 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Layered Image Generation for Real-World Editing
Jan 21, 2026Recent image generation models have shown impressive progress, yet they often struggle to yield controllable and consistent results when users attempt to edit specific elements within an existing image. Layered representations enable flexible, user-driven content creation, but existing approaches often fail to produce layers with coherent compositing relationships, and their object layers typically lack realistic visual effects such as shadows and reflections. To overcome these limitations, we propose LASAGNA, a novel, unified framework that generates an image jointly with its composing layers--a photorealistic background and a high-quality transparent foreground with compelling visual effects. Unlike prior work, LASAGNA efficiently learns correct image composition from a wide range of conditioning inputs--text prompts, foreground, background, and location masks--offering greater controllability for real-world applications. To enable this, we introduce LASAGNA-48K, a new dataset composed of clean backgrounds and RGBA foregrounds with physically grounded visual effects. We also propose LASAGNABENCH, the first benchmark for layer editing. We demonstrate that LASAGNA excels in generating highly consistent and coherent results across multiple image layers simultaneously, enabling diverse post-editing applications that accurately preserve identity and visual effects. LASAGNA-48K and LASAGNABENCH will be publicly released to foster open research in the community. The project page is https://rayjryang.github.io/LASAGNA-Page/.
PrivGemo: Privacy-Preserving Dual-Tower Graph Retrieval for Empowering LLM Reasoning with Memory Augmentation
Jan 13, 2026Knowledge graphs (KGs) provide structured evidence that can ground large language model (LLM) reasoning for knowledge-intensive question answering. However, many practical KGs are private, and sending retrieved triples or exploration traces to closed-source LLM APIs introduces leakage risk. Existing privacy treatments focus on masking entity names, but they still face four limitations: structural leakage under semantic masking, uncontrollable remote interaction, fragile multi-hop and multi-entity reasoning, and limited experience reuse for stability and efficiency. To address these issues, we propose PrivGemo, a privacy-preserving retrieval-augmented framework for KG-grounded reasoning with memory-guided exposure control. PrivGemo uses a dual-tower design to keep raw KG knowledge local while enabling remote reasoning over an anonymized view that goes beyond name masking to limit both semantic and structural exposure. PrivGemo supports multi-hop, multi-entity reasoning by retrieving anonymized long-hop paths that connect all topic entities, while keeping grounding and verification on the local KG. A hierarchical controller and a privacy-aware experience memory further reduce unnecessary exploration and remote interactions. Comprehensive experiments on six benchmarks show that PrivGemo achieves overall state-of-the-art results, outperforming the strongest baseline by up to 17.1%. Furthermore, PrivGemo enables smaller models (e.g., Qwen3-4B) to achieve reasoning performance comparable to that of GPT-4-Turbo.
Taxon: Hierarchical Tax Code Prediction with Semantically Aligned LLM Expert Guidance
Jan 13, 2026Tax code prediction is a crucial yet underexplored task in automating invoicing and compliance management for large-scale e-commerce platforms. Each product must be accurately mapped to a node within a multi-level taxonomic hierarchy defined by national standards, where errors lead to financial inconsistencies and regulatory risks. This paper presents Taxon, a semantically aligned and expert-guided framework for hierarchical tax code prediction. Taxon integrates (i) a feature-gating mixture-of-experts architecture that adaptively routes multi-modal features across taxonomy levels, and (ii) a semantic consistency model distilled from large language models acting as domain experts to verify alignment between product titles and official tax definitions. To address noisy supervision in real business records, we design a multi-source training pipeline that combines curated tax databases, invoice validation logs, and merchant registration data to provide both structural and semantic supervision. Extensive experiments on the proprietary TaxCode dataset and public benchmarks demonstrate that Taxon achieves state-of-the-art performance, outperforming strong baselines. Further, an additional full hierarchical paths reconstruction procedure significantly improves structural consistency, yielding the highest overall F1 scores. Taxon has been deployed in production within Alibaba's tax service system, handling an average of over 500,000 tax code queries per day and reaching peak volumes above five million requests during business event with improved accuracy, interpretability, and robustness.
Both Semantics and Reconstruction Matter: Making Representation Encoders Ready for Text-to-Image Generation and Editing
Dec 19, 2025Modern Latent Diffusion Models (LDMs) typically operate in low-level Variational Autoencoder (VAE) latent spaces that are primarily optimized for pixel-level reconstruction. To unify vision generation and understanding, a burgeoning trend is to adopt high-dimensional features from representation encoders as generative latents. However, we empirically identify two fundamental obstacles in this paradigm: (1) the discriminative feature space lacks compact regularization, making diffusion models prone to off-manifold latents that lead to inaccurate object structures; and (2) the encoder's inherently weak pixel-level reconstruction hinders the generator from learning accurate fine-grained geometry and texture. In this paper, we propose a systematic framework to adapt understanding-oriented encoder features for generative tasks. We introduce a semantic-pixel reconstruction objective to regularize the latent space, enabling the compression of both semantic information and fine-grained details into a highly compact representation (96 channels with 16x16 spatial downsampling). This design ensures that the latent space remains semantically rich and achieves state-of-the-art image reconstruction, while remaining compact enough for accurate generation. Leveraging this representation, we design a unified Text-to-Image (T2I) and image editing model. Benchmarking against various feature spaces, we demonstrate that our approach achieves state-of-the-art reconstruction, faster convergence, and substantial performance gains in both T2I and editing tasks, validating that representation encoders can be effectively adapted into robust generative components.
Ensembling LLM-Induced Decision Trees for Explainable and Robust Error Detection
Dec 08, 2025Error detection (ED), which aims to identify incorrect or inconsistent cell values in tabular data, is important for ensuring data quality. Recent state-of-the-art ED methods leverage the pre-trained knowledge and semantic capability embedded in large language models (LLMs) to directly label whether a cell is erroneous. However, this LLM-as-a-labeler pipeline (1) relies on the black box, implicit decision process, thus failing to provide explainability for the detection results, and (2) is highly sensitive to prompts, yielding inconsistent outputs due to inherent model stochasticity, therefore lacking robustness. To address these limitations, we propose an LLM-as-an-inducer framework that adopts LLM to induce the decision tree for ED (termed TreeED) and further ensembles multiple such trees for consensus detection (termed ForestED), thereby improving explainability and robustness. Specifically, based on prompts derived from data context, decision tree specifications and output requirements, TreeED queries the LLM to induce the decision tree skeleton, whose root-to-leaf decision paths specify the stepwise procedure for evaluating a given sample. Each tree contains three types of nodes: (1) rule nodes that perform simple validation checks (e.g., format or range), (2) Graph Neural Network (GNN) nodes that capture complex patterns (e.g., functional dependencies), and (3) leaf nodes that output the final decision types (error or clean). Furthermore, ForestED employs uncertainty-based sampling to obtain multiple row subsets, constructing a decision tree for each subset using TreeED. It then leverages an Expectation-Maximization-based algorithm that jointly estimates tree reliability and optimizes the consensus ED prediction. Extensive xperiments demonstrate that our methods are accurate, explainable and robust, achieving an average F1-score improvement of 16.1% over the best baseline.
UniSER: A Foundation Model for Unified Soft Effects Removal
Nov 18, 2025Digital images are often degraded by soft effects such as lens flare, haze, shadows, and reflections, which reduce aesthetics even though the underlying pixels remain partially visible. The prevailing works address these degradations in isolation, developing highly specialized, specialist models that lack scalability and fail to exploit the shared underlying essences of these restoration problems. While specialist models are limited, recent large-scale pretrained generalist models offer powerful, text-driven image editing capabilities. while recent general-purpose systems (e.g., GPT-4o, Flux Kontext, Nano Banana) require detailed prompts and often fail to achieve robust removal on these fine-grained tasks or preserve identity of the scene. Leveraging the common essence of soft effects, i.e., semi-transparent occlusions, we introduce a foundational versatile model UniSER, capable of addressing diverse degradations caused by soft effects within a single framework. Our methodology centers on curating a massive 3.8M-pair dataset to ensure robustness and generalization, which includes novel, physically-plausible data to fill critical gaps in public benchmarks, and a tailored training pipeline that fine-tunes a Diffusion Transformer to learn robust restoration priors from this diverse data, integrating fine-grained mask and strength controls. This synergistic approach allows UniSER to significantly outperform both specialist and generalist models, achieving robust, high-fidelity restoration in the wild.
PSScreen V2: Partially Supervised Multiple Retinal Disease Screening
Oct 26, 2025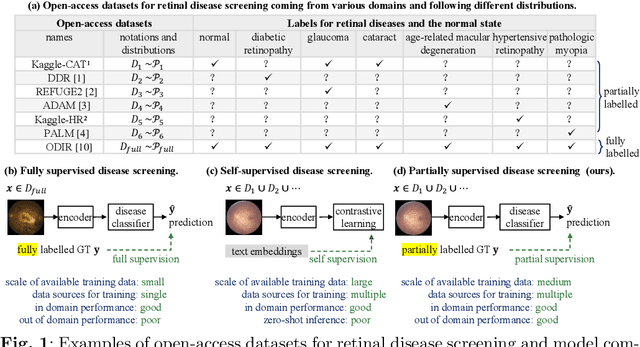
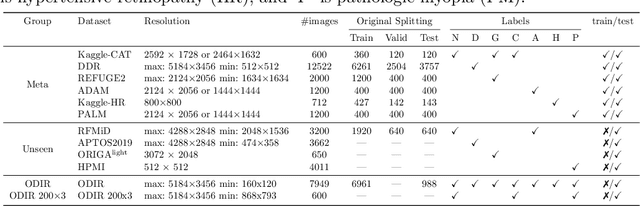
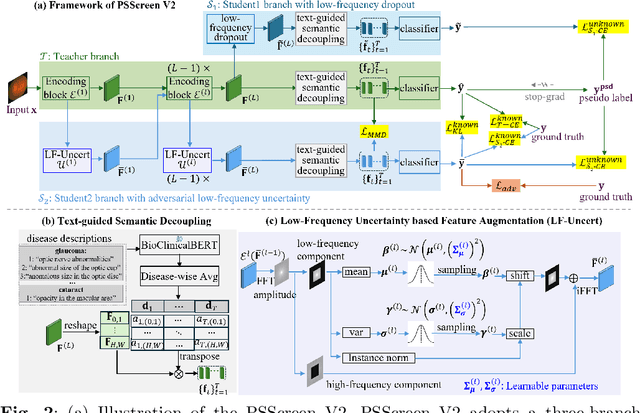
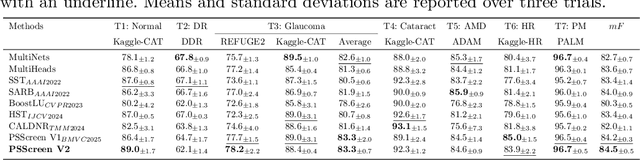
In this work, we propose PSScreen V2, a partially supervised self-training framework for multiple retinal disease screening. Unlike previous methods that rely on fully labelled or single-domain datasets, PSScreen V2 is designed to learn from multiple partially labelled datasets with different distributions, addressing both label absence and domain shift challenges. To this end, PSScreen V2 adopts a three-branch architecture with one teacher and two student networks. The teacher branch generates pseudo labels from weakly augmented images to address missing labels, while the two student branches introduce novel feature augmentation strategies: Low-Frequency Dropout (LF-Dropout), which enhances domain robustness by randomly discarding domain-related low-frequency components, and Low-Frequency Uncertainty (LF-Uncert), which estimates uncertain domain variability via adversarially learned Gaussian perturbations of low-frequency statistics. Extensive experiments on multiple in-domain and out-of-domain fundus datasets demonstrate that PSScreen V2 achieves state-of-the-art performance and superior domain generalization ability. Furthermore, compatibility tests with diverse backbones, including the vision foundation model DINOv2, as well as evaluations on chest X-ray datasets, highlight the universality and adaptability of the proposed framework. The codes are available at https://github.com/boyiZheng99/PSScreen_V2.
BrainMCLIP: Brain Image Decoding with Multi-Layer feature Fusion of CLIP
Oct 22, 2025Decoding images from fMRI often involves mapping brain activity to CLIP's final semantic layer. To capture finer visual details, many approaches add a parameter-intensive VAE-based pipeline. However, these approaches overlook rich object information within CLIP's intermediate layers and contradicts the brain's functionally hierarchical. We introduce BrainMCLIP, which pioneers a parameter-efficient, multi-layer fusion approach guided by human visual system's functional hierarchy, eliminating the need for such a separate VAE pathway. BrainMCLIP aligns fMRI signals from functionally distinct visual areas (low-/high-level) to corresponding intermediate and final CLIP layers, respecting functional hierarchy. We further introduce a Cross-Reconstruction strategy and a novel multi-granularity loss. Results show BrainMCLIP achieves highly competitive performance, particularly excelling on high-level semantic metrics where it matches or surpasses SOTA(state-of-the-art) methods, including those using VAE pipelines. Crucially, it achieves this with substantially fewer parameters, demonstrating a reduction of 71.7\%(Table.\ref{tab:compare_clip_vae}) compared to top VAE-based SOTA methods, by avoiding the VAE pathway. By leveraging intermediate CLIP features, it effectively captures visual details often missed by CLIP-only approaches, striking a compelling balance between semantic accuracy and detail fidelity without requiring a separate VAE pipeline.
PRoH: Dynamic Planning and Reasoning over Knowledge Hypergraphs for Retrieval-Augmented Generation
Oct 14, 2025Knowledge Hypergraphs (KHs) have recently emerged as a knowledge representation for retrieval-augmented generation (RAG), offering a paradigm to model multi-entity relations into a structured form. However, existing KH-based RAG methods suffer from three major limitations: static retrieval planning, non-adaptive retrieval execution, and superficial use of KH structure and semantics, which constrain their ability to perform effective multi-hop question answering. To overcome these limitations, we propose PRoH, a dynamic Planning and Reasoning over Knowledge Hypergraphs framework. PRoH incorporates three core innovations: (i) a context-aware planning module that sketches the local KH neighborhood to guide structurally grounded reasoning plan generation; (ii) a structured question decomposition process that organizes subquestions as a dynamically evolving Directed Acyclic Graph (DAG) to enable adaptive, multi-trajectory exploration; and (iii) an Entity-Weighted Overlap (EWO)-guided reasoning path retrieval algorithm that prioritizes semantically coherent hyperedge traversals. Experiments across multiple domains demonstrate that PRoH achieves state-of-the-art performance, surpassing the prior SOTA model HyperGraphRAG by an average of 19.73% in F1 and 8.41% in Generation Evaluation (G-E) score, while maintaining strong robustness in long-range multi-hop reasoning tasks.
Controllable Localized Face Anonymization Via Diffusion Inpainting
Sep 18, 2025



The growing use of portrait images in computer vision highlights the need to protect personal identities. At the same time, anonymized images must remain useful for downstream computer vision tasks. In this work, we propose a unified framework that leverages the inpainting ability of latent diffusion models to generate realistic anonymized images. Unlike prior approaches, we have complete control over the anonymization process by designing an adaptive attribute-guidance module that applies gradient correction during the reverse denoising process, aligning the facial attributes of the generated image with those of the synthesized target image. Our framework also supports localized anonymization, allowing users to specify which facial regions are left unchanged. Extensive experiments conducted on the public CelebA-HQ and FFHQ datasets show that our method outperforms state-of-the-art approaches while requiring no additional model training. The source code is available on our page.