 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusionBrowser: Interactive Diffusion Previews via Multi-Branch Decoders
Dec 15, 2025
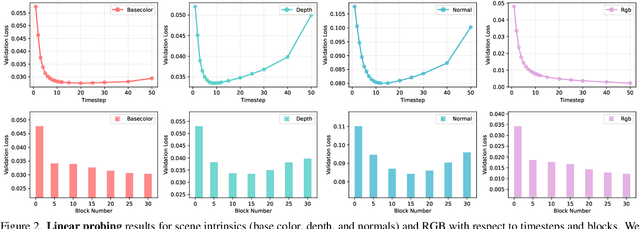


Video diffusion models have revolutionized generative video synthesis, but they are imprecise, slow, and can be opaque during generation -- keeping users in the dark for a prolonged period. In this work, we propose DiffusionBrowser, a model-agnostic, lightweight decoder framework that allows users to interactively generate previews at any point (timestep or transformer block) during the denoising process. Our model can generate multi-modal preview representations that include RGB and scene intrinsics at more than 4$\times$ real-time speed (less than 1 second for a 4-second video) that convey consistent appearance and motion to the final video. With the trained decoder, we show that it is possible to interactively guide the generation at intermediate noise steps via stochasticity reinjection and modal steering, unlocking a new control capability. Moreover, we systematically probe the model using the learned decoders, revealing how scene, object, and other details are composed and assembled during the otherwise black-box denoising process.
Tuning-Free Multi-Event Long Video Generation via Synchronized Coupled Sampling
Mar 11, 2025While recent advancements in text-to-video diffusion models enable high-quality short video generation from a single prompt, generating real-world long videos in a single pass remains challenging due to limited data and high computational costs. To address this, several works propose tuning-free approaches, i.e., extending existing models for long video generation, specifically using multiple prompts to allow for dynamic and controlled content changes. However, these methods primarily focus on ensuring smooth transitions between adjacent frames, often leading to content drift and a gradual loss of semantic coherence over longer sequences. To tackle such an issue, we propose Synchronized Coupled Sampling (SynCoS), a novel inference framework that synchronizes denoising paths across the entire video, ensuring long-range consistency across both adjacent and distant frames. Our approach combines two complementary sampling strategies: reverse and optimization-based sampling, which ensure seamless local transitions and enforce global coherence, respectively. However, directly alternating between these samplings misaligns denoising trajectories, disrupting prompt guidance and introducing unintended content changes as they operate independently. To resolve this, SynCoS synchronizes them through a grounded timestep and a fixed baseline noise, ensuring fully coupled sampling with aligned denoising paths. Extensive experiments show that SynCoS significantly improves multi-event long video generation, achieving smoother transitions and superior long-range coherence, outperforming previous approaches both quantitatively and qualitatively.
GaussianVideo: Efficient Video Representation via Hierarchical Gaussian Splatting
Jan 08, 2025Efficient neural representations for dynamic video scenes are critical for applications ranging from video compression to interactive simulations. Yet, existing methods often face challenges related to high memory usage, lengthy training times, and temporal consistency. To address these issues, we introduce a novel neural video representation that combines 3D Gaussian splatting with continuous camera motion modeling. By leveraging Neural ODEs, our approach learns smooth camera trajectories while maintaining an explicit 3D scene representation through Gaussians. Additionally, we introduce a spatiotemporal hierarchical learning strategy, progressively refining spatial and temporal features to enhance reconstruction quality and accelerate convergence. This memory-efficient approach achieves high-quality rendering at impressive speeds. Experimental results show that our hierarchical learning, combined with robust camera motion modeling, captures complex dynamic scenes with strong temporal consistency, achieving state-of-the-art performance across diverse video datasets in both high- and low-motion scenarios.
TransPixar: Advancing Text-to-Video Generation with Transparency
Jan 06, 2025



Text-to-video generative models have made significant strides, enabling diverse applications in entertainment, advertising, and education. However, generating RGBA video, which includes alpha channels for transparency, remains a challenge due to limited datasets and the difficulty of adapting existing models. Alpha channels are crucial for visual effects (VFX), allowing transparent elements like smoke and reflections to blend seamlessly into scenes. We introduce TransPixar, a method to extend pretrained video models for RGBA generation while retaining the original RGB capabilities. TransPixar leverages a diffusion transformer (DiT) architecture, incorporating alpha-specific tokens and using LoRA-based fine-tuning to jointly generate RGB and alpha channels with high consistency. By optimizing attention mechanisms, TransPixar preserves the strengths of the original RGB model and achieves strong alignment between RGB and alpha channels despite limited training data. Our approach effectively generates diverse and consistent RGBA videos, advancing the possibilities for VFX and interactive content creation.
Generative Video Propagation
Dec 27, 2024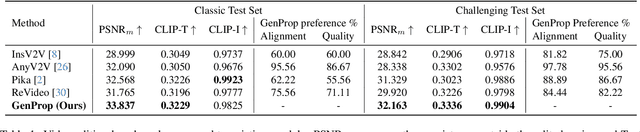
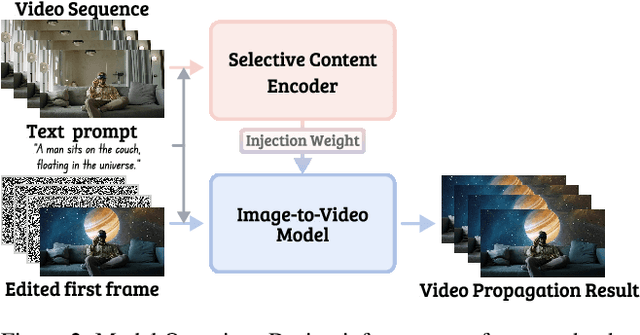
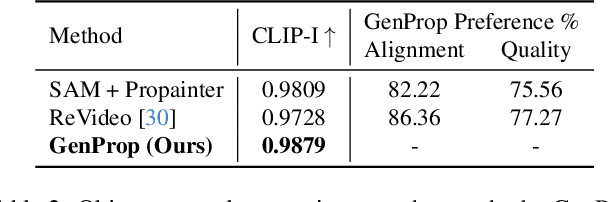
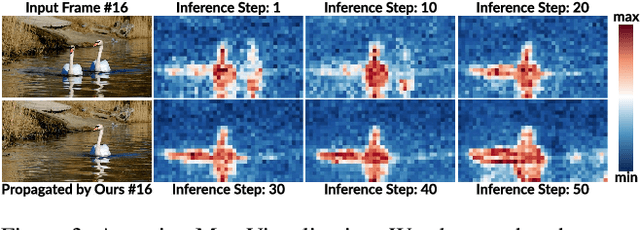
Large-scale video generation models have the inherent ability to realistically model natural scenes. In this paper, we demonstrate that through a careful design of a generative video propagation framework, various video tasks can be addressed in a unified way by leveraging the generative power of such models. Specifically, our framework, GenProp, encodes the original video with a selective content encoder and propagates the changes made to the first frame using an image-to-video generation model. We propose a data generation scheme to cover multiple video tasks based on instance-level video segmentation datasets. Our model is trained by incorporating a mask prediction decoder head and optimizing a region-aware loss to aid the encoder to preserve the original content while the generation model propagates the modified region. This novel design opens up new possibilities: In editing scenarios, GenProp allows substantial changes to an object's shape; for insertion, the inserted objects can exhibit independent motion; for removal, GenProp effectively removes effects like shadows and reflections from the whole video; for tracking, GenProp is capable of tracking objects and their associated effects together. Experiment results demonstrate the leading performance of our model in various video tasks, and we further provide in-depth analyses of the proposed framework.
Move-in-2D: 2D-Conditioned Human Motion Generation
Dec 17, 2024



Generating realistic human videos remains a challenging task, with the most effective methods currently relying on a human motion sequence as a control signal. Existing approaches often use existing motion extracted from other videos, which restricts applications to specific motion types and global scene matching. We propose Move-in-2D, a novel approach to generate human motion sequences conditioned on a scene image, allowing for diverse motion that adapts to different scenes. Our approach utilizes a diffusion model that accepts both a scene image and text prompt as inputs, producing a motion sequence tailored to the scene. To train this model, we collect a large-scale video dataset featuring single-human activities, annotating each video with the corresponding human motion as the target output. Experiments demonstrate that our method effectively predicts human motion that aligns with the scene image after projection. Furthermore, we show that the generated motion sequence improves human motion quality in video synthesis tasks.
Generative Timelines for Instructed Visual Assembly
Nov 19, 2024The objective of this work is to manipulate visual timelines (e.g. a video) through natural language instructions, making complex timeline editing tasks accessible to non-expert or potentially even disabled users. We call this task Instructed visual assembly. This task is challenging as it requires (i) identifying relevant visual content in the input timeline as well as retrieving relevant visual content in a given input (video) collection, (ii) understanding the input natural language instruction, and (iii) performing the desired edits of the input visual timeline to produce an output timeline. To address these challenges, we propose the Timeline Assembler, a generative model trained to perform instructed visual assembly tasks. The contributions of this work are three-fold. First, we develop a large multimodal language model, which is designed to process visual content, compactly represent timelines and accurately interpret timeline editing instructions. Second, we introduce a novel method for automatically generating datasets for visual assembly tasks, enabling efficient training of our model without the need for human-labeled data. Third, we validate our approach by creating two novel datasets for image and video assembly, demonstrating that the Timeline Assembler substantially outperforms established baseline models, including the recent GPT-4o, in accurately executing complex assembly instructions across various real-world inspired scenarios.
They're All Doctors: Synthesizing Diverse Counterfactuals to Mitigate Associative Bias
Jun 17, 2024Vision Language Models (VLMs) such as CLIP are powerful models; however they can exhibit unwanted biases, making them less safe when deployed directly in applications such as text-to-image, text-to-video retrievals, reverse search, or classification tasks. In this work, we propose a novel framework to generate synthetic counterfactual images to create a diverse and balanced dataset that can be used to fine-tune CLIP. Given a set of diverse synthetic base images from text-to-image models, we leverage off-the-shelf segmentation and inpainting models to place humans with diverse visual appearances in context. We show that CLIP trained on such datasets learns to disentangle the human appearance from the context of an image, i.e., what makes a doctor is not correlated to the person's visual appearance, like skin color or body type, but to the context, such as background, the attire they are wearing, or the objects they are holding. We demonstrate that our fine-tuned CLIP model, $CF_\alpha$, improves key fairness metrics such as MaxSkew, MinSkew, and NDKL by 40-66\% for image retrieval tasks, while still achieving similar levels of performance in downstream tasks. We show that, by design, our model retains maximal compatibility with the original CLIP models, and can be easily controlled to support different accuracy versus fairness trade-offs in a plug-n-play fashion.
GenLens: A Systematic Evaluation of Visual GenAI Model Outputs
Feb 06, 2024The rapid development of generative AI (GenAI) models in computer vision necessitates effective evaluation methods to ensure their quality and fairness. Existing tools primarily focus on dataset quality assurance and model explainability, leaving a significant gap in GenAI output evaluation during model development. Current practices often depend on developers' subjective visual assessments, which may lack scalability and generalizability. This paper bridges this gap by conducting a formative study with GenAI model developers in an industrial setting. Our findings led to the development of GenLens, a visual analytic interface designed for the systematic evaluation of GenAI model outputs during the early stages of model development. GenLens offers a quantifiable approach for overviewing and annotating failure cases, customizing issue tags and classifications, and aggregating annotations from multiple users to enhance collaboration. A user study with model developers reveals that GenLens effectively enhances their workflow, evidenced by high satisfaction rates and a strong intent to integrate it into their practices. This research underscores the importance of robust early-stage evaluation tools in GenAI development, contributing to the advancement of fair and high-quality GenAI models.
SoundCam: A Dataset for Finding Humans Using Room Acoustics
Nov 06, 2023A room's acoustic properties are a product of the room's geometry, the objects within the room, and their specific positions. A room's acoustic properties can be characterized by its impulse response (RIR) between a source and listener location, or roughly inferred from recordings of natural signals present in the room. Variations in the positions of objects in a room can effect measurable changes in the room's acoustic properties, as characterized by the RIR. Existing datasets of RIRs either do not systematically vary positions of objects in an environment, or they consist of only simulated RIRs. We present SoundCam, the largest dataset of unique RIRs from in-the-wild rooms publicly released to date. It includes 5,000 10-channel real-world measurements of room impulse responses and 2,000 10-channel recordings of music in three different rooms, including a controlled acoustic lab, an in-the-wild living room, and a conference room, with different humans in positions throughout each room. We show that these measurements can be used for interesting tasks, such as detecting and identifying humans, and tracking their positions.