 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs What You Ask For What You Get? Investigating Concept Associations in Text-to-Image Models
Oct 06, 2024


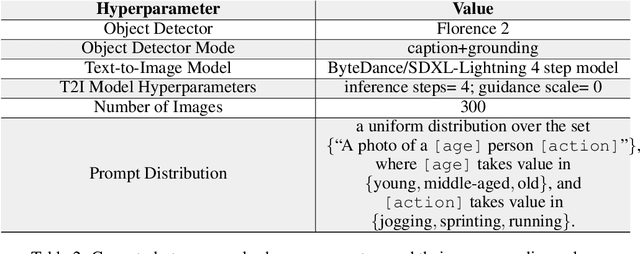
Text-to-image (T2I) models are increasingly used in impactful real-life applications. As such, there is a growing need to audit these models to ensure that they generate desirable, task-appropriate images. However, systematically inspecting the associations between prompts and generated content in a human-understandable way remains challenging. To address this, we propose \emph{Concept2Concept}, a framework where we characterize conditional distributions of vision language models using interpretable concepts and metrics that can be defined in terms of these concepts. This characterization allows us to use our framework to audit models and prompt-datasets. To demonstrate, we investigate several case studies of conditional distributions of prompts, such as user defined distributions or empirical, real world distributions. Lastly, we implement Concept2Concept as an open-source interactive visualization tool facilitating use by non-technical end-users. Warning: This paper contains discussions of harmful content, including CSAM and NSFW material, which may be disturbing to some readers.
They're All Doctors: Synthesizing Diverse Counterfactuals to Mitigate Associative Bias
Jun 17, 2024Vision Language Models (VLMs) such as CLIP are powerful models; however they can exhibit unwanted biases, making them less safe when deployed directly in applications such as text-to-image, text-to-video retrievals, reverse search, or classification tasks. In this work, we propose a novel framework to generate synthetic counterfactual images to create a diverse and balanced dataset that can be used to fine-tune CLIP. Given a set of diverse synthetic base images from text-to-image models, we leverage off-the-shelf segmentation and inpainting models to place humans with diverse visual appearances in context. We show that CLIP trained on such datasets learns to disentangle the human appearance from the context of an image, i.e., what makes a doctor is not correlated to the person's visual appearance, like skin color or body type, but to the context, such as background, the attire they are wearing, or the objects they are holding. We demonstrate that our fine-tuned CLIP model, $CF_\alpha$, improves key fairness metrics such as MaxSkew, MinSkew, and NDKL by 40-66\% for image retrieval tasks, while still achieving similar levels of performance in downstream tasks. We show that, by design, our model retains maximal compatibility with the original CLIP models, and can be easily controlled to support different accuracy versus fairness trade-offs in a plug-n-play fashion.
Masked Image Training for Generalizable Deep Image Denoising
Mar 23, 2023
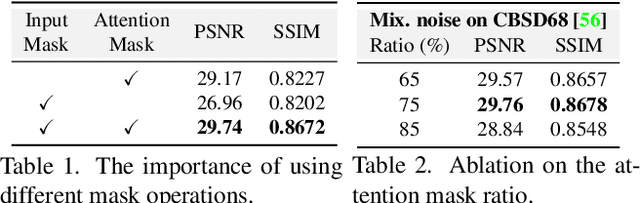


When capturing and storing images, devices inevitably introduce noise. Reducing this noise is a critical task called image denoising. Deep learning has become the de facto method for image denoising, especially with the emergence of Transformer-based models that have achieved notable state-of-the-art results on various image tasks. However, deep learning-based methods often suffer from a lack of generalization ability. For example, deep models trained on Gaussian noise may perform poorly when tested on other noise distributions. To address this issue, we present a novel approach to enhance the generalization performance of denoising networks, known as masked training. Our method involves masking random pixels of the input image and reconstructing the missing information during training. We also mask out the features in the self-attention layers to avoid the impact of training-testing inconsistency. Our approach exhibits better generalization ability than other deep learning models and is directly applicable to real-world scenarios. Additionally, our interpretability analysis demonstrates the superiority of our method.
Revisiting RCAN: Improved Training for Image Super-Resolution
Jan 27, 2022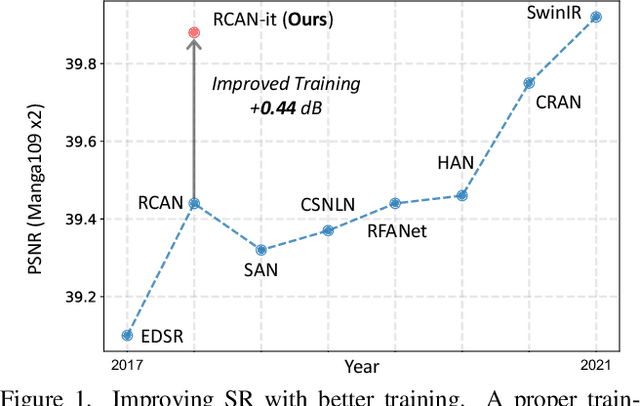
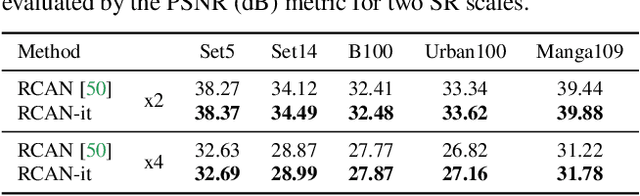
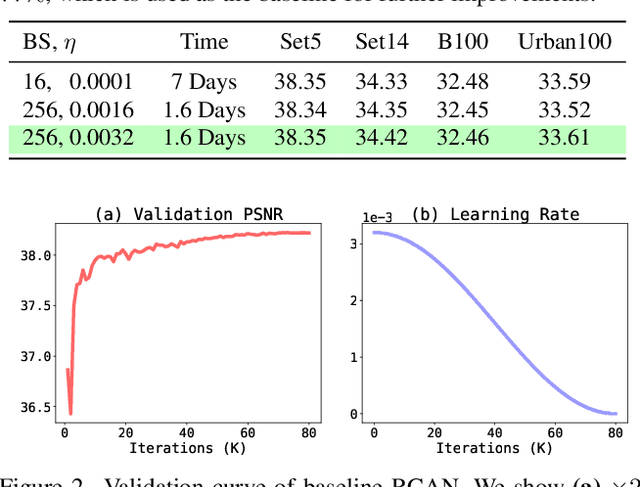
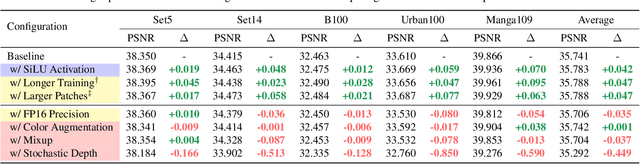
Image super-resolution (SR) is a fast-moving field with novel architectures attracting the spotlight. However, most SR models were optimized with dated training strategies. In this work, we revisit the popular RCAN model and examine the effect of different training options in SR. Surprisingly (or perhaps as expected), we show that RCAN can outperform or match nearly all the CNN-based SR architectures published after RCAN on standard benchmarks with a proper training strategy and minimal architecture change. Besides, although RCAN is a very large SR architecture with more than four hundred convolutional layers, we draw a notable conclusion that underfitting is still the main problem restricting the model capability instead of overfitting. We observe supportive evidence that increasing training iterations clearly improves the model performance while applying regularization techniques generally degrades the predictions. We denote our simply revised RCAN as RCAN-it and recommend practitioners to use it as baselines for future research. Code is publicly available at https://github.com/zudi-lin/rcan-it.
Image Classification on IoT Edge Devices: Profiling and Modeling
Feb 24, 2019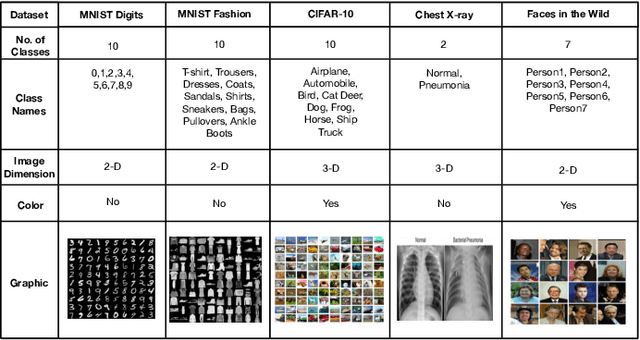


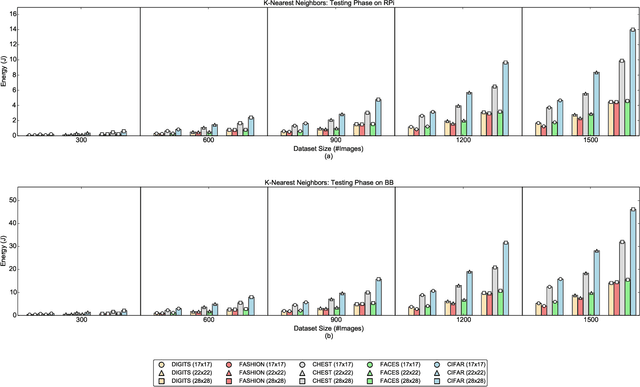
With the advent of powerful, low-cost IoT systems, processing data closer to where the data originates, known as edge computing, has become an increasingly viable option. In addition to lowering the cost of networking infrastructures, edge computing reduces edge-cloud delay, which is essential for mission-critical applications. In this paper, we show the feasibility and study the performance of image classification using IoT devices. Specifically, we explore the relationships between various factors of image classification algorithms that may affect energy consumption such as dataset size, image resolution, algorithm type, algorithm phase, and device hardware. Our experiments show a strong, positive linear relationship between three predictor variables, namely model complexity, image resolution, and dataset size, with respect to energy consumption. In addition, in order to provide a means of predicting the energy consumption of an edge device performing image classification, we investigate the usage of three machine learning algorithms using the data generated from our experiments. The performance as well as the trade offs for using linear regression, Gaussian process, and random forests are discussed and validated. Our results indicate that the random forest model outperforms the two former algorithms, with an R-squared value of 0.95 and 0.79 for two different validation datasets.