 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerPO: Perceptual Preference Optimization via Discriminative Rewarding
Feb 05, 2025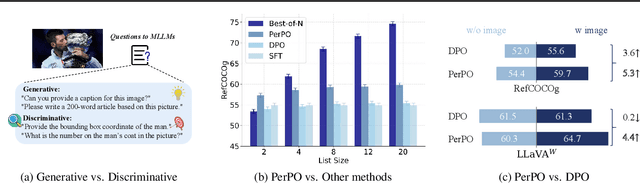
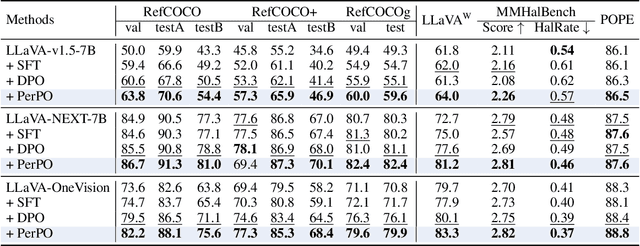
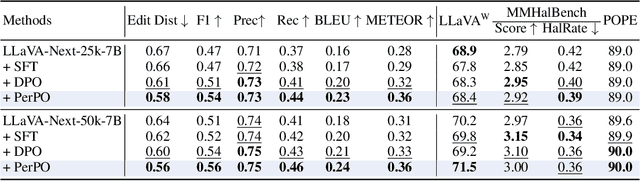
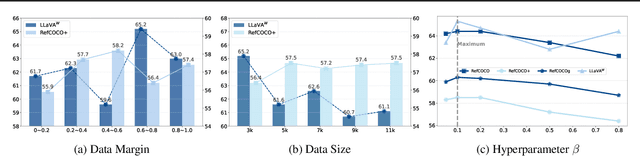
This paper presents Perceptual Preference Optimization (PerPO), a perception alignment method aimed at addressing the visual discrimination challenges in generative pre-trained multimodal large language models (MLLMs). To align MLLMs with human visual perception process, PerPO employs discriminative rewarding to gather diverse negative samples, followed by listwise preference optimization to rank them.By utilizing the reward as a quantitative margin for ranking, our method effectively bridges generative preference optimization and discriminative empirical risk minimization. PerPO significantly enhances MLLMs' visual discrimination capabilities while maintaining their generative strengths, mitigates image-unconditional reward hacking, and ensures consistent performance across visual tasks. This work marks a crucial step towards more perceptually aligned and versatile MLLMs. We also hope that PerPO will encourage the community to rethink MLLM alignment strategies.
Corner2Net: Detecting Objects as Cascade Corners
Nov 24, 2024



The corner-based detection paradigm enjoys the potential to produce high-quality boxes. But the development is constrained by three factors: 1) Hard to match corners. Heuristic corner matching algorithms can lead to incorrect boxes, especially when similar-looking objects co-occur. 2) Poor instance context. Two separate corners preserve few instance semantics, so it is difficult to guarantee getting both two class-specific corners on the same heatmap channel. 3) Unfriendly backbone. The training cost of the hourglass network is high. Accordingly, we build a novel corner-based framework, named Corner2Net. To achieve the corner-matching-free manner, we devise the cascade corner pipeline which progressively predicts the associated corner pair in two steps instead of synchronously searching two independent corners via parallel heads. Corner2Net decouples corner localization and object classification. Both two corners are class-agnostic and the instance-specific bottom-right corner further simplifies its search space. Meanwhile, RoI features with rich semantics are extracted for classification. Popular backbones (e.g., ResNeXt) can be easily connected to Corner2Net. Experimental results on COCO show Corner2Net surpasses all existing corner-based detectors by a large margin in accuracy and speed.
* This paper is accepted by 27th EUROPEAN CONFERENCE ON ARTIFICIAL INTELLIGENCE (ECAI 2024)
Hyperbolic Knowledge Transfer in Cross-Domain Recommendation System
Jun 25, 2024Cross-Domain Recommendation (CDR) seeks to utilize knowledge from different domains to alleviate the problem of data sparsity in the target recommendation domain, and it has been gaining more attention in recent years. Although there have been notable advancements in this area, most current methods represent users and items in Euclidean space, which is not ideal for handling long-tail distributed data in recommendation systems. Additionally, adding data from other domains can worsen the long-tail characteristics of the entire dataset, making it harder to train CDR models effectively. Recent studies have shown that hyperbolic methods are particularly suitable for modeling long-tail distributions, which has led us to explore hyperbolic representations for users and items in CDR scenarios. However, due to the distinct characteristics of the different domains, applying hyperbolic representation learning to CDR tasks is quite challenging. In this paper, we introduce a new framework called Hyperbolic Contrastive Learning (HCTS), designed to capture the unique features of each domain while enabling efficient knowledge transfer between domains. We achieve this by embedding users and items from each domain separately and mapping them onto distinct hyperbolic manifolds with adjustable curvatures for prediction. To improve the representations of users and items in the target domain, we develop a hyperbolic contrastive learning module for knowledge transfer. Extensive experiments on real-world datasets demonstrate that hyperbolic manifolds are a promising alternative to Euclidean space for CDR tasks.
VIP: Versatile Image Outpainting Empowered by Multimodal Large Language Model
Jun 03, 2024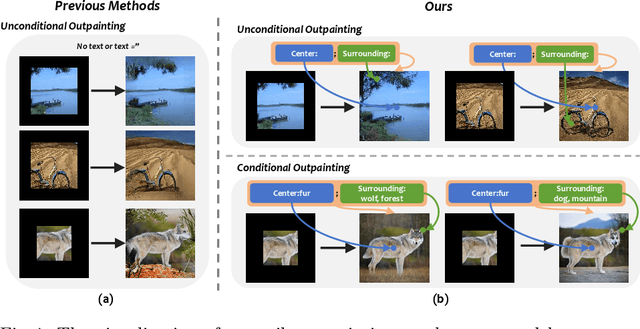
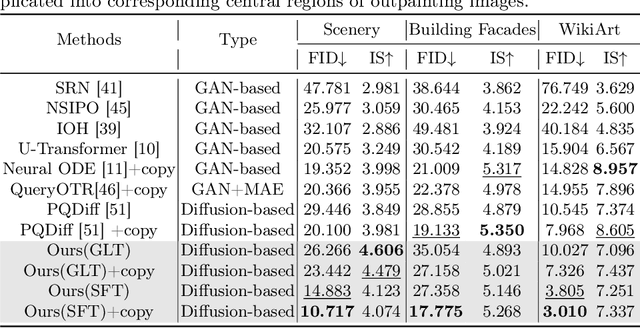
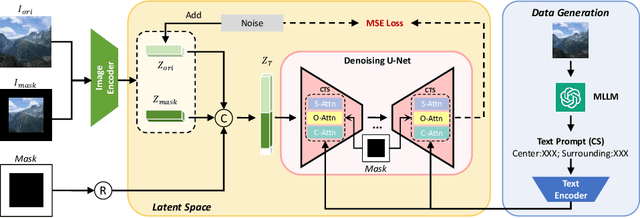
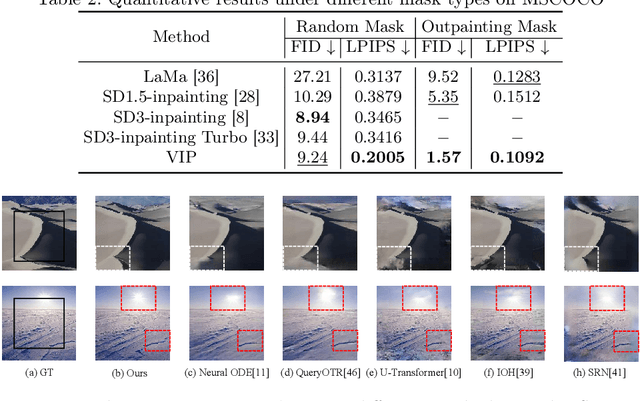
In this paper, we focus on resolving the problem of image outpainting, which aims to extrapolate the surrounding parts given the center contents of an image. Although recent works have achieved promising performance, the lack of versatility and customization hinders their practical applications in broader scenarios. Therefore, this work presents a novel image outpainting framework that is capable of customizing the results according to the requirement of users. First of all, we take advantage of a Multimodal Large Language Model (MLLM) that automatically extracts and organizes the corresponding textual descriptions of the masked and unmasked part of a given image. Accordingly, the obtained text prompts are introduced to endow our model with the capacity to customize the outpainting results. In addition, a special Cross-Attention module, namely Center-Total-Surrounding (CTS), is elaborately designed to enhance further the the interaction between specific space regions of the image and corresponding parts of the text prompts. Note that unlike most existing methods, our approach is very resource-efficient since it is just slightly fine-tuned on the off-the-shelf stable diffusion (SD) model rather than being trained from scratch. Finally, the experimental results on three commonly used datasets, i.e. Scenery, Building, and WikiArt, demonstrate our model significantly surpasses the SoTA methods. Moreover, versatile outpainting results are listed to show its customized ability.
SGD: Street View Synthesis with Gaussian Splatting and Diffusion Prior
Mar 29, 2024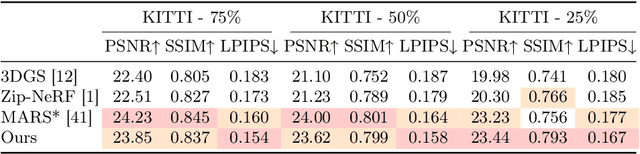
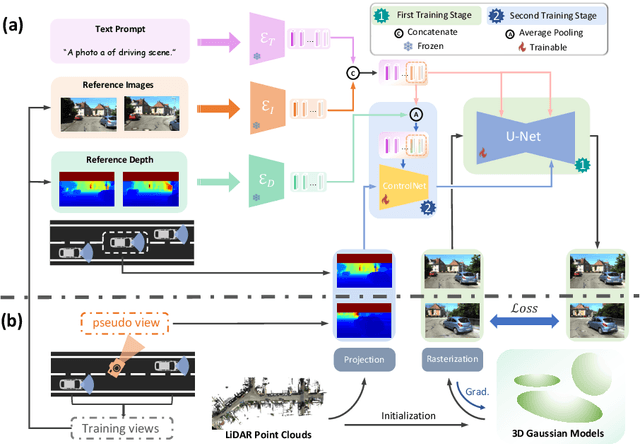
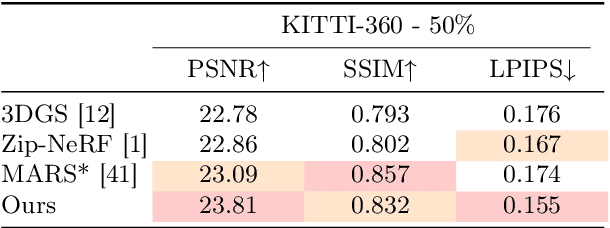
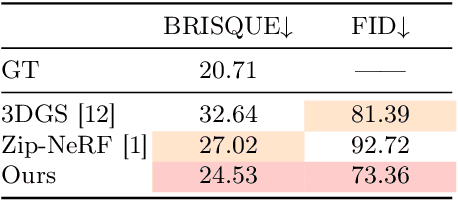
Novel View Synthesis (NVS) for street scenes play a critical role in the autonomous driving simulation. The current mainstream technique to achieve it is neural rendering, such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). Although thrilling progress has been made, when handling street scenes, current methods struggle to maintain rendering quality at the viewpoint that deviates significantly from the training viewpoints. This issue stems from the sparse training views captured by a fixed camera on a moving vehicle. To tackle this problem, we propose a novel approach that enhances the capacity of 3DGS by leveraging prior from a Diffusion Model along with complementary multi-modal data. Specifically, we first fine-tune a Diffusion Model by adding images from adjacent frames as condition, meanwhile exploiting depth data from LiDAR point clouds to supply additional spatial information. Then we apply the Diffusion Model to regularize the 3DGS at unseen views during training. Experimental results validate the effectiveness of our method compared with current state-of-the-art models, and demonstrate its advance in rendering images from broader views.
HiCAST: Highly Customized Arbitrary Style Transfer with Adapter Enhanced Diffusion Models
Jan 11, 2024
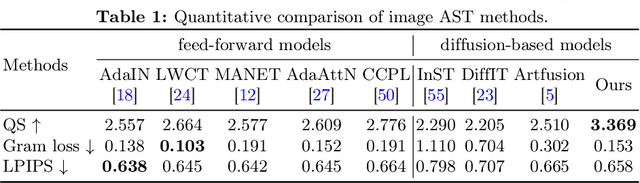
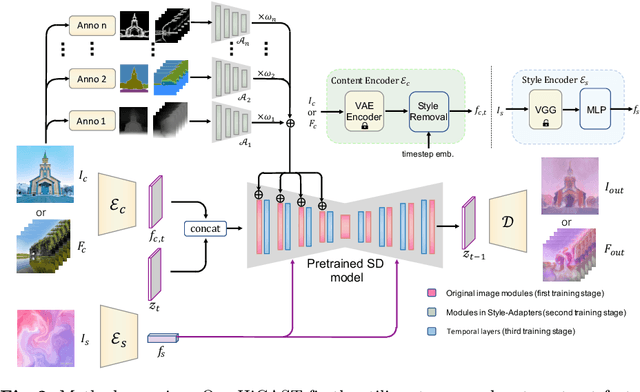
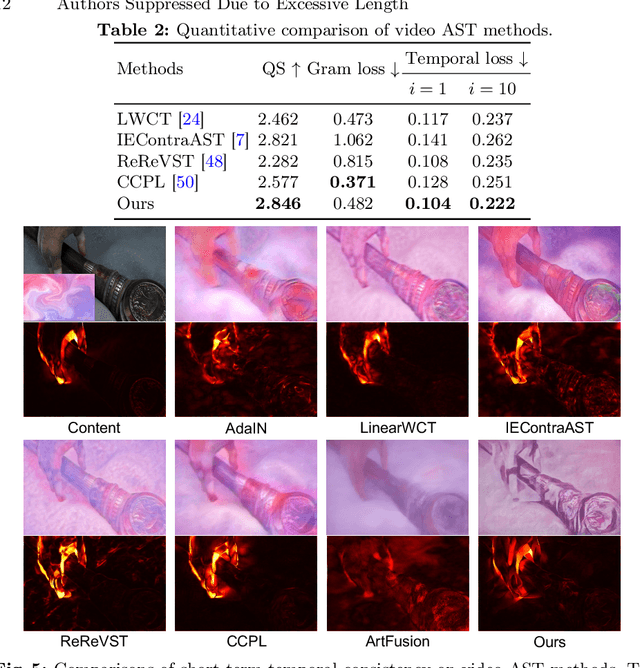
The goal of Arbitrary Style Transfer (AST) is injecting the artistic features of a style reference into a given image/video. Existing methods usually focus on pursuing the balance between style and content, whereas ignoring the significant demand for flexible and customized stylization results and thereby limiting their practical application. To address this critical issue, a novel AST approach namely HiCAST is proposed, which is capable of explicitly customizing the stylization results according to various source of semantic clues. In the specific, our model is constructed based on Latent Diffusion Model (LDM) and elaborately designed to absorb content and style instance as conditions of LDM. It is characterized by introducing of \textit{Style Adapter}, which allows user to flexibly manipulate the output results by aligning multi-level style information and intrinsic knowledge in LDM. Lastly, we further extend our model to perform video AST. A novel learning objective is leveraged for video diffusion model training, which significantly improve cross-frame temporal consistency in the premise of maintaining stylization strength. Qualitative and quantitative comparisons as well as comprehensive user studies demonstrate that our HiCAST outperforms the existing SoTA methods in generating visually plausible stylization results.