 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorner2Net: Detecting Objects as Cascade Corners
Nov 24, 2024



The corner-based detection paradigm enjoys the potential to produce high-quality boxes. But the development is constrained by three factors: 1) Hard to match corners. Heuristic corner matching algorithms can lead to incorrect boxes, especially when similar-looking objects co-occur. 2) Poor instance context. Two separate corners preserve few instance semantics, so it is difficult to guarantee getting both two class-specific corners on the same heatmap channel. 3) Unfriendly backbone. The training cost of the hourglass network is high. Accordingly, we build a novel corner-based framework, named Corner2Net. To achieve the corner-matching-free manner, we devise the cascade corner pipeline which progressively predicts the associated corner pair in two steps instead of synchronously searching two independent corners via parallel heads. Corner2Net decouples corner localization and object classification. Both two corners are class-agnostic and the instance-specific bottom-right corner further simplifies its search space. Meanwhile, RoI features with rich semantics are extracted for classification. Popular backbones (e.g., ResNeXt) can be easily connected to Corner2Net. Experimental results on COCO show Corner2Net surpasses all existing corner-based detectors by a large margin in accuracy and speed.
* This paper is accepted by 27th EUROPEAN CONFERENCE ON ARTIFICIAL INTELLIGENCE (ECAI 2024)
CoFE-RAG: A Comprehensive Full-chain Evaluation Framework for Retrieval-Augmented Generation with Enhanced Data Diversity
Oct 16, 2024Retrieval-Augmented Generation (RAG) aims to enhance large language models (LLMs) to generate more accurate and reliable answers with the help of the retrieved context from external knowledge sources, thereby reducing the incidence of hallucinations. Despite the advancements, evaluating these systems remains a crucial research area due to the following issues: (1) Limited data diversity: The insufficient diversity of knowledge sources and query types constrains the applicability of RAG systems; (2) Obscure problems location: Existing evaluation methods have difficulty in locating the stage of the RAG pipeline where problems occur; (3) Unstable retrieval evaluation: These methods often fail to effectively assess retrieval performance, particularly when the chunking strategy changes. To tackle these challenges, we propose a Comprehensive Full-chain Evaluation (CoFE-RAG) framework to facilitate thorough evaluation across the entire RAG pipeline, including chunking, retrieval, reranking, and generation. To effectively evaluate the first three phases, we introduce multi-granularity keywords, including coarse-grained and fine-grained keywords, to assess the retrieved context instead of relying on the annotation of golden chunks. Moreover, we release a holistic benchmark dataset tailored for diverse data scenarios covering a wide range of document formats and query types. We demonstrate the utility of the CoFE-RAG framework by conducting experiments to evaluate each stage of RAG systems. Our evaluation method provides unique insights into the effectiveness of RAG systems in handling diverse data scenarios, offering a more nuanced understanding of their capabilities and limitations.
Thinking Like an Expert:Multimodal Hypergraph-of-Thought (HoT) Reasoning to boost Foundation Modals
Aug 11, 2023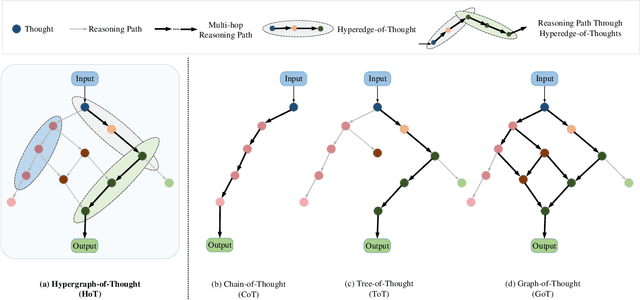

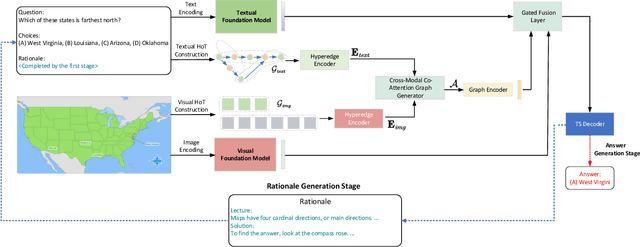

Reasoning ability is one of the most crucial capabilities of a foundation model, signifying its capacity to address complex reasoning tasks. Chain-of-Thought (CoT) technique is widely regarded as one of the effective methods for enhancing the reasoning ability of foundation models and has garnered significant attention. However, the reasoning process of CoT is linear, step-by-step, similar to personal logical reasoning, suitable for solving general and slightly complicated problems. On the contrary, the thinking pattern of an expert owns two prominent characteristics that cannot be handled appropriately in CoT, i.e., high-order multi-hop reasoning and multimodal comparative judgement. Therefore, the core motivation of this paper is transcending CoT to construct a reasoning paradigm that can think like an expert. The hyperedge of a hypergraph could connect various vertices, making it naturally suitable for modelling high-order relationships. Inspired by this, this paper innovatively proposes a multimodal Hypergraph-of-Thought (HoT) reasoning paradigm, which enables the foundation models to possess the expert-level ability of high-order multi-hop reasoning and multimodal comparative judgement. Specifically, a textual hypergraph-of-thought is constructed utilizing triple as the primary thought to model higher-order relationships, and a hyperedge-of-thought is generated through multi-hop walking paths to achieve multi-hop inference. Furthermore, we devise a visual hypergraph-of-thought to interact with the textual hypergraph-of-thought via Cross-modal Co-Attention Graph Learning for multimodal comparative verification. Experimentations on the ScienceQA benchmark demonstrate the proposed HoT-based T5 outperforms CoT-based GPT3.5 and chatGPT, which is on par with CoT-based GPT4 with a lower model size.
Context-aware Tree-based Deep Model for Recommender Systems
Sep 22, 2021



How to predict precise user preference and how to make efficient retrieval from a big corpus are two major challenges of large-scale industrial recommender systems. In tree-based methods, a tree structure T is adopted as index and each item in corpus is attached to a leaf node on T . Then the recommendation problem is converted into a hierarchical retrieval problem solved by a beam search process efficiently. In this paper, we argue that the tree index used to support efficient retrieval in tree-based methods also has rich hierarchical information about the corpus. Furthermore, we propose a novel context-aware tree-based deep model (ConTDM) for recommender systems. In ConTDM, a context-aware user preference prediction model M is designed to utilize both horizontal and vertical contexts on T . Horizontally, a graph convolutional layer is used to enrich the representation of both users and nodes on T with their neighbors. Vertically, a parent fusion layer is designed in M to transmit the user preference representation in higher levels of T to the current level, grasping the essence that tree-based methods are generating the candidate set from coarse to detail during the beam search retrieval. Besides, we argue that the proposed user preference model in ConTDM can be conveniently extended to other tree-based methods for recommender systems. Both experiments on large scale real-world datasets and online A/B test in large scale industrial applications show the significant improvements brought by ConTDM.
Deep learning for smart fish farming: applications, opportunities and challenges
Apr 06, 2020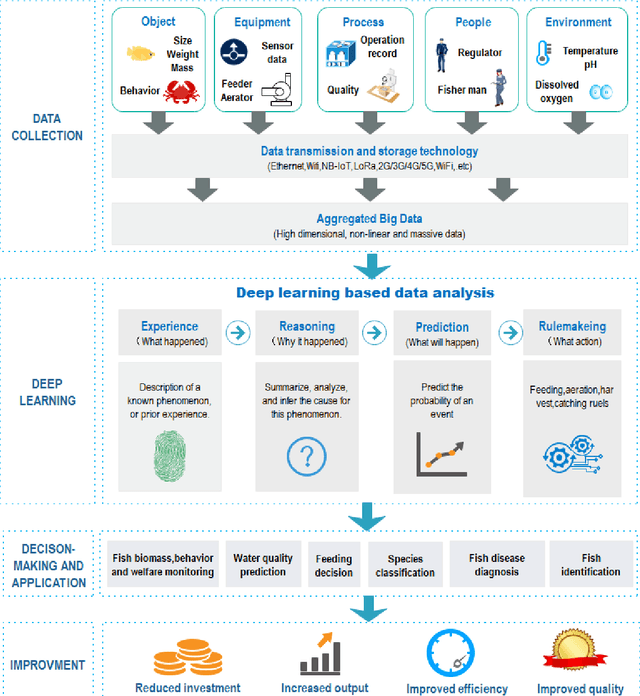


With the rapid emergence of deep learning (DL) technology, it has been successfully used in various fields including aquaculture. This change can create new opportunities and a series of challenges for information and data processing in smart fish farming. This paper focuses on the applications of DL in aquaculture, including live fish identification, species classification, behavioral analysis, feeding decision-making, size or biomass estimation, water quality prediction. In addition, the technical details of DL methods applied to smart fish farming are also analyzed, including data, algorithms, computing power, and performance. The results of this review show that the most significant contribution of DL is the ability to automatically extract features. However, challenges still exist; DL is still in an era of weak artificial intelligence. A large number of labeled data are needed for training, which has become a bottleneck restricting further DL applications in aquaculture. Nevertheless, DL still offers breakthroughs in the handling of complex data in aquaculture. In brief, our purpose is to provide researchers and practitioners with a better understanding of the current state of the art of DL in aquaculture, which can provide strong support for the implementation of smart fish farming.