 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChineseSimpleVQA -- "See the World, Discover Knowledge": A Chinese Factuality Evaluation for Large Vision Language Models
Feb 19, 2025The evaluation of factual accuracy in large vision language models (LVLMs) has lagged behind their rapid development, making it challenging to fully reflect these models' knowledge capacity and reliability. In this paper, we introduce the first factuality-based visual question-answering benchmark in Chinese, named ChineseSimpleVQA, aimed at assessing the visual factuality of LVLMs across 8 major topics and 56 subtopics. The key features of this benchmark include a focus on the Chinese language, diverse knowledge types, a multi-hop question construction, high-quality data, static consistency, and easy-to-evaluate through short answers. Moreover, we contribute a rigorous data construction pipeline and decouple the visual factuality into two parts: seeing the world (i.e., object recognition) and discovering knowledge. This decoupling allows us to analyze the capability boundaries and execution mechanisms of LVLMs. Subsequently, we evaluate 34 advanced open-source and closed-source models, revealing critical performance gaps within this field.
Affordance-Aware Object Insertion via Mask-Aware Dual Diffusion
Dec 19, 2024As a common image editing operation, image composition involves integrating foreground objects into background scenes. In this paper, we expand the application of the concept of Affordance from human-centered image composition tasks to a more general object-scene composition framework, addressing the complex interplay between foreground objects and background scenes. Following the principle of Affordance, we define the affordance-aware object insertion task, which aims to seamlessly insert any object into any scene with various position prompts. To address the limited data issue and incorporate this task, we constructed the SAM-FB dataset, which contains over 3 million examples across more than 3,000 object categories. Furthermore, we propose the Mask-Aware Dual Diffusion (MADD) model, which utilizes a dual-stream architecture to simultaneously denoise the RGB image and the insertion mask. By explicitly modeling the insertion mask in the diffusion process, MADD effectively facilitates the notion of affordance. Extensive experimental results show that our method outperforms the state-of-the-art methods and exhibits strong generalization performance on in-the-wild images. Please refer to our code on https://github.com/KaKituken/affordance-aware-any.
SocialGPT: Prompting LLMs for Social Relation Reasoning via Greedy Segment Optimization
Oct 28, 2024



Social relation reasoning aims to identify relation categories such as friends, spouses, and colleagues from images. While current methods adopt the paradigm of training a dedicated network end-to-end using labeled image data, they are limited in terms of generalizability and interpretability. To address these issues, we first present a simple yet well-crafted framework named {\name}, which combines the perception capability of Vision Foundation Models (VFMs) and the reasoning capability of Large Language Models (LLMs) within a modular framework, providing a strong baseline for social relation recognition. Specifically, we instruct VFMs to translate image content into a textual social story, and then utilize LLMs for text-based reasoning. {\name} introduces systematic design principles to adapt VFMs and LLMs separately and bridge their gaps. Without additional model training, it achieves competitive zero-shot results on two databases while offering interpretable answers, as LLMs can generate language-based explanations for the decisions. The manual prompt design process for LLMs at the reasoning phase is tedious and an automated prompt optimization method is desired. As we essentially convert a visual classification task into a generative task of LLMs, automatic prompt optimization encounters a unique long prompt optimization issue. To address this issue, we further propose the Greedy Segment Prompt Optimization (GSPO), which performs a greedy search by utilizing gradient information at the segment level. Experimental results show that GSPO significantly improves performance, and our method also generalizes to different image styles. The code is available at https://github.com/Mengzibin/SocialGPT.
Learning Gaze-aware Compositional GAN
May 31, 2024



Gaze-annotated facial data is crucial for training deep neural networks (DNNs) for gaze estimation. However, obtaining these data is labor-intensive and requires specialized equipment due to the challenge of accurately annotating the gaze direction of a subject. In this work, we present a generative framework to create annotated gaze data by leveraging the benefits of labeled and unlabeled data sources. We propose a Gaze-aware Compositional GAN that learns to generate annotated facial images from a limited labeled dataset. Then we transfer this model to an unlabeled data domain to take advantage of the diversity it provides. Experiments demonstrate our approach's effectiveness in generating within-domain image augmentations in the ETH-XGaze dataset and cross-domain augmentations in the CelebAMask-HQ dataset domain for gaze estimation DNN training. We also show additional applications of our work, which include facial image editing and gaze redirection.
* Accepted by ETRA 2024 as Full paper, and as journal paper in Proceedings of the ACM on Computer Graphics and Interactive Techniques
FreSeg: Frenet-Frame-based Part Segmentation for 3D Curvilinear Structures
Apr 19, 2024



Part segmentation is a crucial task for 3D curvilinear structures like neuron dendrites and blood vessels, enabling the analysis of dendritic spines and aneurysms with scientific and clinical significance. However, their diversely winded morphology poses a generalization challenge to existing deep learning methods, which leads to labor-intensive manual correction. In this work, we propose FreSeg, a framework of part segmentation tasks for 3D curvilinear structures. With Frenet-Frame-based point cloud transformation, it enables the models to learn more generalizable features and have significant performance improvements on tasks involving elongated and curvy geometries. We evaluate FreSeg on 2 datasets: 1) DenSpineEM, an in-house dataset for dendritic spine segmentation, and 2) IntrA, a public 3D dataset for intracranial aneurysm segmentation. Further, we will release the DenSpineEM dataset, which includes roughly 6,000 spines from 69 dendrites from 3 public electron microscopy (EM) datasets, to foster the development of effective dendritic spine instance extraction methods and, consequently, large-scale connectivity analysis to better understand mammalian brains.
$R^2$-Tuning: Efficient Image-to-Video Transfer Learning for Video Temporal Grounding
Mar 31, 2024Video temporal grounding (VTG) is a fine-grained video understanding problem that aims to ground relevant clips in untrimmed videos given natural language queries. Most existing VTG models are built upon frame-wise final-layer CLIP features, aided by additional temporal backbones (e.g., SlowFast) with sophisticated temporal reasoning mechanisms. In this work, we claim that CLIP itself already shows great potential for fine-grained spatial-temporal modeling, as each layer offers distinct yet useful information under different granularity levels. Motivated by this, we propose Reversed Recurrent Tuning ($R^2$-Tuning), a parameter- and memory-efficient transfer learning framework for video temporal grounding. Our method learns a lightweight $R^2$ Block containing only 1.5% of the total parameters to perform progressive spatial-temporal modeling. Starting from the last layer of CLIP, $R^2$ Block recurrently aggregates spatial features from earlier layers, then refines temporal correlation conditioning on the given query, resulting in a coarse-to-fine scheme. $R^2$-Tuning achieves state-of-the-art performance across three VTG tasks (i.e., moment retrieval, highlight detection, and video summarization) on six public benchmarks (i.e., QVHighlights, Charades-STA, Ego4D-NLQ, TACoS, YouTube Highlights, and TVSum) even without the additional backbone, demonstrating the significance and effectiveness of the proposed scheme. Our code is available at https://github.com/yeliudev/R2-Tuning.
OccTransformer: Improving BEVFormer for 3D camera-only occupancy prediction
Feb 28, 2024
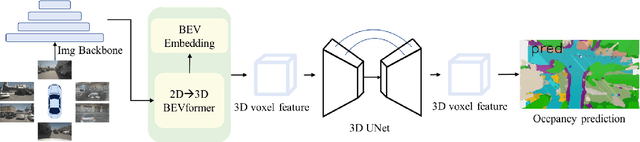

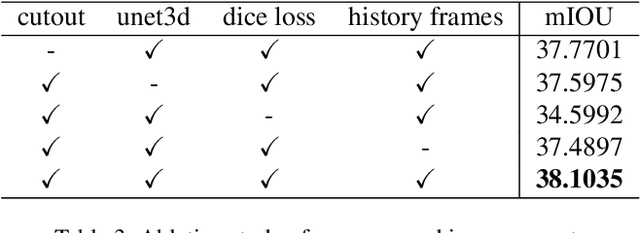
This technical report presents our solution, "occTransformer" for the 3D occupancy prediction track in the autonomous driving challenge at CVPR 2023. Our method builds upon the strong baseline BEVFormer and improves its performance through several simple yet effective techniques. Firstly, we employed data augmentation to increase the diversity of the training data and improve the model's generalization ability. Secondly, we used a strong image backbone to extract more informative features from the input data. Thirdly, we incorporated a 3D unet head to better capture the spatial information of the scene. Fourthly, we added more loss functions to better optimize the model. Additionally, we used an ensemble approach with the occ model BevDet and SurroundOcc to further improve the performance. Most importantly, we integrated 3D detection model StreamPETR to enhance the model's ability to detect objects in the scene. Using these methods, our solution achieved 49.23 miou on the 3D occupancy prediction track in the autonomous driving challenge.
Learning Domain-Invariant Temporal Dynamics for Few-Shot Action Recognition
Feb 20, 2024
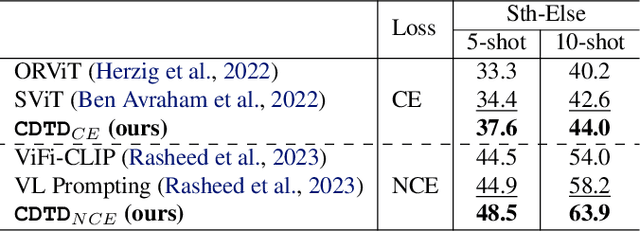
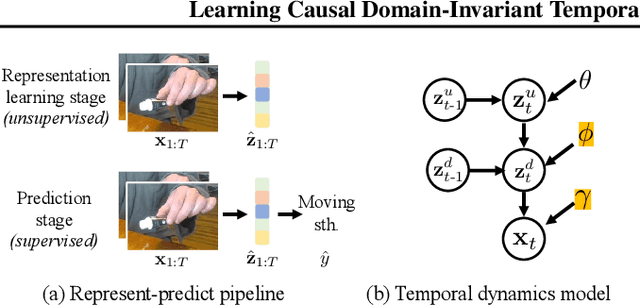

Few-shot action recognition aims at quickly adapting a pre-trained model to the novel data with a distribution shift using only a limited number of samples. Key challenges include how to identify and leverage the transferable knowledge learned by the pre-trained model. Our central hypothesis is that temporal invariance in the dynamic system between latent variables lends itself to transferability (domain-invariance). We therefore propose DITeD, or Domain-Invariant Temporal Dynamics for knowledge transfer. To detect the temporal invariance part, we propose a generative framework with a two-stage training strategy during pre-training. Specifically, we explicitly model invariant dynamics including temporal dynamic generation and transitions, and the variant visual and domain encoders. Then we pre-train the model with the self-supervised signals to learn the representation. After that, we fix the whole representation model and tune the classifier. During adaptation, we fix the transferable temporal dynamics and update the image encoder. The efficacy of our approach is revealed by the superior accuracy of DITeD over leading alternatives across standard few-shot action recognition datasets. Moreover, we validate that the learned temporal dynamic transition and temporal dynamic generation modules possess transferable qualities.
Deep Rib Fracture Instance Segmentation and Classification from CT on the RibFrac Challenge
Feb 14, 2024Rib fractures are a common and potentially severe injury that can be challenging and labor-intensive to detect in CT scans. While there have been efforts to address this field, the lack of large-scale annotated datasets and evaluation benchmarks has hindered the development and validation of deep learning algorithms. To address this issue, the RibFrac Challenge was introduced, providing a benchmark dataset of over 5,000 rib fractures from 660 CT scans, with voxel-level instance mask annotations and diagnosis labels for four clinical categories (buckle, nondisplaced, displaced, or segmental). The challenge includes two tracks: a detection (instance segmentation) track evaluated by an FROC-style metric and a classification track evaluated by an F1-style metric. During the MICCAI 2020 challenge period, 243 results were evaluated, and seven teams were invited to participate in the challenge summary. The analysis revealed that several top rib fracture detection solutions achieved performance comparable or even better than human experts. Nevertheless, the current rib fracture classification solutions are hardly clinically applicable, which can be an interesting area in the future. As an active benchmark and research resource, the data and online evaluation of the RibFrac Challenge are available at the challenge website. As an independent contribution, we have also extended our previous internal baseline by incorporating recent advancements in large-scale pretrained networks and point-based rib segmentation techniques. The resulting FracNet+ demonstrates competitive performance in rib fracture detection, which lays a foundation for further research and development in AI-assisted rib fracture detection and diagnosis.
TriSAM: Tri-Plane SAM for zero-shot cortical blood vessel segmentation in VEM images
Jan 25, 2024


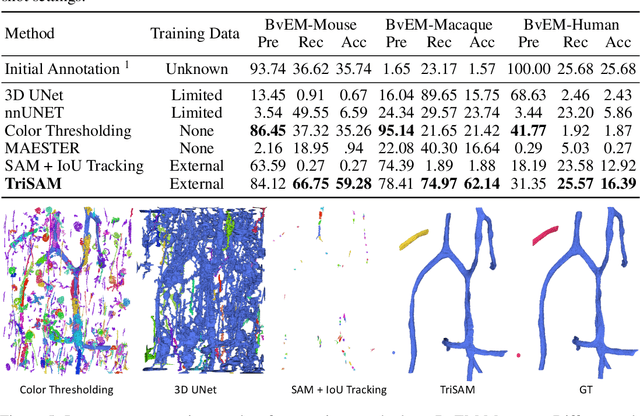
In this paper, we address a significant gap in the field of neuroimaging by introducing the largest-to-date public benchmark, BvEM, designed specifically for cortical blood vessel segmentation in Volume Electron Microscopy (VEM) images. The intricate relationship between cerebral blood vessels and neural function underscores the vital role of vascular analysis in understanding brain health. While imaging techniques at macro and mesoscales have garnered substantial attention and resources, the microscale VEM imaging, capable of revealing intricate vascular details, has lacked the necessary benchmarking infrastructure. As researchers delve deeper into the microscale intricacies of cerebral vasculature, our BvEM benchmark represents a critical step toward unraveling the mysteries of neurovascular coupling and its impact on brain function and pathology. The BvEM dataset is based on VEM image volumes from three mammal species: adult mouse, macaque, and human. We standardized the resolution, addressed imaging variations, and meticulously annotated blood vessels through semi-automatic, manual, and quality control processes, ensuring high-quality 3D segmentation. Furthermore, we developed a zero-shot cortical blood vessel segmentation method named TriSAM, which leverages the powerful segmentation model SAM for 3D segmentation. To lift SAM from 2D segmentation to 3D volume segmentation, TriSAM employs a multi-seed tracking framework, leveraging the reliability of certain image planes for tracking while using others to identify potential turning points. This approach, consisting of Tri-Plane selection, SAM-based tracking, and recursive redirection, effectively achieves long-term 3D blood vessel segmentation without model training or fine-tuning. Experimental results show that TriSAM achieved superior performances on the BvEM benchmark across three species.