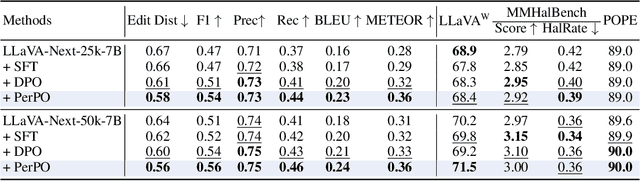
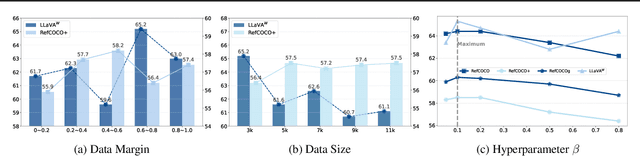
This paper presents Perceptual Preference Optimization (PerPO), a perception alignment method aimed at addressing the visual discrimination challenges in generative pre-trained multimodal large language models (MLLMs). To align MLLMs with human visual perception process, PerPO employs discriminative rewarding to gather diverse negative samples, followed by listwise preference optimization to rank them.By utilizing the reward as a quantitative margin for ranking, our method effectively bridges generative preference optimization and discriminative empirical risk minimization. PerPO significantly enhances MLLMs' visual discrimination capabilities while maintaining their generative strengths, mitigates image-unconditional reward hacking, and ensures consistent performance across visual tasks. This work marks a crucial step towards more perceptually aligned and versatile MLLMs. We also hope that PerPO will encourage the community to rethink MLLM alignment strategies.
Corner2Net: Detecting Objects as Cascade Corners
Nov 24, 2024



The corner-based detection paradigm enjoys the potential to produce high-quality boxes. But the development is constrained by three factors: 1) Hard to match corners. Heuristic corner matching algorithms can lead to incorrect boxes, especially when similar-looking objects co-occur. 2) Poor instance context. Two separate corners preserve few instance semantics, so it is difficult to guarantee getting both two class-specific corners on the same heatmap channel. 3) Unfriendly backbone. The training cost of the hourglass network is high. Accordingly, we build a novel corner-based framework, named Corner2Net. To achieve the corner-matching-free manner, we devise the cascade corner pipeline which progressively predicts the associated corner pair in two steps instead of synchronously searching two independent corners via parallel heads. Corner2Net decouples corner localization and object classification. Both two corners are class-agnostic and the instance-specific bottom-right corner further simplifies its search space. Meanwhile, RoI features with rich semantics are extracted for classification. Popular backbones (e.g., ResNeXt) can be easily connected to Corner2Net. Experimental results on COCO show Corner2Net surpasses all existing corner-based detectors by a large margin in accuracy and speed.
* This paper is accepted by 27th EUROPEAN CONFERENCE ON ARTIFICIAL INTELLIGENCE (ECAI 2024)
General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model
Sep 03, 2024
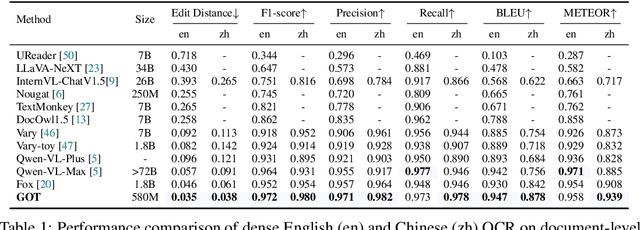
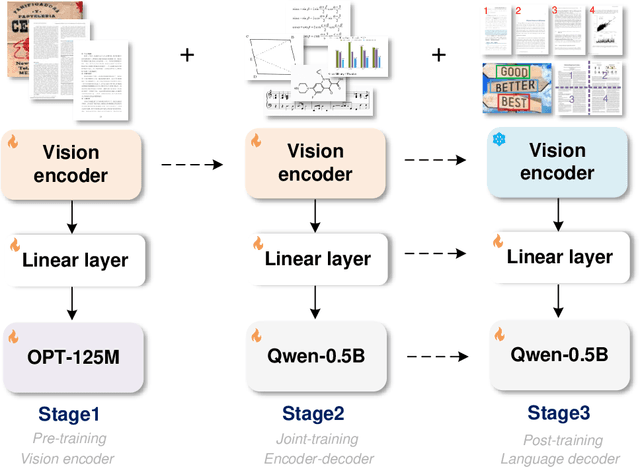

Traditional OCR systems (OCR-1.0) are increasingly unable to meet people's usage due to the growing demand for intelligent processing of man-made optical characters. In this paper, we collectively refer to all artificial optical signals (e.g., plain texts, math/molecular formulas, tables, charts, sheet music, and even geometric shapes) as "characters" and propose the General OCR Theory along with an excellent model, namely GOT, to promote the arrival of OCR-2.0. The GOT, with 580M parameters, is a unified, elegant, and end-to-end model, consisting of a high-compression encoder and a long-contexts decoder. As an OCR-2.0 model, GOT can handle all the above "characters" under various OCR tasks. On the input side, the model supports commonly used scene- and document-style images in slice and whole-page styles. On the output side, GOT can generate plain or formatted results (markdown/tikz/smiles/kern) via an easy prompt. Besides, the model enjoys interactive OCR features, i.e., region-level recognition guided by coordinates or colors. Furthermore, we also adapt dynamic resolution and multi-page OCR technologies to GOT for better practicality. In experiments, we provide sufficient results to prove the superiority of our model.
ReCon1M:A Large-scale Benchmark Dataset for Relation Comprehension in Remote Sensing Imagery
Jun 10, 2024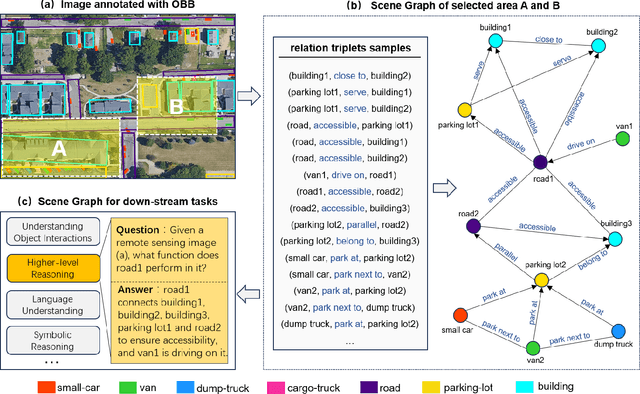
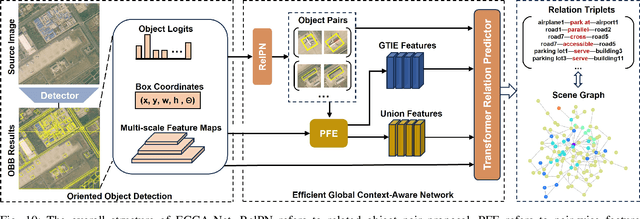
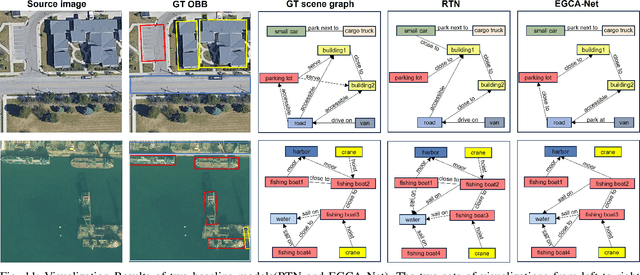
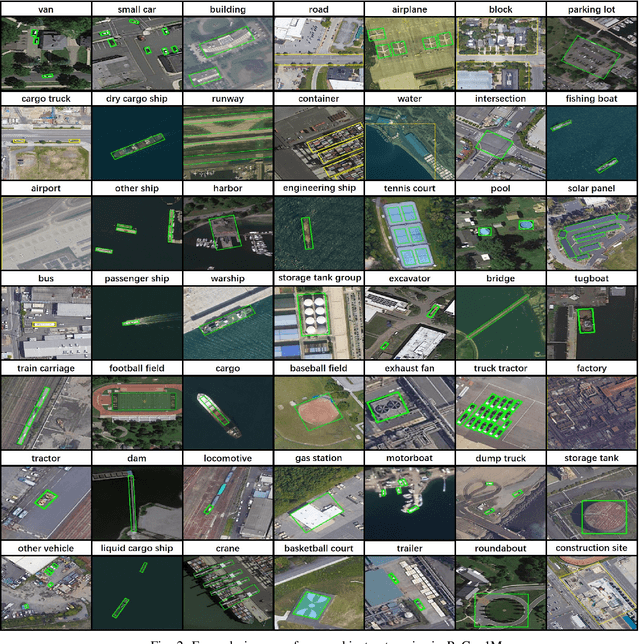
Scene Graph Generation (SGG) is a high-level visual understanding and reasoning task aimed at extracting entities (such as objects) and their interrelationships from images. Significant progress has been made in the study of SGG in natural images in recent years, but its exploration in the domain of remote sensing images remains very limited. The complex characteristics of remote sensing images necessitate higher time and manual interpretation costs for annotation compared to natural images. The lack of a large-scale public SGG benchmark is a major impediment to the advancement of SGG-related research in aerial imagery. In this paper, we introduce the first publicly available large-scale, million-level relation dataset in the field of remote sensing images which is named as ReCon1M. Specifically, our dataset is built upon Fair1M and comprises 21,392 images. It includes annotations for 859,751 object bounding boxes across 60 different categories, and 1,149,342 relation triplets across 64 categories based on these bounding boxes. We provide a detailed description of the dataset's characteristics and statistical information. We conducted two object detection tasks and three sub-tasks within SGG on this dataset, assessing the performance of mainstream methods on these tasks.
VIP: Versatile Image Outpainting Empowered by Multimodal Large Language Model
Jun 03, 2024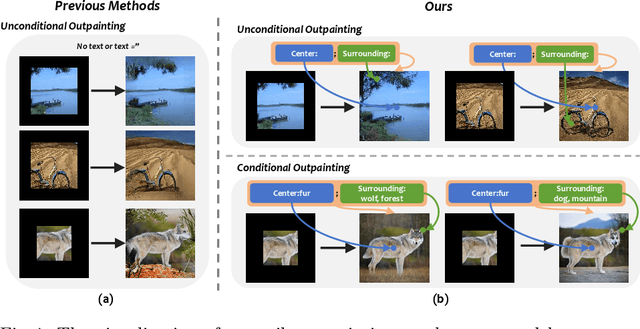
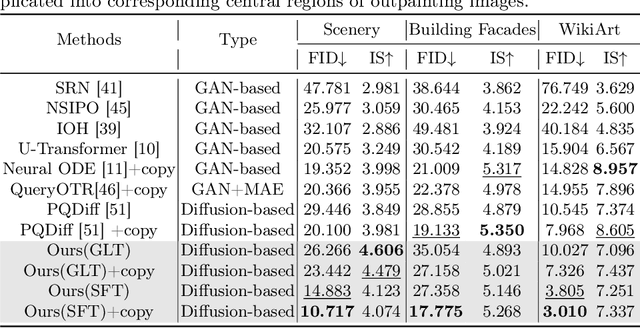
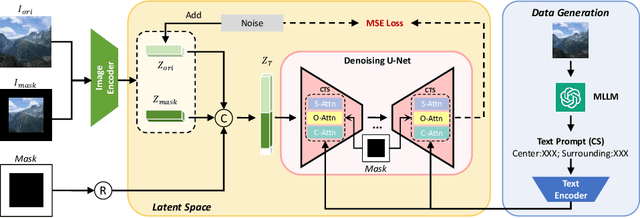
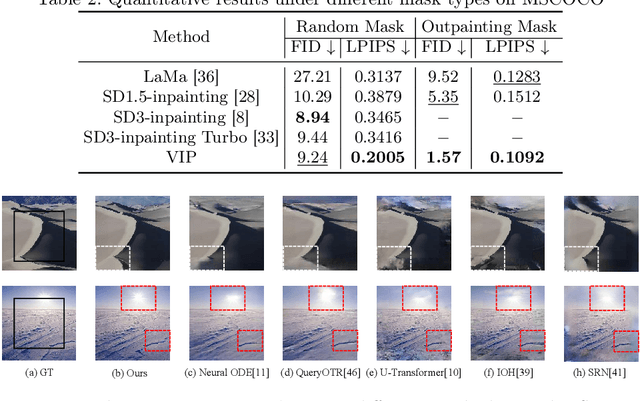
In this paper, we focus on resolving the problem of image outpainting, which aims to extrapolate the surrounding parts given the center contents of an image. Although recent works have achieved promising performance, the lack of versatility and customization hinders their practical applications in broader scenarios. Therefore, this work presents a novel image outpainting framework that is capable of customizing the results according to the requirement of users. First of all, we take advantage of a Multimodal Large Language Model (MLLM) that automatically extracts and organizes the corresponding textual descriptions of the masked and unmasked part of a given image. Accordingly, the obtained text prompts are introduced to endow our model with the capacity to customize the outpainting results. In addition, a special Cross-Attention module, namely Center-Total-Surrounding (CTS), is elaborately designed to enhance further the the interaction between specific space regions of the image and corresponding parts of the text prompts. Note that unlike most existing methods, our approach is very resource-efficient since it is just slightly fine-tuned on the off-the-shelf stable diffusion (SD) model rather than being trained from scratch. Finally, the experimental results on three commonly used datasets, i.e. Scenery, Building, and WikiArt, demonstrate our model significantly surpasses the SoTA methods. Moreover, versatile outpainting results are listed to show its customized ability.
Focus Anywhere for Fine-grained Multi-page Document Understanding
May 23, 2024



Modern LVLMs still struggle to achieve fine-grained document understanding, such as OCR/translation/caption for regions of interest to the user, tasks that require the context of the entire page, or even multiple pages. Accordingly, this paper proposes Fox, an effective pipeline, hybrid data, and tuning strategy, that catalyzes LVLMs to focus anywhere on single/multi-page documents. We introduce a novel task to boost the document understanding by making LVLMs focus attention on the document-level region, such as redefining full-page OCR as foreground focus. We employ multiple vision vocabularies to extract visual hybrid knowledge for interleaved document pages (e.g., a page containing a photo). Meanwhile, we render cross-vocabulary vision data as the catalyzer to achieve a full reaction of multiple visual vocabularies and in-document figure understanding. Further, without modifying the weights of multiple vision vocabularies, the above catalyzed fine-grained understanding capabilities can be efficiently tuned to multi-page documents, enabling the model to focus anywhere in both format-free and page-free manners. Besides, we build a benchmark including 9 fine-grained sub-tasks (e.g., region-level OCR/summary, color-guided OCR) to promote document analysis in the community. The experimental results verify the superiority of our model.
OneChart: Purify the Chart Structural Extraction via One Auxiliary Token
Apr 15, 2024


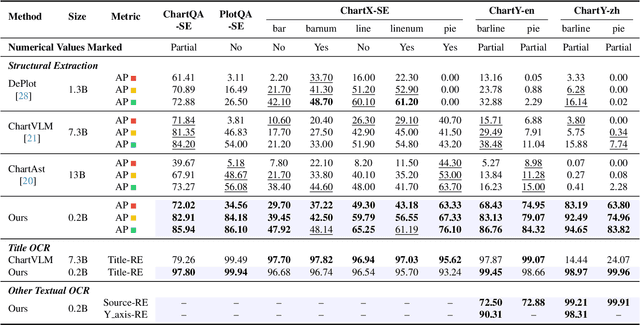
Chart parsing poses a significant challenge due to the diversity of styles, values, texts, and so forth. Even advanced large vision-language models (LVLMs) with billions of parameters struggle to handle such tasks satisfactorily. To address this, we propose OneChart: a reliable agent specifically devised for the structural extraction of chart information. Similar to popular LVLMs, OneChart incorporates an autoregressive main body. Uniquely, to enhance the reliability of the numerical parts of the output, we introduce an auxiliary token placed at the beginning of the total tokens along with an additional decoder. The numerically optimized (auxiliary) token allows subsequent tokens for chart parsing to capture enhanced numerical features through causal attention. Furthermore, with the aid of the auxiliary token, we have devised a self-evaluation mechanism that enables the model to gauge the reliability of its chart parsing results by providing confidence scores for the generated content. Compared to current state-of-the-art (SOTA) chart parsing models, e.g., DePlot, ChartVLM, ChartAst, OneChart significantly outperforms in Average Precision (AP) for chart structural extraction across multiple public benchmarks, despite enjoying only 0.2 billion parameters. Moreover, as a chart parsing agent, it also brings 10%+ accuracy gains for the popular LVLM (LLaVA-1.6) in the downstream ChartQA benchmark.
TAFormer: A Unified Target-Aware Transformer for Video and Motion Joint Prediction in Aerial Scenes
Mar 27, 2024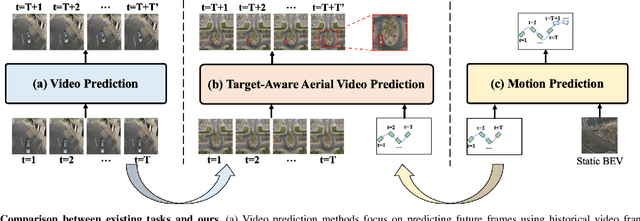
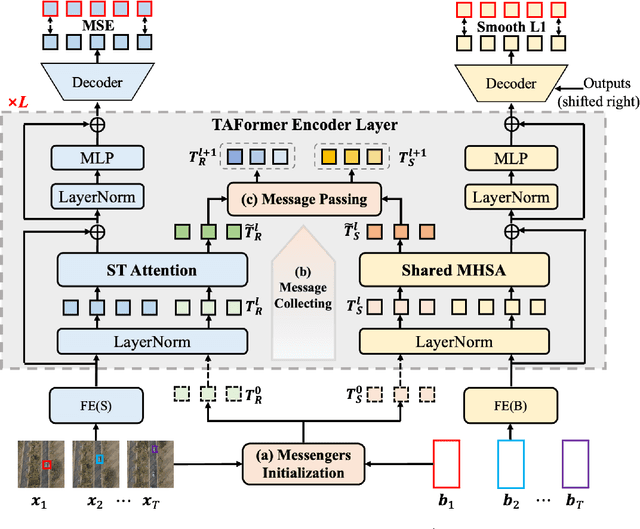
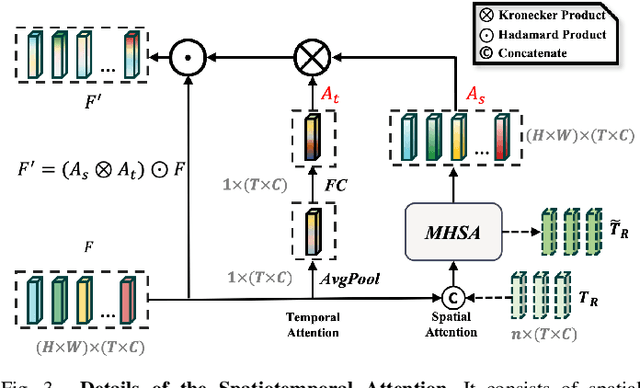
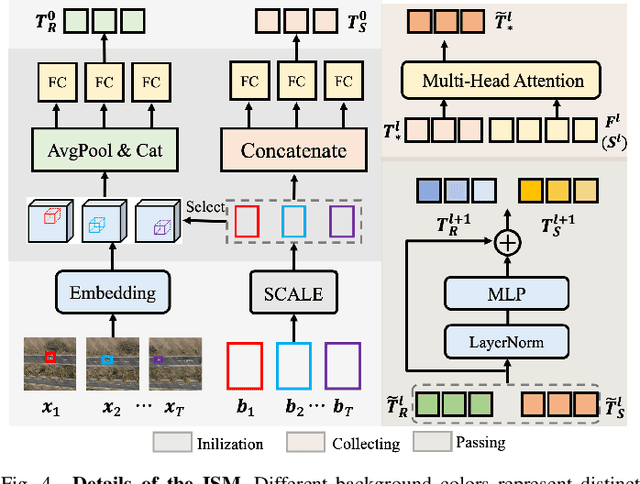
As drone technology advances, using unmanned aerial vehicles for aerial surveys has become the dominant trend in modern low-altitude remote sensing. The surge in aerial video data necessitates accurate prediction for future scenarios and motion states of the interested target, particularly in applications like traffic management and disaster response. Existing video prediction methods focus solely on predicting future scenes (video frames), suffering from the neglect of explicitly modeling target's motion states, which is crucial for aerial video interpretation. To address this issue, we introduce a novel task called Target-Aware Aerial Video Prediction, aiming to simultaneously predict future scenes and motion states of the target. Further, we design a model specifically for this task, named TAFormer, which provides a unified modeling approach for both video and target motion states. Specifically, we introduce Spatiotemporal Attention (STA), which decouples the learning of video dynamics into spatial static attention and temporal dynamic attention, effectively modeling the scene appearance and motion. Additionally, we design an Information Sharing Mechanism (ISM), which elegantly unifies the modeling of video and target motion by facilitating information interaction through two sets of messenger tokens. Moreover, to alleviate the difficulty of distinguishing targets in blurry predictions, we introduce Target-Sensitive Gaussian Loss (TSGL), enhancing the model's sensitivity to both target's position and content. Extensive experiments on UAV123VP and VisDroneVP (derived from single-object tracking datasets) demonstrate the exceptional performance of TAFormer in target-aware video prediction, showcasing its adaptability to the additional requirements of aerial video interpretation for target awareness.
Remote Sensing Image Change Detection with Graph Interaction
Jul 05, 2023Modern remote sensing image change detection has witnessed substantial advancements by harnessing the potent feature extraction capabilities of CNNs and Transforms.Yet,prevailing change detection techniques consistently prioritize extracting semantic features related to significant alterations,overlooking the viability of directly interacting with bitemporal image features.In this letter,we propose a bitemporal image graph Interaction network for remote sensing change detection,namely BGINet-CD. More specifically,by leveraging the concept of non-local operations and mapping the features obtained from the backbone network to the graph structure space,we propose a unified self-focus mechanism for bitemporal images.This approach enhances the information coupling between the two temporal images while effectively suppressing task-irrelevant interference,Based on a streamlined backbone architecture,namely ResNet18,our model demonstrates superior performance compared to other state-of-the-art methods (SOTA) on the GZ CD dataset. Moreover,the model exhibits an enhanced trade-off between accuracy and computational efficiency,further improving its overall effectiveness